先破一個迷思:那些「AI 偵測器」真的看得出來嗎?
老實說,網路上每隔一陣子就會出現這種抱怨:「我把自己手寫的文章丟進某 AI 偵測器,結果它說我有 90% 機率是 AI 寫的,是不是被冤枉了?」然後底下一排人附和,最後得出一個結論——「這種偵測器根本是亂猜的」。
這個結論一半對、一半錯。錯的部分是:AI 內容偵測背後是有扎實統計學與訊號處理原理的,不是擲骰子。對的部分是:這些原理本身就有先天限制,誤判(把人寫的判成 AI、把 AI 寫的放過去)確實會發生,而且機率高到你不能完全信任任何單一工具的結論。
2026 年的此刻,AI 生成內容已經滲透到求職信、學生報告、新聞稿、Podcast、甚至偽造的客服語音裡。理解「偵測技術到底在看什麼」,不只是學術好奇,而是你判斷一份內容能不能信、一個結果該不該採用的基本能力。這篇就把文本、圖像、語音三條戰線的科學原理講清楚,再誠實聊聊它們為什麼註定追不上生成技術。
目錄
文本檢測:困惑度與「爆發性」在抓什麼

先講最成熟、爭議也最大的文本偵測。它的核心其實只有兩個統計概念,理解了就不會再被工具的「百分比」嚇到。
第一個是困惑度(Perplexity)。簡單講,它衡量的是「一段文字對某個語言模型來說有多意外」。語言模型本質上是在預測下一個字,當一段文字的用詞都剛好落在模型「最可能選的選項」裡,困惑度就低;當文字出現模型覺得很跳、很意外的用法,困惑度就高。問題來了:AI 生成的內容,正是模型自己挑「最可能的字」串起來的,所以它天生困惑度偏低、偏平順。人類寫作則常常會有怪癖、口語、突然岔題,困惑度自然較高。
第二個是爆發性 / 困惑比率(Burstiness)。人類寫東西的節奏是不平均的——這句很長很繞,下一句可能就三個字。AI 生成的文字則傾向句長均勻、結構工整,像被熨斗燙過。偵測器把「句子之間困惑度的變異程度」量化出來,變異小的就更像機器。GPTZero 早期之所以爆紅,靠的就是把這兩個指標可視化呈現給老師看。
但你應該已經嗅到問題了:這些都是統計傾向,不是鐵證。一個母語非英文、寫得很工整的學生,文字困惑度本來就低,於是經常被誤判成 AI。反過來,只要叫 AI「寫得隨性一點、加點口語、故意拉長短句交錯」,burstiness 就上去了,偵測器立刻失靈。這也是為什麼那些「AI 改寫成人類腔」的工具能輕鬆繞過大多數偵測。本站先前在介紹AI 推理模型的工作原理時也提過,新一代模型輸出越來越擬人,這對偵測端是純粹的壞消息。
圖像檢測:從頻域裡的指紋,到「以模型抓模型」

圖像這條線比文字更技術一點,但概念同樣可以拆開看。早期的 AI 圖像偵測主要靠頻域分析。GAN 與擴散模型在生成圖片時,會在高頻區域留下肉眼看不見、但傅立葉轉換後會現形的規律性紋路——有人形容那像是「生成模型的指紋」。把圖片轉到頻域,這些週期性的格狀痕跡就會跳出來,與真實相機拍攝、感光元件雜訊分布完全不同。
不過擴散模型(Diffusion)崛起後,頻域指紋變得越來越淡,純靠頻譜已經不太夠用。所以近年研究轉向「以生成式模型反過來檢測生成內容」:訓練一個分類器去學習各種生成模型的統計特徵,甚至利用「重建誤差」——把一張圖丟回擴散模型去重建,如果它能被輕鬆、低誤差地重建,往往代表它本來就出自類似模型。此外還有元數據與物理一致性檢查,例如光影方向、反射、手指數量、文字邊緣這些 AI 容易露餡的地方。
產業端則走另一條路:內容憑證(Content Credentials / C2PA)。與其事後偵測,不如在生成或拍攝當下就把來源資訊用密碼學簽進檔案。Adobe、相機廠與部分模型業者都在推這套標準。理論上很漂亮,但只要圖片被截圖、重新壓縮或上傳到會剝掉元數據的平台,憑證就掉了。所以偵測與溯源目前是兩條並行、互補但都不完整的路。
語音檢測:合成聲音藏不住的頻譜破綻

語音偽造(voice cloning)是 2026 年詐騙最讓人頭痛的一環,因為現在複製一個人的聲音只需要幾秒樣本。偵測合成語音主要看三類線索。
其一是聲紋與發聲機制的物理異常。真人發聲是由聲帶、口腔、鼻腔共同作用,會產生自然的微顫(jitter、shimmer)與呼吸雜訊;合成語音這些生理細節往往過於乾淨或規律。其二是頻譜特徵,尤其是高頻段與相位資訊——許多 vocoder 在重建波形時會在特定頻段留下不自然的能量分布或相位不連續,這在語譜圖(spectrogram)上能被分類器學出來。其三是韻律與時間結構,合成語音的停頓、語速變化有時過於平滑或機械。
這領域有公開的研究基準(例如長期舉辦的 ASVspoof 系列挑戰賽),讓各家方法在同一套資料上比拚。但同樣的故事再次上演:偵測模型在「看過的偽造類型」上表現不錯,遇到全新的生成架構就掉漆,這叫做泛化能力不足,是所有偵測技術共同的阿基里斯腱。
主流偵測工具實測對比(整理自官方說明與公開評測)
下面這張表,是我綜合各工具官方文件與第三方公開評測整理的概況。先講重要前提:各家宣稱的準確率與獨立評測落差很大,且高度取決於測試文本來源、語言、是否經過改寫。請把它當成「特性比較」而非「精確戰力排名」。
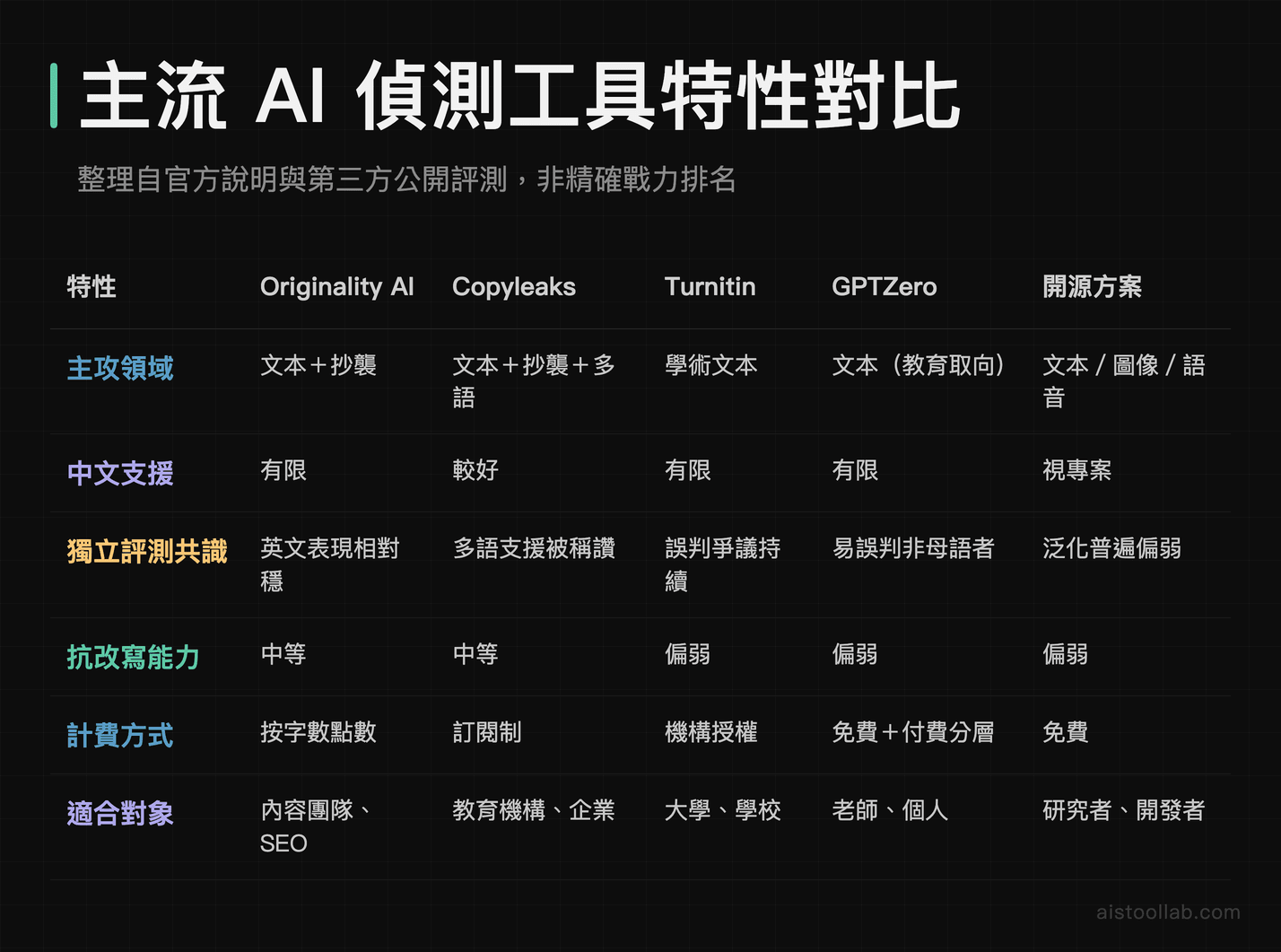
我必須誠實說:表格裡「官方宣稱準確率」我刻意沒填具體數字。原因是這些數字在不同獨立測試下差異極大,把它寫死反而誤導你。一個普遍的共識是——在「未經改寫的純 AI 文本」上,多數工具表現尚可;一旦內容經過人工潤飾或 AI 改寫,準確率會明顯下滑。Turnitin 與 GPTZero 都曾因把人類寫作誤判為 AI 而引發學界批評,這也是為什麼越來越多學校不再把偵測結果當成唯一懲處依據。
誰真的需要這些技術?三個日常情境

情境一:大學助教批改期末報告
不少系所的助教,這兩年最痛苦的就是「一眼看不出來這份報告是不是 AI 代寫」。偵測工具確實能提供一個參考分數,但更務實的做法是把它當成「篩選紅旗」而非「判決書」——分數異常時找學生來口頭問答,遠比直接拿百分比扣分公平。畢竟把認真的非母語寫作學生誤判,後果比放過一個作弊的更嚴重。
情境二:內容行銷團隊把關外包稿件
小型行銷公司常把部落格文章外包,最怕收到「整篇 ChatGPT 直出、連事實都懶得查」的稿。這時偵測工具加上抄襲檢查(像 Originality AI、Copyleaks 同時提供兩者)能快速過濾掉最敷衍的那批。但別忘了,會用 AI 不等於品質差,重點還是回到內容本身有沒有觀點、有沒有查證,這跟之前聊AI 翻譯工具時的結論一樣:工具是輔助,判斷力才是核心。
情境三:企業防範語音詐騙與假新聞
銀行、客服中心開始面對「複製主管聲音要求轉帳」的攻擊。語音偵測在這裡的價值不是百分百攔截,而是在可疑通話中觸發二次驗證流程。同理,媒體與公關處理可疑影像時,會用偵測工具搭配內容憑證查核,再加上人工判斷——任何單一環節都不足以下定論。
軍備競賽:為什麼偵測註定是追趕的一方

這是整篇最該記住的一段。AI 偵測本質上是一場不對稱的軍備競賽,而且結構上對偵測方不利。原因有三。
第一,生成模型可以直接拿偵測器來訓練自己。只要把偵測器當成對手,生成端就能學著繞過它,這在機器學習裡叫對抗式訓練。偵測器是公開的、可被研究的,等於把考古題交給對手。
第二,偵測靠的是「過去模型的統計特徵」,但模型一直在變。今天訓練好的偵測器,面對明天發布的新模型,泛化能力往往大打折扣。這就是為什麼你會發現某個工具「半年前很準、現在常常失靈」。
第三,人機混合內容讓界線徹底模糊。現實中大量內容是「人用 AI 起草、再自己改寫」,請問這算 AI 還是人寫?偵測器面對的根本不是非黑即白的問題。學界因此有個越來越主流的觀點:與其押注在「事後偵測」,不如投資「源頭溯源」(內容憑證、數位浮水印)。但浮水印也有它的脆弱性——容易在轉檔、改寫中被洗掉,且需要全產業配合才有意義。坦白說,目前沒有任何一條路是完整解答。
常見問題
AI 偵測器的結果可以當成作弊的證據嗎?
不建議單獨採信。目前主流共識是,偵測結果只能當作「需要進一步查核的訊號」,不能當成唯一判決依據。連 Turnitin、GPTZero 等業者自己的說明文件,都會提醒結果存在誤判可能,尤其對非母語寫作者、格式工整的學術文體特別容易誤殺。實務上比較負責任的做法,是把高分案例拿來做人工複核或口頭問答,再交叉比對寫作過程紀錄(例如雲端文件的編輯歷史)。把一個百分比直接拿來定人罪,無論在教育還是職場,風險都太高,也可能引發爭議與申訴。
我自己寫的文章被判成 AI,該怎麼自保?
先別慌,這是已知的系統性問題,不代表你寫得「像機器」就有錯。我會建議的自保方式是保留寫作過程證據:用 Google Docs 或 Word 線上版寫作,編輯歷史會完整記錄你逐步打字、修改、刪減的過程,這是直接貼上 AI 產出的人通常拿不出來的。其次,被質疑時主動提出口頭說明,解釋你的論點來源與思路。如果是學校場景,可以引用業界普遍承認偵測器會誤判非母語者這一點來申訴。記住,舉證責任不該全壓在被指控的一方,要求對方提出偵測以外的佐證是合理的。
把 AI 文章改寫一下,就一定能躲過偵測嗎?
多數情況下,適度的人工改寫確實能大幅降低被偵測出來的機率,因為改寫會破壞 AI 生成文本那種「困惑度低、句長均勻」的統計特徵。但這裡有兩個重點:一是這場貓抓老鼠永遠在變動,今天有效的改寫手法,偵測器更新後不保證持續有效;二是更該問的是「為什麼要躲」。如果是學術或新聞,重點本來就不該是躲偵測,而是內容有沒有經過你自己的思考與查證。把心力花在繞過工具上,不如花在讓內容真的有價值,後者的好處是:就算被偵測器誤判,你也拿得出思考與查證的過程去說明。
圖像偵測能 100% 抓出 AI 生成圖嗎?
不能,而且差得遠。早期靠頻域指紋的方法,在擴散模型時代效果已明顯下降;新一代的重建誤差法、分類器法在「看過的生成類型」上表現較好,但遇到全新模型容易失準。更麻煩的是,只要圖片經過截圖、壓縮、二次編輯,許多偵測線索就被破壞了。目前業界比較看好的方向其實是「內容憑證」這類源頭溯源標準,在生成當下就簽入來源資訊,但它同樣怕轉檔剝除元數據。結論是:圖像真偽判斷現在仍需要偵測工具、元數據檢查、人工常識(看手指、光影、文字)三者並用,沒有單一銀彈。
語音複製詐騙這麼可怕,偵測技術擋得住嗎?
偵測技術有幫助,但別期待它能完全擋住。合成語音偵測主要看發聲的生理細節、頻譜與相位異常、韻律是否過於平滑,在公開基準(如 ASVspoof)上各家方法持續進步。問題在於泛化——偵測器對沒見過的新合成架構往往招架不住,而詐騙集團用的工具天天在換。所以更實際的防線是流程設計:接到「主管要求緊急轉帳」這類電話時,一律改用其他管道二次確認、設定通關密語、對大額交易強制人工複核。技術偵測是輔助,制度與警覺心才是主防線,這點對華語圈的中小企業尤其重要。
Originality AI 和 Copyleaks 哪個比較適合華語圈用戶?
看你的內容語言和用途。如果主要處理中文與多語內容,Copyleaks 的多語支援在公開評測中口碑相對較好,也常被教育機構與企業採用,介面對非英文使用者較友善。如果你是做英文 SEO 內容、需要「AI 偵測+抄襲檢查」二合一,Originality AI 在這塊累積較多口碑,計費採點數制,量大時成本要先算清楚。兩者中文母語內容的準確度都不該被當成絕對標準。我的建議是:兩家都有試用或小額方案,先各丟同一批你熟悉真偽的稿子去測,看誤判率你能不能接受,再決定要不要付費。主流國際 Visa / Mastercard 信用卡多數可付款,記得確認所在地區是否受支援,以及月繳還是年繳划算。
免費的偵測工具和付費的差在哪?值得付費嗎?
免費工具(像 GPTZero 免費層、各種開源方案)適合偶爾查一篇、做個參考,缺點是準確率不穩、字數有上限、缺乏批次處理與報告功能。付費版的價值主要在三點:批次檢測大量文件、可匯出的正式報告(教育或企業稽核需要)、以及通常綁定抄襲檢查。如果你只是想知道「這篇大概像不像 AI」,免費的就夠了,沒必要花錢。但如果你是要對外負責的角色——助教、編輯、稽核——付費版的報告與批次功能會省下大量時間。關鍵還是那句:別把任何一家的分數當成最終真相,付費買的是效率與佐證,不是買「絕對正確」。
未來偵測技術會不會徹底失效?
「事後偵測」這條路長期會越來越吃力,這是結構性的,因為生成模型可以拿偵測器當訓練對手,而且人機混合內容讓界線本來就模糊。比較有機會的方向是「源頭溯源」——數位浮水印與內容憑證(C2PA)這類在生成當下就標記來源的做法。但它需要全產業配合,且怕轉檔、改寫破壞,短期內也成不了完整解。我的判斷是:未來不會有一個「一鍵分辨真假」的神器,而是會走向多重訊號、溯源憑證、加上人工判斷的組合拳。學會不過度依賴單一工具、保持查證習慣,才是這個時代最保值的能力。
說到底,別把「偵測分數」當成真相本身

這個題目沒有讓人安心的標準答案,但如果是我,我會這樣用:偵測工具當「紅旗偵測器」,幫我快速圈出可疑內容,但最終判斷一定回到內容本身——有沒有觀點、查證過沒有、來源能不能交叉驗證、必要時直接找人問。把一串百分比當成判決書,無論對寫作者還是對你自己,都是最危險的偷懶。
偵測與生成的軍備競賽還會打很久,而且短期內偵測方多半是追趕的一方。我還在持續觀察內容憑證標準能不能真正普及、新一代偵測模型的泛化有沒有突破,有明確進展我會回來更新。在那之前,記得一件事:能識破假內容的,從來不只是工具,更是你願不願意多查一步的那點警覺。
最後更新:2026 年
喜歡這篇評測?
👉 瀏覽 AI 工具庫,找到最適合你工作流程的 AI 工具。