目錄
當「看文件」這件事不再需要人類的眼睛
說真的,企業裡最不性感、卻最燒錢的工作,往往是「看東西」這件事——會計部門有人整天在對發票、把金額一個一個敲進系統;工廠產線上有人盯著螢幕找產品瑕疵,盯到眼睛快脫窗;倉管收貨時要核對單據上密密麻麻的料號。這些工作有個共同點:重複、無聊、容易出錯,而且找人來做的成本一年比一年高。
而過去兩年最大的變化,是多模態視覺 AI 真的「看得懂」這些東西了。不是早年那種只會辨認固定欄位的 OCR,而是能理解一張歪斜、皺折、甚至手寫塗改的單據在講什麼。Claude Vision、ChatGPT 的視覺能力與 Google Gemini Vision 這三大多模態模型,把「視覺理解」從實驗室推進到了可以掛在生產流程上的階段。
這篇文章不談規格表,談的是:這些視覺 AI 在金融、製造業裡到底怎麼被用起來、精度撐不撐得住、怎麼跟你公司現有的 RPA 跟 OCR 系統接,以及最現實的——什麼時候該用免費 API、什麼時候得花錢部署本地模型。
先搞懂:視覺 AI 跟傳統 OCR 差在哪
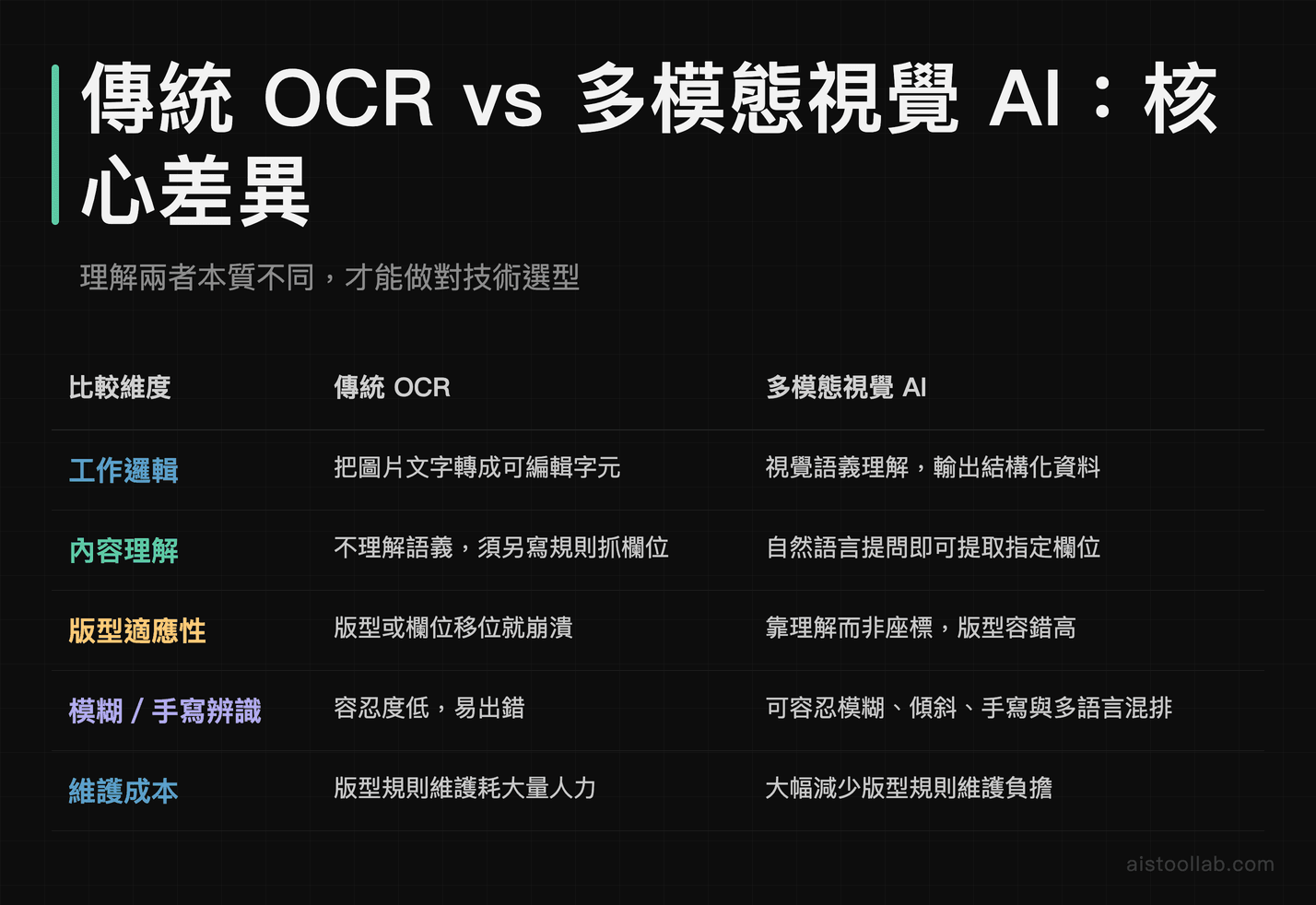
很多人以為這就是「更強的 OCR」,其實差很多。傳統 OCR 的工作是把圖片上的文字轉成可編輯的字元,它不理解內容——你給它一張發票,它吐給你一堆文字,但「哪個數字是總金額、哪個是稅額、哪個是廠商統編」得靠你另外寫規則去抓位置。一旦發票版型換了、欄位移位了,規則就崩了。這也是為什麼傳統文件自動化專案常常做到一半卡死,因為光是維護那些版型規則就耗掉大半人力。
多模態視覺 AI 的運作邏輯完全不同。它把圖片切成大量視覺片段(patch),轉換成跟文字共用同一個語義空間的向量,再由語言模型的推理能力去「理解」整張圖在表達什麼。換句話說,你可以直接用自然語言問它:「把這張發票的廠商名稱、統編、未稅金額、稅額、總計用 JSON 格式列出來」,它會自己找到對應欄位、處理掉雜訊,輸出結構化資料。版型變了?它通常照樣讀得出來,因為它靠的是理解而不是座標。
這個差異聽起來抽象,但落到實務上就是天壤之別:傳統方案碰到非標準格式就投降,視覺 AI 則能容忍模糊、傾斜、手寫與多語言混排。這也是為什麼 2026 年企業文件自動化的主流架構,已經從「純 OCR + 規則引擎」轉向「OCR 打底 + 視覺 AI 做語義理解」的混合模式。
三大視覺模型怎麼選:一張表先看懂定位
這三家的視覺能力都很強,但定位和取捨不太一樣。我把企業最在意的維度整理成下表,數字部分以官方文件與公開評測的普遍觀察為準,實際表現會因任務而異,建議自己拿真實樣本跑過一輪再決定。
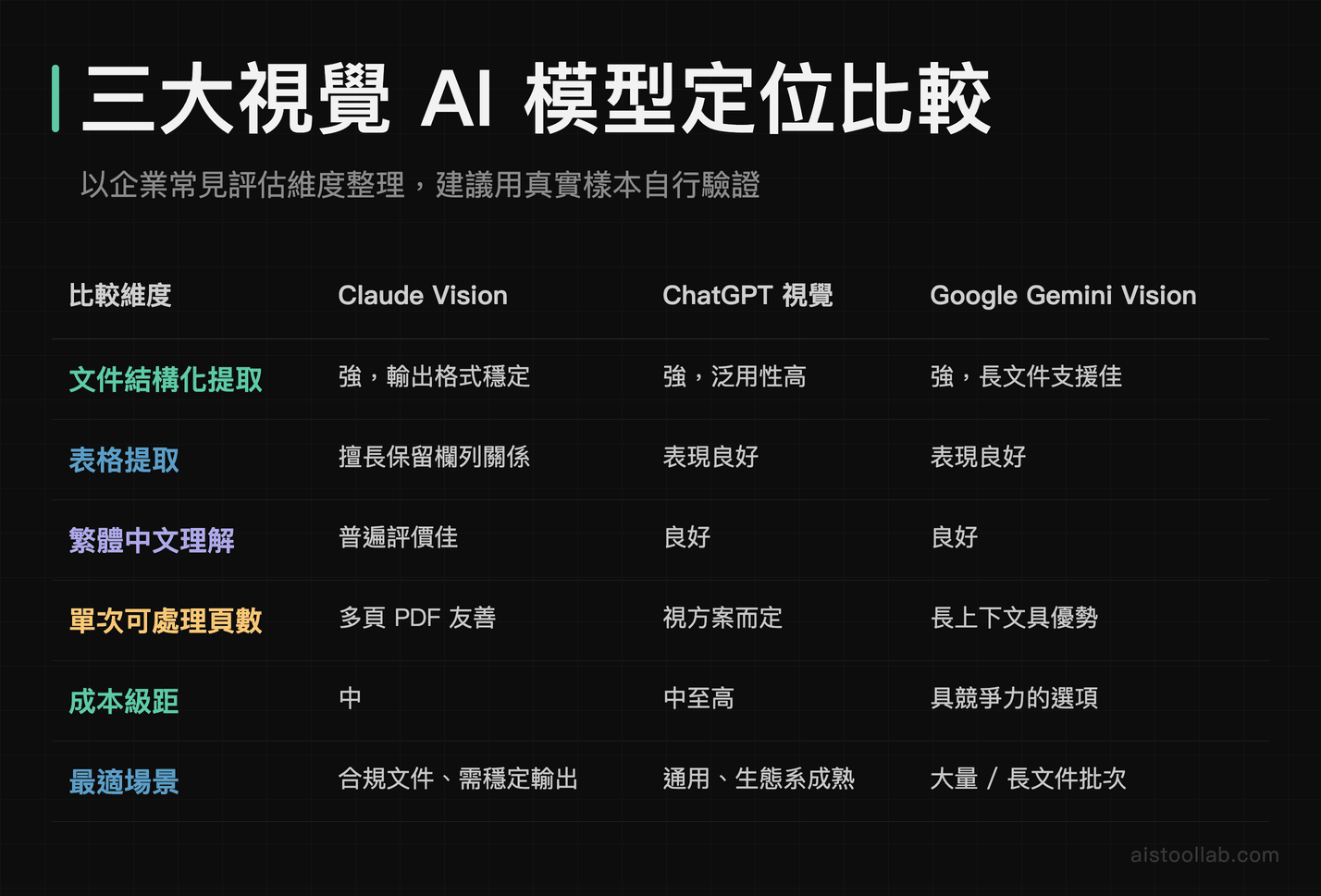
整理公開評測的共識大致是這樣:如果你的應用對「輸出格式穩定、不亂跳結構」要求很高,例如金融合規文件,Claude Vision 常被點名輸出特別聽話;如果你要的是生態系成熟、工具鏈現成,OpenAI 生態的周邊整合最齊;如果你要批次處理大量長文件、預算又要壓,Gemini 的長上下文與定價選項值得評估。沒有絕對的贏家,只有適不適合你的文件類型。
實際使用案例:這些 AI 到底被拿來幹嘛

金融業:發票與單據的自動入帳
假設你在一家中型會計事務所,月底最常見的痛點是:每到月底,幾百張格式各異的進銷項發票、收據、銀行對帳單湧進來,原本要靠工讀生一張張打字。導入視覺 AI 後的做法通常是——掃描件先進系統,模型直接讀出廠商統編、品項、未稅、稅額、總計,輸出成結構化資料,再丟進記帳系統。重點不在「快」,而在於它能處理那些版型亂七八糟、傳統 OCR 直接放棄的單據。當然,金額這種關鍵欄位仍會設信心門檻,低於門檻的自動轉人工複核,這是金融場景的標準保險做法。
製造業:產線品質檢驗的瑕疵偵測
製造業是視覺 AI 另一個重點戰場。傳統的機器視覺(machine vision)需要工程師為每一種瑕疵寫規則、調參數,新產品上線就得重新訓練一輪。多模態視覺模型的價值在於「零樣本」或「少樣本」的彈性——你可以用自然語言描述「找出表面刮痕、色差、缺件」,模型就能初步篩選。不過這裡要誠實說:對於微米級的精密缺陷偵測,目前通用大模型的精度仍不一定打得過專門訓練的工業視覺系統,比較務實的做法是「通用模型做初篩、專用模型做精判」的兩段式部署。
大學生與小團隊:把紙本資料數位化
不是只有大企業用得到。接案的設計師收到客戶傳來一疊拍歪的紙本報價單,要整理成 Excel;大學生做專題要把幾十頁問卷掃描檔轉成數據表;新創 PM 沒預算買企業級文件系統,直接用 API 寫個小腳本批次處理。這類「量不大但很煩」的需求,反而是視覺 AI 很容易看到效果的場景——在便利商店等咖啡的空檔,把照片丟進去,回來資料就整理好了。這也是我會建議個人與小團隊先從免費或低用量 API 玩起的原因。
怎麼跟現有系統接:端到端管道長這樣

企業最常問的不是「準不準」,而是「怎麼接進我現在的流程」。視覺 AI 很少單獨存在,它通常是整條文件處理管道裡的一環。一個成熟的端到端架構大致是這樣:文件來源(掃描機、Email 附件、上傳介面)先進入前處理(去歪斜、提升解析度),接著由 OCR 打底抽出原始文字,再交給視覺 AI 做語義理解與結構化,輸出的 JSON 經過驗證規則(金額加總、統編格式檢查)後,由 RPA 工具自動填進 ERP 或記帳系統,異常案件則路由給人工複核。
這裡有個常被忽略的關鍵:視覺 AI 不是要取代你現有的 RPA 跟 OCR,而是補上它們最弱的那一塊——「理解非結構化內容」。RPA 擅長重複性的系統操作但不懂內容,OCR 擅長轉文字但不懂語義,視覺 AI 剛好填進中間那段。所以導入時不該是「全部打掉重練」,而是把模型當成一個 API 服務,掛在現有流程的理解環節上。這種漸進式整合風險低、見效快,也比較容易說服老闆放行預算。
另外提醒一個實務細節:務必設計「人在迴路」(human-in-the-loop)機制。再強的模型都會有讀錯的時候,金融與製造這類錯一張就出大事的場景,一定要有信心分數門檻與人工覆核閘門,而不是讓模型全自動跑到底。
成本與準確度的平衡:四種情境的決策邏輯

這大概是整篇最實用的部分。什麼時候用雲端 API、什麼時候自己部署、什麼時候要微調,沒有標準答案,但有清楚的判斷邏輯:
- 用量小、快速驗證:直接用三大廠的雲端 API。不用養機器、不用顧維運,按量計費,個人與小團隊幾乎都該從這裡開始。先用真實樣本驗證準確度撐不撐得住,再談規模化。
- 用量大、資料敏感:當每月處理量到一定規模,雲端 API 的帳單會開始讓財務皺眉;加上金融、醫療這類資料不能離開公司內網的場景,就該評估部署開源視覺模型在自家 GPU 上。前期硬體投入高,但長期單張成本可能更低,且資料不外流。
- 特定領域、格式高度固定:例如你永遠只處理某幾種制式表單,這時微調(fine-tune)一個較小的開源模型,往往比硬用通用大模型更划算也更準。微調需要標註資料與工程能力,但能換來更低的推論成本與更穩的表現。
- 精度要求極高的工業檢驗:通用模型做初篩,再串接專門訓練的工業視覺系統做精判。別指望單一通用模型搞定微米級缺陷,分工才是正解。
講白一點,先用便宜的方式驗證需求,確定值得投資後再往本地部署或微調走,不要一開始就砸大錢買 GPU 叢集——很多專案就是死在「還沒驗證就過度建設」。
常見問題
視覺 AI 讀繁體中文發票準確嗎?會不會把字讀錯?
整理公開評測與使用者回饋來看,三大模型對繁體中文的理解都算不錯,尤其在印刷體、版型清晰的單據上表現穩定。但要誠實說,越是模糊、手寫、蓋章覆蓋文字的情況,出錯機率就越高,這是所有視覺模型共通的限制,不是某一家特別爛。實務上的標準做法是:對統編、金額這類關鍵欄位設定信心門檻,模型不確定的就自動轉人工複核,而不是全盤相信。如果你的單據品質參差不齊,建議先拿一兩百張真實樣本跑過,統計實際準確率再決定要不要上線,這比看任何廠商的行銷數字都可靠。
華語圈公司現在可以直接用這些 API 嗎?刷卡會被擋嗎?
目前 Claude、OpenAI 與 Google 的相關 API 服務,開發者與企業能否正常申請與使用,應以各家官方支援的國家/地區清單為準;付費通常支援主流國際 Visa / Mastercard 信用卡。比較需要注意的是各家的服務條款、資料處理地與隱私政策,特別是金融、醫療這類受監管產業,導入前最好讓法務確認資料是否會傳輸到境外、是否符合公司的合規要求。如果你的資料完全不能出境,那答案就很明確——要走本地部署開源模型這條路,而不是雲端 API。建議實際串接前先讀清楚官方文件的資料使用條款,別等上線了才發現踩到合規紅線。
免費版額度夠企業用嗎?還是一定要付費?
免費或低用量的額度適合拿來驗證可行性、做 demo,但要支撐企業正式生產流程的處理量,基本上都得進入付費。費用是按處理的圖片數量與複雜度計算,換算下來,小團隊每月可能就幾百到上千台幣不等,大企業批次處理則可能是另一個量級。我的建議是:先用免費額度確認準確度與流程跑得通,估算出每月實際用量後,再去算雲端 API 的帳單划不划算。如果月處理量很大,那就是該認真評估本地部署的訊號——固定的硬體成本攤下來,單張處理成本反而可能更低。
視覺 AI 能取代工廠現有的機器視覺檢測系統嗎?
就目前的技術現況,答案是「補強而非取代」。傳統工業機器視覺在微米級、高速、固定產品的精密缺陷偵測上,經過專門訓練後精度與穩定度仍有優勢,而且推論速度快、成本可控。多模態視覺 AI 的價值在彈性——不用為每種新瑕疵重寫規則,能用自然語言描述要找什麼,適合產品線多變、瑕疵類型難以窮舉的場景。比較務實的部署是兩段式:通用視覺 AI 做初篩與分類,把可疑品挑出來,再交給專用系統或人工做精判。把它當成「多一雙懂得舉一反三的眼睛」,而不是直接換掉產線設備。
整合到現有 RPA 跟 OCR 系統會很複雜嗎?
沒有想像中那麼可怕。視覺 AI 通常以 API 形式提供,你的 RPA 流程在需要「理解文件內容」的那一步,呼叫一次 API 拿回結構化的 JSON,再繼續往下填表、入系統就好,本質上就是多串一個 web service。真正花時間的不是串接,而是前處理(影像品質提升)、輸出驗證規則設計,以及人工複核流程的安排。建議用漸進式導入:先挑一個量大、規則固定的文件類型試水溫,跑順了再擴展到其他類型,不要一次想吃下所有文件流程,那種大爆炸式上線最容易翻車。
Claude Vision、ChatGPT 的視覺能力、Gemini Vision 我該選哪個?
看你的核心需求。如果你的應用對「輸出格式穩定、不亂跳結構」極度敏感,例如要把結果直接寫進金融系統,公開評測中 Claude Vision 常被稱讚輸出特別聽話、結構乾淨。如果你看重生態系成熟、現成工具鏈多,OpenAI 生態的周邊工具鏈選擇較多,這點你可以直接比對各家官方的整合清單。如果你要批次處理大量長文件、又想壓成本,Gemini 的長上下文能力與定價選項值得評估。但說真的,最好的方法不是看比較表,而是拿你自己最頭痛的那批真實文件,三家都跑一輪,比準確率、比輸出穩定度、比每張成本,結果一翻兩瞪眼。
用視覺 AI 處理公司機密文件,資料安全嗎?
這要分兩種情境看。用雲端 API 時,資料會傳到服務商的伺服器處理,雖然各家都有資料保護政策、企業方案通常也承諾不拿你的資料訓練模型,但對於絕對不能外流的高敏感資料,這個風險本身就不可接受。這種情況比較穩妥的做法,是把模型部署在自己的環境裡(開源模型自架,或供應商提供的私有/地端部署),讓資料留在公司內網。導入前務必讀清楚廠商的資料使用與保留條款,並讓資安與法務一起評估。一個簡單原則:資料敏感度越高,越該往本地部署傾斜,別為了省事把命脈交出去。
導入這套自動化,多久能回本?
這沒有通用答案,取決於你原本花在人工處理文件的成本有多高。對於原本要養好幾個人專門打單、對帳的企業,省下的人力時間通常很快就能覆蓋 API 或部署成本;但如果你的文件量本來就小,硬上一套自動化反而不划算。我的建議是先算清楚現況:每月處理多少份文件、花掉多少人時、錯誤造成多少損失,再對照導入後的成本與省下的時間。記得把「準確度提升、錯誤減少」這種隱性效益也算進去——在金融場景,少打錯一個金額省下的麻煩,往往比省下的人力還值錢。
我的判斷:這是少數「現在就該動手」的 AI 應用

跟很多還在炒作階段的 AI 應用不同,企業視覺流程自動化是已經能落地、投報率也算得出來的領域。它不花俏,但它解決的是企業每天都在流血的真實痛點——重複、易錯、燒人力的「看文件」工作。技術成熟度夠了,三大模型的能力也撐得住多數商用場景。
如果是我來規劃,我會這樣走:先用雲端 API 拿真實文件跑一輪驗證,確定準確度撐得住、流程接得通,再依用量與資料敏感度決定要不要往本地部署或微調走。不要一開始就追求全自動、全覆蓋,先挑一個最痛的文件類型開刀,跑順了再擴張。視覺 AI 還不完美,金額讀錯、瑕疵漏判的狀況一定還會發生,所以「人在迴路」的覆核機制現階段不能省。我會持續觀察開源模型的精度進展,以及本地部署成本的下降速度——這兩件事一旦到位,整個賽局又會再翻一輪。有新進展我會回來更新。
最後更新:2026 年
喜歡這篇評測?
👉 瀏覽 AI 工具庫,找到最適合你工作流程的 AI 工具。
延伸閱讀:AI Agent 工作原理與應用突破 2026:自主執行、工具調用、多步推理如何改變問題解決方式