「自己架一台跑 AI 的伺服器,不是更省錢又更安全嗎?」
這大概是過去一年技術社群裡最常被丟出來的問題之一。聽起來很合理:把模型拉回自己機器上跑,資料不出門、不用每個月被 API 帳單追著跑,聽起來簡直雙贏。於是有人興沖沖買了張顯卡,裝好 Ollama,跑了第一個 7B 模型,然後才發現落差沒那麼小——依開源社群基準與公開評測,這個等級的本地模型在速度與輸出品質上,跟雲端旗艦確實還有一段距離。
這就是最大的誤解:很多人以為「本地 vs 雲端」是一個非黑即白的選擇題,誰勝誰負有標準答案。但真相是,這從來不是二選一,而是一個隱私、成本、性能三方拉扯的權衡(trade-off)。你在某個維度拿到的好處,幾乎一定要在另一個維度付出代價。
這篇就用整理自官方文件、開源社群基準與公開評測的角度,把這個三角關係拆開講清楚;文中會提到的 Ollama 與 LM Studio,本篇也沒有實際安裝或跑測過,相關敘述一律不是親測結論,最後給你一套依「企業規模 × 應用場景」的選型框架。看完你大概就不會再被「自己架更省」這種直覺帶著走了。
目錄
先破解三個最常見的迷思
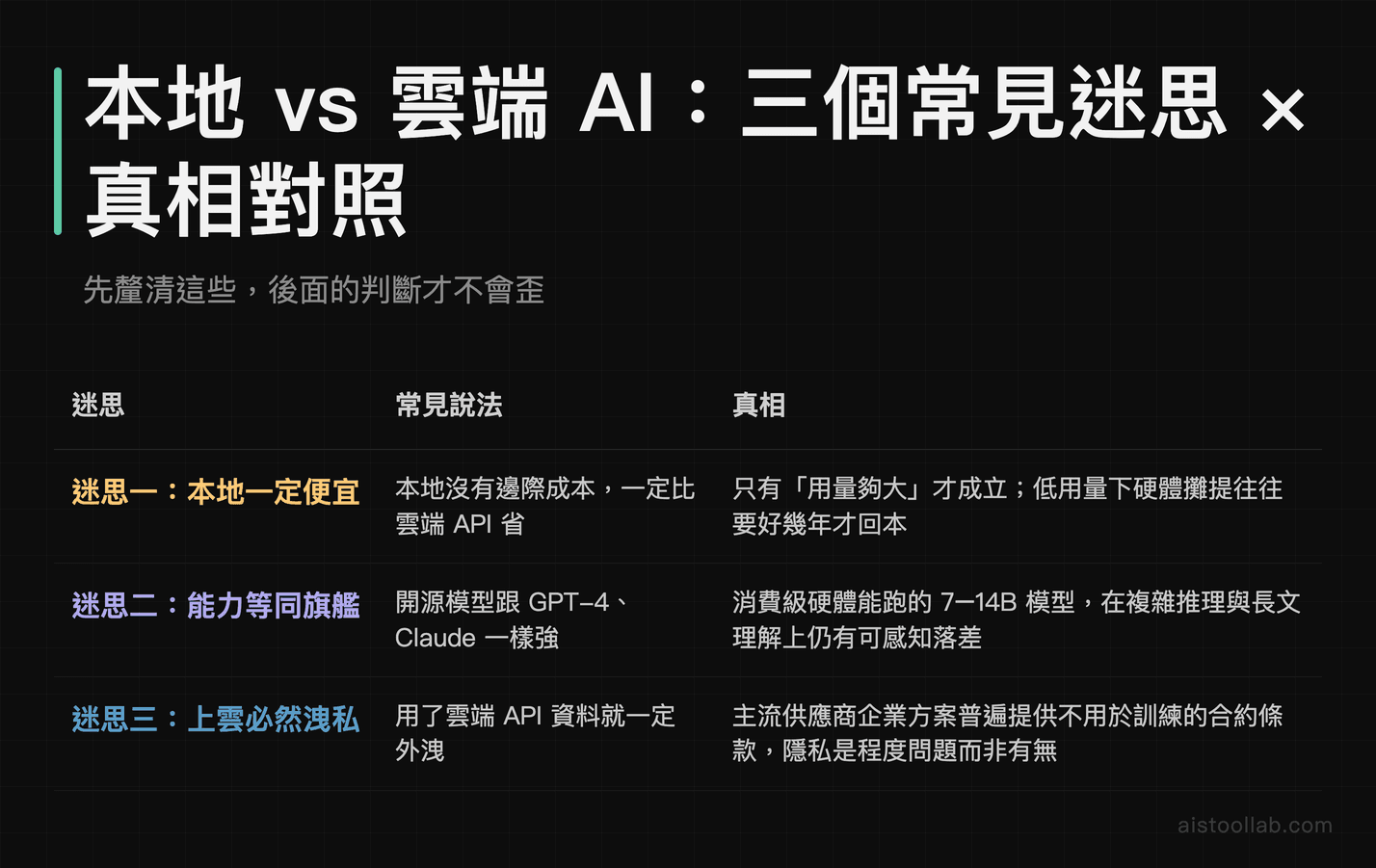
在進入正題前,得先把幾個被講到爛、但其實不太準確的說法處理掉,不然後面的判斷全會歪掉。
迷思一:本地部署一定比較便宜
這句話只在「用量夠大」的前提下成立。本地部署的成本結構是「高固定成本、低邊際成本」——你得先砸一筆硬體錢(GPU、記憶體、電源、機殼),之後每跑一次推理只付電費。而雲端 API 是「零固定成本、線性邊際成本」——不用前期投資,但每一個 token 都在計費。如果你一個月只處理幾十萬 token,攤提下來本地那張顯卡可能要好幾年才回本;但如果你每天跑數百萬 token,API 帳單就會像滾雪球。所以「誰便宜」的答案是「看你用多兇」,沒有絕對。
迷思二:本地模型跟 GPT-4、Claude 一樣強
老實說,這是落差最大的地方。能在一張消費級顯卡上跑得動的開源模型(7B、8B、甚至 14B 參數級別),在複雜推理、長文理解、程式生成的綜合表現上,跟頂級閉源旗艦模型仍有可感知的差距。你要跑到接近旗艦水準的開源模型(70B 以上參數),需要的硬體規格已經不是一般人桌機扛得住的等級。能力與硬體成本是綁在一起的,這點千萬別有幻想。
迷思三:用了雲端 API 隱私就一定外洩
這也言過其實。主流 API 供應商在企業方案中,普遍提供「不將你的資料用於訓練」的合約條款,部分還有資料保留期限控制、區域部署選項。隱私風險是「程度」問題,不是「有無」問題。真正必須本地化的,是那些受法規強約束、資料絕對不能離開特定環境的場景,而不是所有資料都得鎖在自家機房。
核心原理:為什麼這三件事必然互相拉扯

要理解這個三角,得先知道大型語言模型的「推理(inference)」到底吃什麼資源。模型的能力大致跟參數量正相關,而參數量直接決定了你需要多少 VRAM(顯示記憶體)來把模型載入、以及多少算力來計算每個 token。一個未量化的 7B 模型大約需要 14GB 以上的記憶體空間,70B 等級的模型則是好幾倍跳上去。
這就解釋了三角關係:你想要性能(更大、更聰明的模型),就得有更貴的硬體;你想要隱私(資料不出門),就得自己扛硬體與維運;你想省成本,要嘛犧牲性能用小模型、要嘛把運算丟給雲端但放棄一部分資料控制權。三個角很難同時顧滿,通常得在其中一個上讓步。
AI 推理模型的工作原理這類進階推理模型的興起讓情況更明顯——推理模型會「想很久」、產生大量中間思考 token,這在 API 上意味著帳單放大,在本地則意味著你得有夠快的硬體才不會等到天荒地老。三角的張力,在 2026 年只會更尖銳。
把開源工具的部署門檻講白

現在常見的本地部署入口,大致是 Ollama 跟 LM Studio 這兩套。它們把「下載模型、量化、跑起來」這件原本很硬核的事,包成幾乎一鍵完成的體驗,這是過去兩年本地 AI 真正普及的關鍵。
依 Ollama 官方文件,它走的是命令列/開發者路線,一行 ollama run llama3 就能把模型拉下來跑,還內建相容 OpenAI 格式的本地 API,方便你把現有用雲端 API 寫的程式直接指向本地;我認為這種設計很適合整合進自動化流程。LM Studio 依官方文件則是圖形介面取向,內建模型瀏覽、參數調整、聊天介面;不想碰終端機的話,我會優先考慮這一類,也適合先用來探索「我的機器到底跑得動哪些模型」。
但門檻不在「裝起來」,而在「跑得好」。依開源社群基準與公開評測,同一個模型在 Apple Silicon 的 Mac(統一記憶體架構,CPU/GPU 共用記憶體)與搭載獨立 NVIDIA 顯卡的 Windows 上,效能表現會因硬體架構與設定而有明顯差異。量化等級(Q4、Q5、Q8)也會直接影響速度與品質的取捨——量化越狠,記憶體佔用越小、速度越快,但模型會變笨一點。這些細節沒人幫你調好,你得自己試。這就是本地部署真正的隱性成本:你的時間。
全生命週期成本:別只看顯卡標價
講成本最容易犯的錯,就是只比「一張顯卡的錢」跟「一個月的 API 費」。真正該算的是全生命週期(Total Cost of Ownership)。本地部署的成本至少包含四塊:硬體攤提(GPU、主機、升級換代)、電力(推理時 GPU 滿載功耗不低,加上散熱)、維運(系統更新、模型管理、故障排除的人力時間)、以及機會成本(你花在調校上的時間本來可以做別的)。
雲端 API 的成本則乾淨很多,就是 token 單價乘上用量,但要注意輸入與輸出 token 通常分開計價、且輸出較貴,推理模型的思考 token 也算錢。下面這張表把兩條路的成本與特性攤開對照,方便你抓自己落在哪一邊。
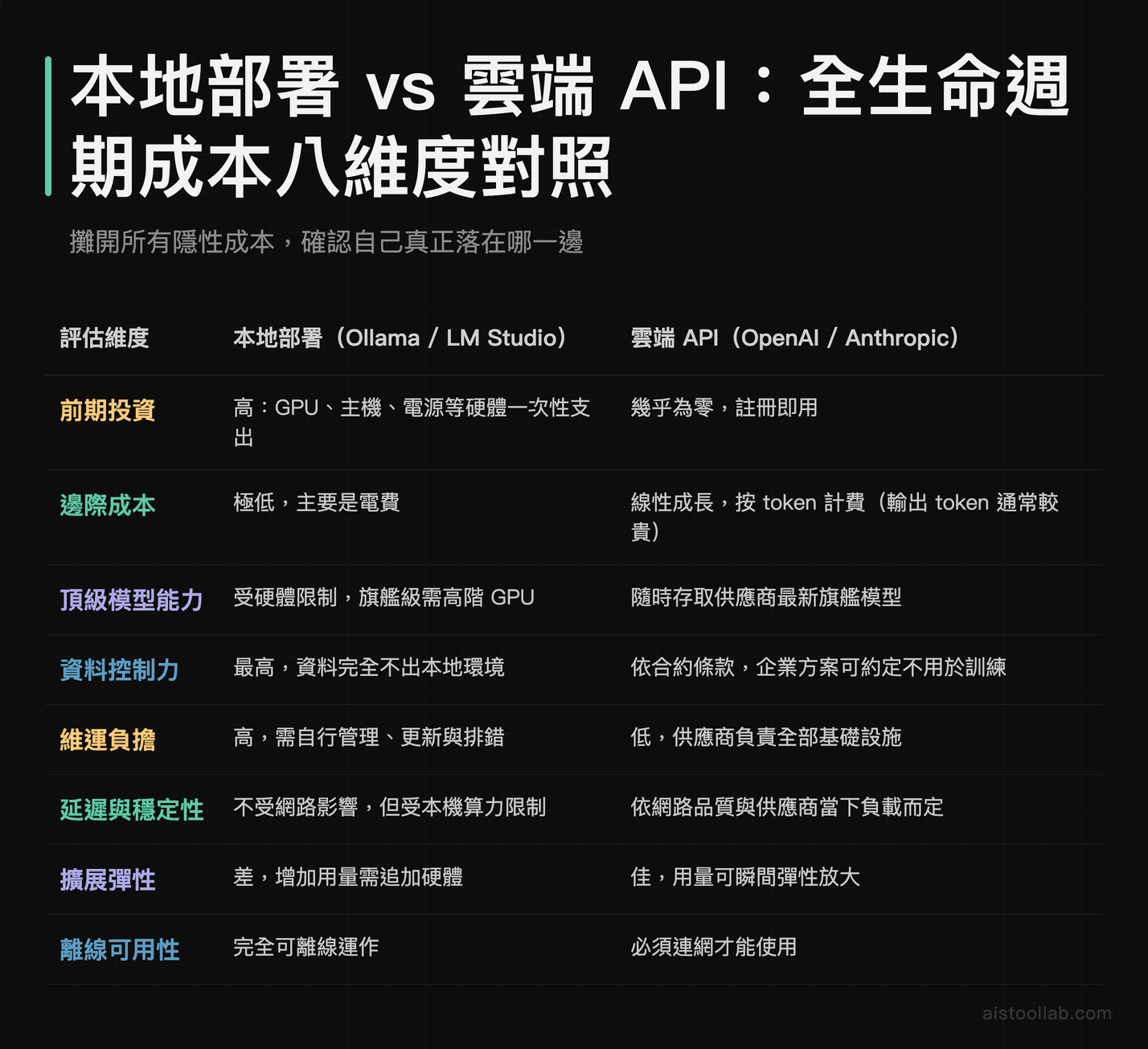
一個實用的判斷直覺:如果你的用量穩定且龐大、又有閒置硬體或人力,本地的攤提才划算;如果用量起伏大、或團隊根本沒有維運能力,API 那種「用多少付多少」反而才是真省。
隱私與資料控制力:哪些場景非本地不可

這是整個討論裡最不該用「感覺」決定的部分。資料控制需求其實是有層級的。最高層級是「法規要求資料不得離開特定環境」——例如涉及醫療病歷、金融核心交易、政府機密、或受個資法規嚴格規範的個人敏感資料。這類場景幾乎沒得選,通常得走本地或私有雲部署,因為資料一旦離開可控環境,合規責任就很難掌握。
中間層級是「商業機密但非法規強制」——像是公司內部的程式碼、未公開的產品策略、客戶名單。這類資料用 API 也不是不行,但建議走有明確合約保障(不用於訓練、可控保留期)的企業方案,並做好脫敏處理。最低層級是公開或低敏感資料,例如行銷文案、公開內容翻譯,這種用 API 的顧慮最小,追求性能與便利即可。
關鍵心法是:別把所有資料都當成最高機密來鎖。對絕大多數團隊來說,真正非本地不可的資料只佔一小部分,剩下的用 API 反而效率更高。聰明的做法往往是混合架構——敏感資料走本地小模型,一般任務走雲端旗艦。
三種典型使用情境

情境一:接案工程師想省訂閱費
假設你是獨立接案的後端工程師,平常用 AI 輔助寫程式、查文件、整理筆記,每個月雲端 API 加訂閱費是固定開銷,而手上剛好有一台記憶體夠大的 Apple Silicon MacBook。這種情況下,把日常的程式註解、簡單重構、文件摘要這類「不需要旗艦智商」的任務搬到本地 Ollama 跑是合理的——省下的訂閱費有感,資料也留在自己機器;遇到複雜架構設計、需要深度推理時再切回雲端旗艦。這就是典型的混合用法。
情境二:中小企業的客服資料處理
假設一家台灣的中小型電商想用 AI 分析客服對話、自動分類工單,而對話裡含有客戶姓名、地址、訂單資訊,屬於需要保護的個資;公司沒有大型機房,但有基本 IT 人力。比較務實的做法是:先用本地中型模型在自家環境做去識別化與初步分類,把敏感欄位剝掉後,再視需要把脫敏文本丟給雲端做更深的語意分析。這樣兼顧合規與性能。若想直接上手成品方案,也可以參考智能客服工具這類已內建資料保護機制的服務。
情境三:大企業的邊緣設備推理
製造業工廠裡的品質檢驗、或零售門市的即時影像辨識,這類場景對「延遲」與「離線可用」要求極高——網路斷了產線不能停。把輕量模型部署在邊緣設備(工廠機台、門市主機)上本地推理,在這種條件下幾乎是必然的做法,因為讓每一幀畫面都來回跑一趟雲端並不實際。這類企業AI視覺流程自動化的應用,本地化不是為了省錢,而是為了即時性與穩定性。
常見問題
我只是個人用戶,到底有沒有必要自己架本地模型?
老實說,對純個人、用量不大的使用者,多數情況沒必要。本地部署的隱性成本——硬體投資、調校時間、維運心力——往往超過你省下的那點訂閱費。除非你符合以下其中之一:你有資料絕對不能上雲的需求、你常在沒網路的環境工作、你本來就有閒置的高規格硬體、或你純粹想學習與折騰。如果只是想用 AI 寫東西、查資料,雲端服務的免費或入門方案通常更划算也更省事。建議先用 LM Studio 在自己電腦上跑一兩個小模型體驗看看,感受一下速度與品質落差,再決定要不要認真投入,不用一開始就砸錢買顯卡。
本地模型的中文能力跟雲端旗艦差很多嗎?
會有落差,但程度取決於你選的模型。早期的開源模型中文確實偏弱,常出現語感生硬、簡繁混雜的狀況。近兩年有不少針對中文強化的開源模型出現,在日常對話、摘要、翻譯這類任務上已經堪用。但在需要細膩語境理解、長文邏輯、專業領域知識的任務上,能在消費級硬體上跑的小模型跟雲端旗艦仍有可感知差距。如果你的工作對中文品質要求很高(例如正式文案、法律或醫療文本),建議重要產出還是交給雲端旗艦,本地模型負責草稿、整理這類前段工作。可以搭配AI 翻譯工具的評測一起評估你的實際需求。
跑本地模型,我的電腦規格要多好?
最關鍵的指標是記憶體(特別是 VRAM 或統一記憶體)。依開源社群基準與公開評測粗略抓:跑 7B、8B 等級的量化模型,可先以 8GB 以上可用記憶體估算;想跑 14B 等級,可先抓 16GB 以上;要碰更大的模型,記憶體需求就直線上升。Apple Silicon 的 Mac 因為 CPU/GPU 共用記憶體,在公開討論裡跑中小模型的評價不錯,是很多人入門的選擇。Windows 陣營則看你的獨立顯卡 VRAM。量化等級也能幫你「降規」——選 Q4 量化能大幅降低記憶體需求,代價是品質略降。依 LM Studio 官方文件,它會標示哪些模型你的機器跑得動;不想自己判斷硬體需求的話,我會建議用這類工具,免得下載一堆載不進去的檔案。
用雲端 API,我的公司資料真的安全嗎?
這要分開看「合約保障」與「技術風險」。主流供應商在企業方案中普遍提供「不將你的輸入用於模型訓練」的條款,部分提供資料保留期限控制與區域部署選項,這在合約層面提供了相當程度的保障。但這不等於零風險——資料畢竟離開了你的環境,傳輸與儲存過程仍存在理論上的暴露面。實務建議是:先確認你的資料屬於哪個敏感層級,受法規強約束的絕對機密走本地;一般商業機密走有明確企業合約的方案並做脫敏;公開資料則放心用。重點是讀懂你簽的條款,而不是憑感覺認定「上雲就是不安全」或「上雲就一定沒事」。
混合架構聽起來很理想,但實作會不會很複雜?
比想像中簡單,因為 Ollama 等工具提供相容 OpenAI 格式的本地 API。這代表你的程式碼幾乎不用大改,只要把 API 的指向位址在「本地」與「雲端」之間切換就行。常見做法是寫一層路由邏輯:依任務類型或資料敏感度,自動決定這個請求送本地還是送雲端。例如含個資的請求一律本地,需要高品質產出的請求送雲端。對有開發能力的團隊,這是個投資報酬率很高的架構。當然,維護兩套環境仍有額外負擔,所以比較適合用量大、又確實有混合需求的團隊。純個人用戶通常不需要搞這麼複雜,手動切換就夠了。
本地部署的電費會不會其實是隱藏地雷?
會,而且常被低估。GPU 在推理時滿載功耗不低,如果你是 24 小時開著服務、持續有請求進來,一個月累積的電費並不是零頭,加上散熱與機器其他耗電,實際數字要算進你的成本模型。對偶爾跑一下的個人用戶影響不大,但對想用本地架設常駐服務的小團隊,這筆錢必須納入全生命週期成本比較,否則你以為省了 API 費,結果電費跟硬體攤提加起來不見得比較划算。台灣的電價結構也要留意,用電量大可能跳到較高費率級距。建議先估算你的實際使用模式——是常駐還是偶發——再決定本地是否真的省。
開源模型有沒有授權上的坑,商用要注意什麼?
有,這是企業最容易忽略的法律風險。不同開源模型的授權條款差異很大:有些是完全寬鬆的商用友善授權,有些則對商業使用、用戶規模、或衍生模型有附加限制。在把某個開源模型用於商業產品前,務必看清楚它的授權文件,特別是涉及大規模商用、或要拿去做二次開發訓練的情況。別假設「開源就等於可以隨便商用」。如果不確定,找法務確認,或選擇授權條款明確寬鬆的模型。這部分沒有捷徑,授權踩雷的代價可能遠超過你省下的成本,務必當成選型的硬指標之一,而不是事後才補。
2026 年了,本地小模型有機會追上雲端旗艦嗎?
趨勢是差距在縮小,但「追上」要看你比的是什麼。小模型透過更好的訓練方法、資料品質提升、以及針對特定任務的微調,在「特定領域、特定任務」上確實可以做到接近甚至超越通用旗艦的表現——例如某個專門做程式或專門做翻譯的微調小模型。但在「通用全能」這個維度上,受限於參數量與硬體,能在消費級設備跑的小模型短期內仍難以全面追平頂級旗艦。我的判斷是:與其期待小模型「全面追上」,不如思考「我的任務需不需要全能旗艦」。很多實際應用根本用不到旗艦的全部能力,一個夠用的本地模型就能搞定,這才是真正務實的方向。
所以,到底該怎麼選?

把整個三角收斂成一句決策心法:先確認你的資料敏感層級,再看你的用量規模,最後才看預算。
如果你是初創團隊或個人,資料沒有強合規需求、用量起伏不定——直接用雲端 API,別浪費時間和錢架本地,把資源放在做產品上。如果你是中小企業,有部分敏感資料但沒有大型機房——走混合架構,敏感資料本地脫敏、一般任務上雲。如果你是大企業或有強合規需求——本地或私有雲是基本盤,但也別排斥在非敏感場景用 API 補足性能。如果你做的是邊緣設備、即時推理——本地化不是選項而是必須,延遲與離線可用性才是命脈。
這個題目沒有「哪個比較好」的標準答案,只有「哪個比較適合你現在的處境」。但如果要我給一句真心話:絕大多數人高估了自己的隱私需求、低估了本地部署的隱性成本。先用免費的 LM Studio 在自己電腦上跑一輪,親身感受一下速度與品質的真實落差,你對這整個三角的判斷會清晰非常多——這比讀十篇規格表都有用。
最後更新:2026 年
喜歡這篇評測?
👉 瀏覽 AI 工具庫,找到最適合你工作流程的 AI 工具。
延伸閱讀:2026 AI 模型定價大解析:為什麼有的 AI 貴 100 倍,卻不一定好 100 倍
延伸閱讀:AI 成本控制完全指南:Token 計算、模型選擇與企業預算優化