Wait — Your Chatbot Isn’t an AI Agent (And the Difference Actually Matters)
Here’s a take that might ruffle some feathers: most of what gets marketed as “AI agents” today is still just a fancy chatbot with a few API calls bolted on. The word “agentic” has become so overloaded that every product with an auto-reply feature is slapping it on their homepage. But real agentic AI — the kind that can break down a three-week engineering task, recover from a failed tool call, and update its own plan mid-execution — is genuinely different from what you get when you hit Send in a chat window. The architecture, the failure modes, and the use cases are all different.
I’ve been spending a lot of time lately reading the research literature on agent systems — papers from DeepMind, Anthropic, Princeton, and Stanford — alongside public write-ups from teams deploying these systems in production. The honest picture is messier and more interesting than the marketing suggests. Agents are not magic, they’re not reliable enough for everything, and the benchmarks are more nuanced than vendor slides let on. But on specific, well-scoped tasks, they can outperform single-turn models by a wide margin.
This piece is a research-grounded breakdown of how agentic AI actually works under the hood — planning algorithms, memory architectures, decision-making loops, and where the hard limits are. No hype, no vague gestures at “autonomous AI.” Just the actual mechanics and what the published evidence says.
Contents
What Makes an Agent an Agent: Planning, Memory, and Tool Use

A standard language model interaction is a single-turn affair: you give it input, it generates output. Even multi-turn chat is essentially stateless — the model doesn’t remember in any persistent sense, it just gets the conversation pasted into its context window each time. Agents are different in three fundamental ways.
Planning and Decomposition
Agents can break a goal into sub-tasks, execute them in sequence (or in parallel), evaluate progress, and revise the plan if something fails. This is what the research community calls task decomposition and goal-directed behavior. The ReAct framework — introduced in a widely-cited arXiv paper by Yao et al. in 2023 — formalized this by interleaving “reasoning traces” (internal thought steps the model writes out) with concrete actions (web searches, code execution, API calls). The model doesn’t just answer; it thinks about what to do next, does the thing, observes the result, and iterates. That loop is the core difference from a chatbot.
Memory Architecture
Agent memory comes in at least three flavors. In-context memory is the conversation/scratchpad the model can see right now — bounded by token limits. External memory is a vector database or structured store the agent can read and write, allowing it to “remember” things across sessions. Procedural memory — more experimental — embeds learned behaviors into the model weights themselves through fine-tuning loops. Most production agents today rely heavily on external memory because it’s the most controllable; papers like the NVIDIA “Voyager” Minecraft agent (Wang et al., 2023) showed that a growing external skill library substantially improved long-horizon task performance.
Tool Use
Tool-augmented agents can call external functions: search the web, execute code, query databases, send emails, interact with GUIs. Meta AI’s Toolformer paper (Schick et al., 2023) demonstrated that models can learn when to use tools with relatively light supervision — the model doesn’t just call every tool available, it learns to recognize which tool is actually useful for a given step. In practice, this is where a lot of real-world implementations fall apart: the model calls the wrong tool, misformats the input, or loops indefinitely. Tool reliability engineering has become its own subfield.
How Agents Actually Think: Reward Modeling, MCTS, and RL in Production
Here’s where it gets genuinely interesting — and where a lot of pop-science coverage skips over the real engineering.
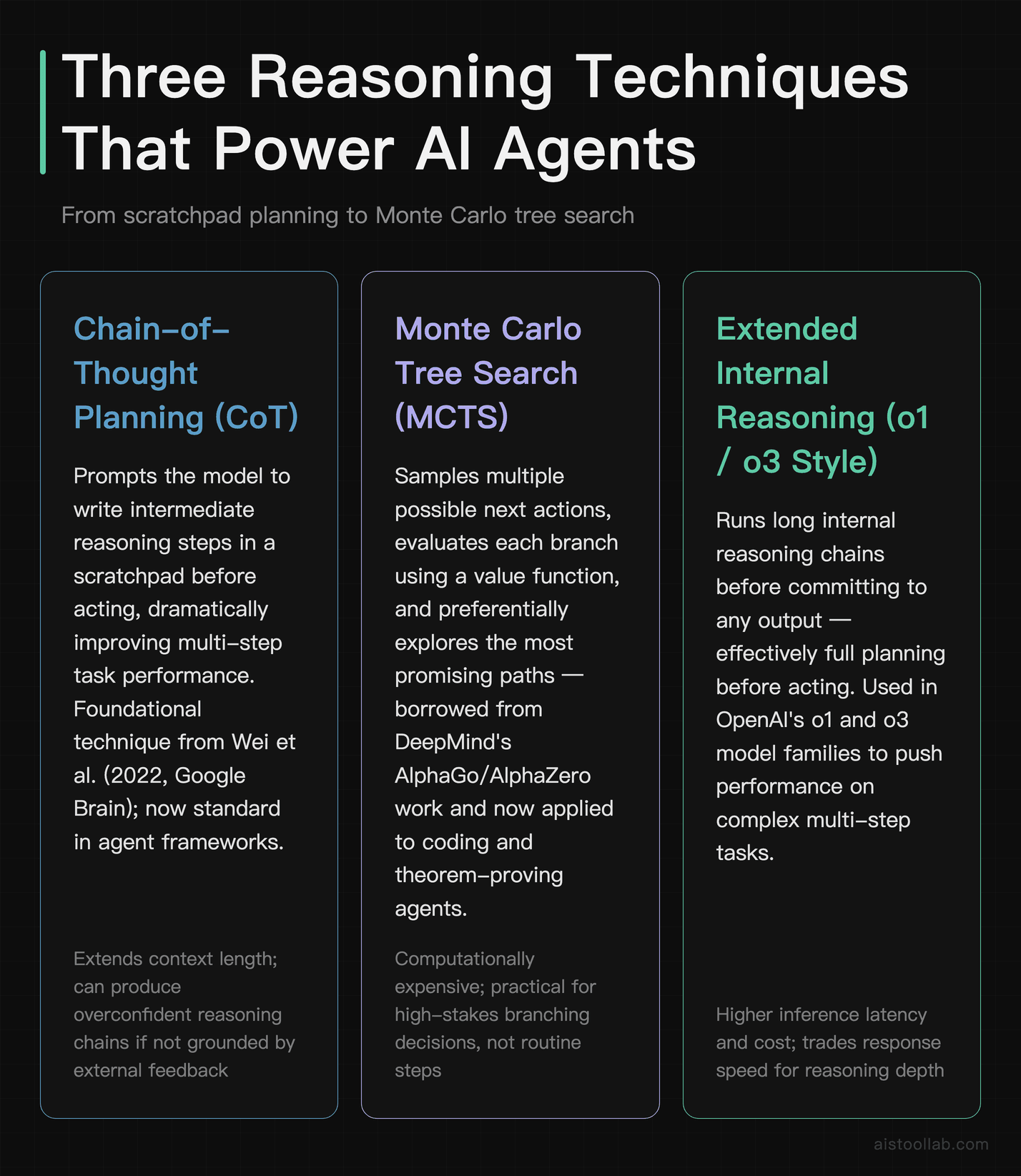
Chain-of-Thought as a Planning Primitive
The foundational technique is chain-of-thought (CoT) prompting, rigorously studied by Wei et al. (2022) at Google Brain. By prompting a model to write out intermediate reasoning steps, you improve performance on multi-step tasks. Agents extend this into full “scratchpad” planning: the model maintains an explicit working memory of what it’s tried, what worked, and what the next step should be. When OpenAI introduced its o1 and o3 model families, it described them as running extended internal reasoning chains before committing to an output — effectively doing planning before acting.
Monte Carlo Tree Search
MCTS, famous from DeepMind’s AlphaGo and AlphaZero work, is now being applied to language model agents — particularly in coding and theorem-proving tasks. The idea: instead of committing to one plan, the agent samples multiple possible next actions, evaluates each branch’s likely outcome using a value function, and preferentially explores the most promising paths. This is computationally expensive, but for high-stakes tasks where a wrong early decision compounds downstream, it can improve reliability. Research groups at MIT and Carnegie Mellon have published work applying MCTS-inspired search to code generation and multi-step reasoning.
Reinforcement Learning from Feedback
The deeper infrastructure for agentic behavior is reinforcement learning. RLHF (Reinforcement Learning from Human Feedback) is how models like Claude and GPT-4 were fine-tuned to be helpful — but more recent work extends this to actual agentic loops. Instead of rating individual responses, you reward the agent for successfully completing end-to-end tasks. This is harder to set up (you need an environment the agent can interact with, not just a static dataset) but produces agents that learn to recover from mistakes rather than just averaging over training examples. Anthropic has published research on Constitutional AI and process supervision that points in this direction.
Single-Turn Models vs. Agentic Architectures: A Direct Comparison
What the Benchmarks Actually Show

The benchmark picture is more mixed than vendors will tell you — which is actually useful information.
SWE-bench, developed by researchers at Princeton (Jimenez et al., 2023), tests whether agents can autonomously resolve real GitHub issues from open-source repositories. It’s one of the more credible agent benchmarks because it measures end-to-end task completion in a real codebase, not just question-answering. Anthropic’s public announcement of Claude 3.5 Sonnet’s performance on SWE-bench Verified placed it at approximately 49% — meaning roughly half of the sampled real software bugs could be autonomously fixed. That number sounds modest, but early baseline agentic systems on this benchmark scored well under 5% when it was first introduced. The trajectory matters. For context on how coding agents are developing in practice, I covered some of the tooling landscape in the Best GitHub Copilot Alternatives in 2026 roundup.
WebArena (Zhou et al., 2023), which tests agents navigating real websites to complete tasks, tells a more humbling story. Baseline models performed in the low-to-mid single digits percentage-wise on task completion in the original paper — and while improvements have come since, web navigation remains genuinely hard because it requires long chains of correct decisions where a single misstep cascades. The GAIA benchmark, introduced by Meta and Hugging Face to test “general AI assistant” capabilities, similarly shows that agentic systems perform well on factual lookup chains but struggle significantly with tasks requiring nuanced judgment or physical-world reasoning.
The consistent pattern across benchmarks: agents outperform single-turn models on tasks that require sequential tool use and planning, but the advantage collapses on tasks requiring genuine world knowledge synthesis or where the task description is ambiguous. Agents are not more “intelligent” — they’re better at executing defined workflows reliably.
Who Actually Uses Agentic AI: Three Real Use Cases
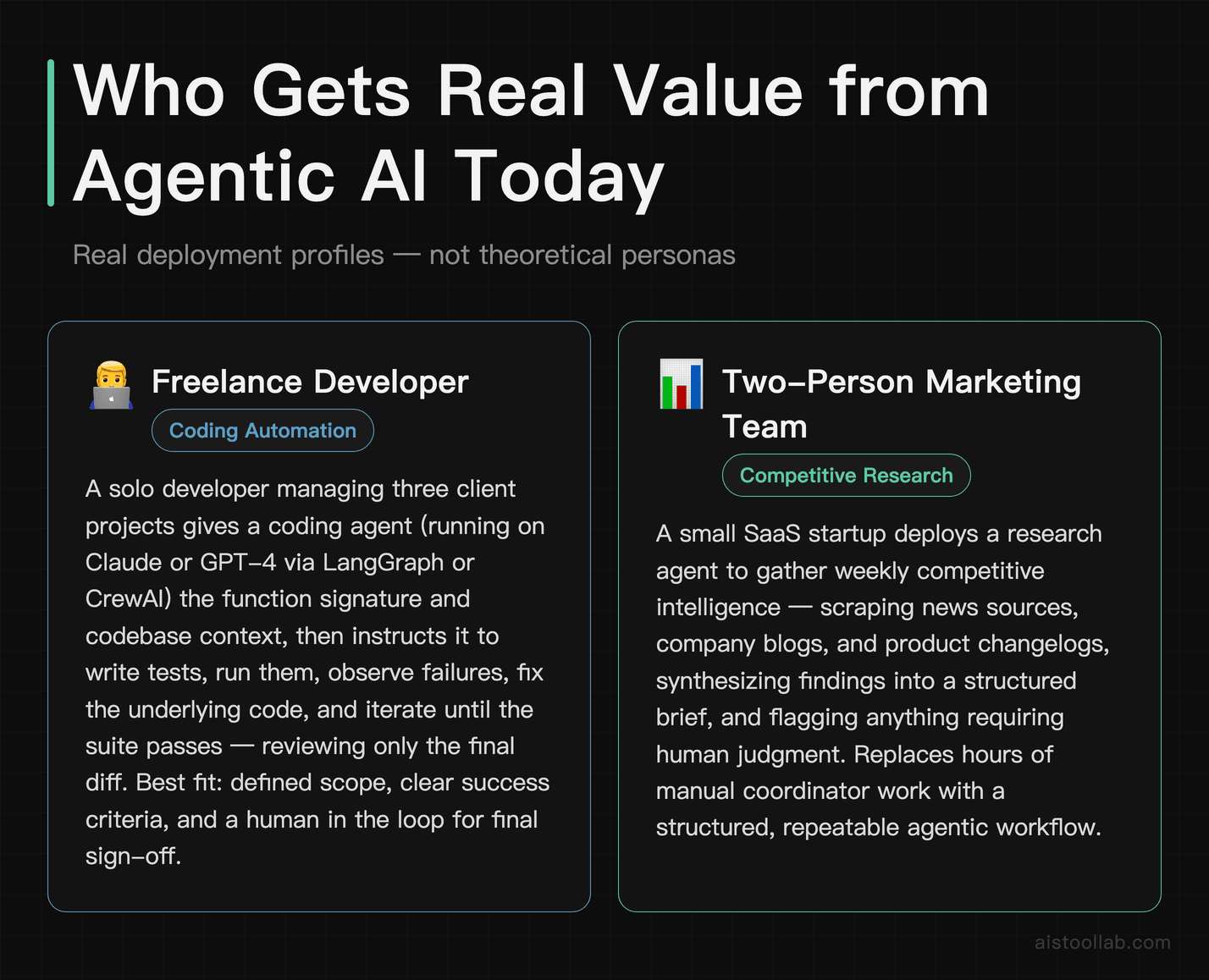
1. The Freelance Developer Offloading Boilerplate
A solo developer managing three client projects simultaneously doesn’t have time to write test suites from scratch for every new feature. A coding agent — running on a capable general-purpose model via a framework like LangGraph or CrewAI — can be given a function signature, the codebase context, and instructed to write tests, run them, observe failures, adjust the code, and iterate until the test suite passes. The developer reviews the final diff, not every intermediate step. This is the sweet spot for agents: defined scope, clear success criteria, and a human in the loop for the final sign-off. The agent doesn’t need to be perfect — it needs to reduce the tedious hours.
2. A Two-Person Marketing Team Running Competitor Research
A SaaS startup with a small marketing team needs weekly competitive intelligence: new feature announcements, pricing changes, social sentiment. A research agent can be set up to search across news sources, company blogs, and product changelog pages, synthesize findings into a structured brief, and flag anything requiring human judgment. The kind of work that used to take a marketing coordinator three hours on a Friday afternoon can run overnight. This ties directly into the broader AI toolset conversation I’ve covered in the Best AI Tools for Marketing and SEO in 2026 guide.
3. Enterprise Customer Service Operations at Scale
A mid-sized B2B SaaS company handling hundreds of support tickets daily can deploy an agent that triages incoming requests, looks up relevant documentation and past cases from an external memory store, drafts responses, escalates edge cases to human agents, and updates the CRM automatically. The agent isn’t replacing support staff — it’s handling the share of tickets that follow predictable patterns so the human team can focus on genuine edge cases. Enterprise AI search platforms like Glean are increasingly integrating agentic workflows into this kind of operational context; I took a closer look at how that plays out in the Glean AI Search Platform piece.
Enterprise Adoption in 2025–2026: What the Data Actually Says

Enterprise adoption of agentic AI has accelerated noticeably from 2024 into 2025-2026, though the picture varies considerably by industry and use case. Gartner research published in the 2025 timeframe flagged AI agents as one of the top technology trends for enterprise IT organizations. Salesforce launched Agentforce in late 2024 as a dedicated enterprise agent platform, and Microsoft’s Copilot Studio added orchestration layers for multi-step agent workflows. ServiceNow, Workday, and other enterprise software vendors have all announced agent-native product roadmaps.
Honest note: specific adoption rate percentages from recent studies in this space vary widely depending on how “AI agent” is defined by the survey — some count any automated LLM workflow, others require fully autonomous multi-step execution. The consistent signal across industry reports is that adoption is growing quickly in knowledge-work automation, but production deployments at scale are still largely concentrated in larger organizations with dedicated AI engineering teams. For small businesses, the tooling is improving rapidly, and the Best AI Tools for Small Business Owners in 2026 article covers the more accessible entry points.
Frequently Asked Questions
What’s the actual difference between an AI agent and a regular chatbot?
The functional difference is significant enough to matter for real decisions. A chatbot responds to a prompt and stops — it has no persistent goal, no ability to take actions in the world, and no mechanism for revising its approach based on feedback. An AI agent is a system that can pursue a goal across multiple steps, using tools (like web search, code execution, or API calls), maintaining state about what it’s already tried, and adjusting its plan when something doesn’t work. Think of the difference between asking a colleague “what do you think about this code?” versus asking them to “fix the bug, run the tests, and submit the pull request.” The chatbot does the first. The agent does the second. Architecturally, agents typically wrap an LLM inside a control loop that includes memory retrieval, tool execution, output parsing, and a planning/re-planning mechanism. The LLM is still the “reasoning engine,” but the surrounding system is what makes it agentic. This distinction matters when you’re deciding what to build — most business problems don’t require agents, and deploying an agent when a prompt would do just adds latency and cost.
How do AI agents use memory, and what are the limits?
Agent memory architectures are usually described in three tiers. In-context memory is the active working memory — everything in the current prompt/context window. This is fast but expensive and bounded by token limits. Modern long-context models (128K+ tokens) have pushed this window out significantly, but you still can’t put an entire company’s knowledge base in there. External memory is a vector database or structured store the agent can query — tools like Pinecone, Weaviate, or Chroma are commonly used for this. The agent embeds the query, retrieves semantically relevant documents, and injects them into context as needed. This is how most production RAG (Retrieval-Augmented Generation) systems work. Procedural or learned memory — where the agent’s behavior updates based on past task experience — is still largely experimental in most frameworks. The main limitation is retrieval quality: the agent only knows to look for something if it thinks to look. If it doesn’t formulate the right retrieval query, it might “forget” relevant information that exists in the store. This is a known failure mode in production RAG systems.
What is the ReAct framework and why does it keep coming up?
ReAct (Reasoning + Acting) is a prompting and architectural pattern introduced by Yao et al. in a 2023 arXiv paper that has become one of the most widely cited foundations for agentic systems. The core idea is to interleave explicit reasoning traces (“Thought: I need to search for the current price of X”) with concrete actions (“Action: web_search(‘X current price’)”) and observations (“Observation: The current price of X is $42”). This creates a structured loop rather than a single generation pass. The “reasoning” component is critical because it forces the model to articulate its next step before taking it — this exposes the planning to potential self-correction and makes the agent’s behavior much more debuggable. Without the reasoning trace, you just see actions and results, and when something fails you have no insight into why the agent made the choice it did. ReAct is now baked into most major agent frameworks including LangChain, LangGraph, and Microsoft’s Semantic Kernel. If you’re evaluating any agentic product, asking “does this use a ReAct-style loop or just linear tool calling?” is a useful due-diligence question.
What does Monte Carlo Tree Search have to do with AI agents?
MCTS is a search algorithm that builds a decision tree by simulating possible futures and using the outcomes to estimate which branches are worth exploring. It became famous as the core algorithm in DeepMind’s AlphaGo. In language model agents, MCTS-inspired approaches address a real problem: when an agent needs to plan a long sequence of actions, committing greedily to the first plausible plan is risky because early mistakes compound. MCTS-style search lets the agent explore multiple candidate plans in parallel, estimate their likely success (using a “value function” — often another model or a heuristic), and allocate more compute to the promising branches. Research groups have applied this to code synthesis, mathematical reasoning, and multi-step game-playing with language models, generally finding improvements on hard tasks where greedy planning fails. In production settings, pure MCTS is expensive, so most implementations use approximations — beam search over action sequences, speculative execution with rollback, or lightweight simulation models. OpenAI’s o1/o3 architecture, while not publicly described in full technical detail, has been characterized as incorporating extended internal reasoning of this nature based on published evaluations and capability profiles.
Are agentic systems actually reliable enough to trust in production?
Honestly, it depends heavily on the task. For narrowly defined, high-repeatability tasks — processing incoming documents, running predefined research queries, generating code for well-specified problems — production agents have shown reliability good enough for real deployment with appropriate human checkpoints. For open-ended tasks with ambiguous success criteria, or tasks requiring judgment about novel situations, reliability drops significantly. The benchmark data makes this concrete: coding agents on SWE-bench have improved dramatically but still fail on roughly half of real-world bug-fix tasks. Web navigation agents struggle significantly with multi-step interactive tasks on platforms they weren’t explicitly trained for. The failure modes are also different from chatbot failures — agents can fail silently by confidently taking wrong actions that don’t raise obvious errors, which is worse than a chatbot giving a bad answer. Production deployments that work well typically include strict task scoping (the agent operates within a defined domain and set of tools), checkpointing (human approval required at key decision points), and comprehensive logging so failures can be diagnosed and corrected. “Fully autonomous” deployment without oversight remains genuinely risky for anything consequential.
What are the best agent frameworks available in 2026?
The landscape has matured considerably. LangGraph (from the LangChain team) is one of the most widely adopted frameworks for building stateful, graph-based agent workflows — it’s well-documented and handles the orchestration complexity reasonably well. CrewAI has become popular for multi-agent setups where different agents have specialized roles (a “researcher” agent, a “writer” agent, a “reviewer” agent working together). Microsoft’s Semantic Kernel is the enterprise-friendly option, with deep Azure integration. Autogen (also from Microsoft Research) enables conversational multi-agent patterns. For those wanting minimal abstraction, building directly with the Anthropic or OpenAI APIs using tool-calling features is still a perfectly valid approach — the frameworks add convenience but also add abstraction overhead that can make debugging harder. For enterprise platforms rather than build-it-yourself frameworks, Salesforce Agentforce, Microsoft Copilot Studio, and ServiceNow’s AI agent offerings represent the packaged route. Choice really depends on whether you’re a developer building custom systems (framework route) or an organization deploying against existing enterprise software (platform route).
How does reinforcement learning make agents better over time?
Standard language models are trained to predict likely next tokens — they don’t have an explicit notion of “did this plan succeed?” Reinforcement learning introduces that feedback signal. Instead of learning from static text, an RL-trained agent receives rewards based on task outcomes: did the code pass the tests? Did the customer issue get resolved? Did the research summary accurately reflect the sources? This reward signal is then used to update the policy (the model’s behavior) toward actions that lead to success. The challenge is that RL requires an environment — a simulator or real-world system the agent can interact with and receive feedback from. For coding, sandboxed code execution environments work well. For more open-ended tasks, defining a clean reward signal is hard, and you risk “reward hacking” where the agent learns to game the metric rather than actually solve the problem. Process reward models — which evaluate individual reasoning steps rather than only final outcomes — are an active research area aimed at making RL training for agents more reliable. Anthropic has published work on process supervision in this vein. The practical upshot: RL is increasingly important in state-of-the-art agent training, but it requires significant infrastructure investment and careful reward design.
Do I actually need an agent, or do I just need a better prompt?
This is honestly the most underasked question in the space. A lot of tasks that seem like they need an agent actually just need a better-structured prompt, a smarter model, or a simple workflow with one or two tool calls. Agents add meaningful value when: the task requires more than 3-4 sequential steps where each step’s output affects the next; the task involves unpredictable branching (you don’t know in advance which path you’ll need); error recovery matters (if a step fails, you want the system to try a different approach rather than giving up); or the total work exceeds what fits in a single context window. If none of those apply — if you’re essentially asking for a structured document, a code function, or an analysis of provided text — a single well-crafted prompt to a strong model will be faster, cheaper, and more reliable. The agent overhead (latency, cost, failure modes, debugging complexity) is real, and it only pays off when the task genuinely requires it. Start with the simplest possible approach, and move to agent architectures when you hit specific, identifiable ceilings.
My Verdict: A Genuinely Useful Technology Buried Under a Marketing Avalanche

After spending a lot of time with both the research literature and the production reality, my honest take is this: agentic AI is one of the more significant shifts in how software gets built — but the gap between the demo and the deployment is still wide, and the benchmarks are a useful reality check on where the technology actually sits.
The planning and tool-use capabilities are real and improving fast. SWE-bench scores have moved from near-zero to nearly half of sampled real-world bugs resolved autonomously in under two years — that’s a remarkable trajectory. MCTS-informed reasoning and process-supervised RL training are pushing the frontier further. But web navigation, open-ended reasoning, and anything requiring judgment in novel situations remain genuinely hard, and the failure modes in agent systems are sneakier than chatbot failures.
If you’re a developer or technical founder evaluating whether to build with agents: start with a clearly scoped task, pick a narrow set of tools, and add human checkpoints liberally. If you’re an enterprise buyer: ask vendors specifically about failure rates and recovery mechanisms, not just demo success stories. The technology deserves the attention it’s getting — just with both eyes open.
Last updated: 2026
Explore more AI tools
👉 Browse the AI Tools Library to find the right tools for your workflow.