「想久一點就會答對」這件事,AI 居然真的學會了
先講一個很多人有的誤解:以為 AI 推理模型就是「把同一個大語言模型多跑幾次、湊出一個比較長的答案」。如果你也這樣想,那這篇就是寫給你看的——因為這個理解差不多錯了一半。
2024 年下半年到 2025 年,AI 圈最大的轉變不是模型「變大」,而是模型開始「會想」。OpenAI 的 o1、DeepSeek 的 R1,還有 Claude 的 Extended Thinking,這三套東西用各自的方式證明了同一件事:讓模型在回答前先「自己跟自己對話」一段時間,數學、程式、科學題的正確率會明顯往上跳。這不是行銷話術,是有 benchmark 數字撐著的。
老實說,這個轉變對華語圈的工程師、研究生、資料分析師影響特別大,因為它直接改變了「哪些任務值得交給 AI」的判斷。以前你不會把一道複雜的演算法題丟給 ChatGPT,因為它常常自信滿滿地給你錯的。現在情況不太一樣了。這篇我會把推理模型的原理、三家的技術差異、實測成效、還有最現實的成本速度權衡講清楚。
目錄
破解誤解:推理模型到底跟傳統 LLM 差在哪

傳統的大語言模型(像早期的 GPT-4、Claude 3)運作方式,簡單說就是「看到問題,一個字一個字往下接」。它沒有真正停下來規劃,token 一路吐出來,吐到哪算到哪。這種模式對「寫一封 email」很夠用,但碰到需要多步推導的題目——例如一道要列三個方程式再聯立求解的數學題——它很容易在中間某一步算錯,然後一路錯到底,最後還講得理直氣壯。
推理模型的根本差別,在於它把「思考過程」變成了一個獨立、可以拉長的階段。模型在給你最終答案之前,會先產生一大段內部的推理鏈(chain-of-thought),在裡面嘗試、檢查、推翻、重來。你可以把它想成:傳統 LLM 是「想到什麼說什麼」,推理模型是「先在草稿紙上算一遍,確認沒問題才謄到考卷上」。
親手看一次「草稿紙」長什麼樣
為了讓你看到這個差別,我把一題經典的直覺陷阱題丟給現在會思考的 ChatGPT:一本筆記本和一支筆共 $2.60,筆記本比筆貴 $2.00,問筆多少錢。很多人(還有早期只會一路往下接的 LLM)會脫口而出 $0.60——但那是錯的。畫面上它先出現「已思考 2 秒鐘」,然後老實把式子攤開:設筆為 x、筆記本 x+2.00、2x+2.00=2.60,解得 x=0.30,答 $0.30。這題本身很簡單,重點不在難度,而在你能親眼看到它「先算再答」、沒有被直覺帶著走——這正是推理模型和傳統 LLM 最核心的差別。(單題、當天單次,不代表所有題目或所有時候。)
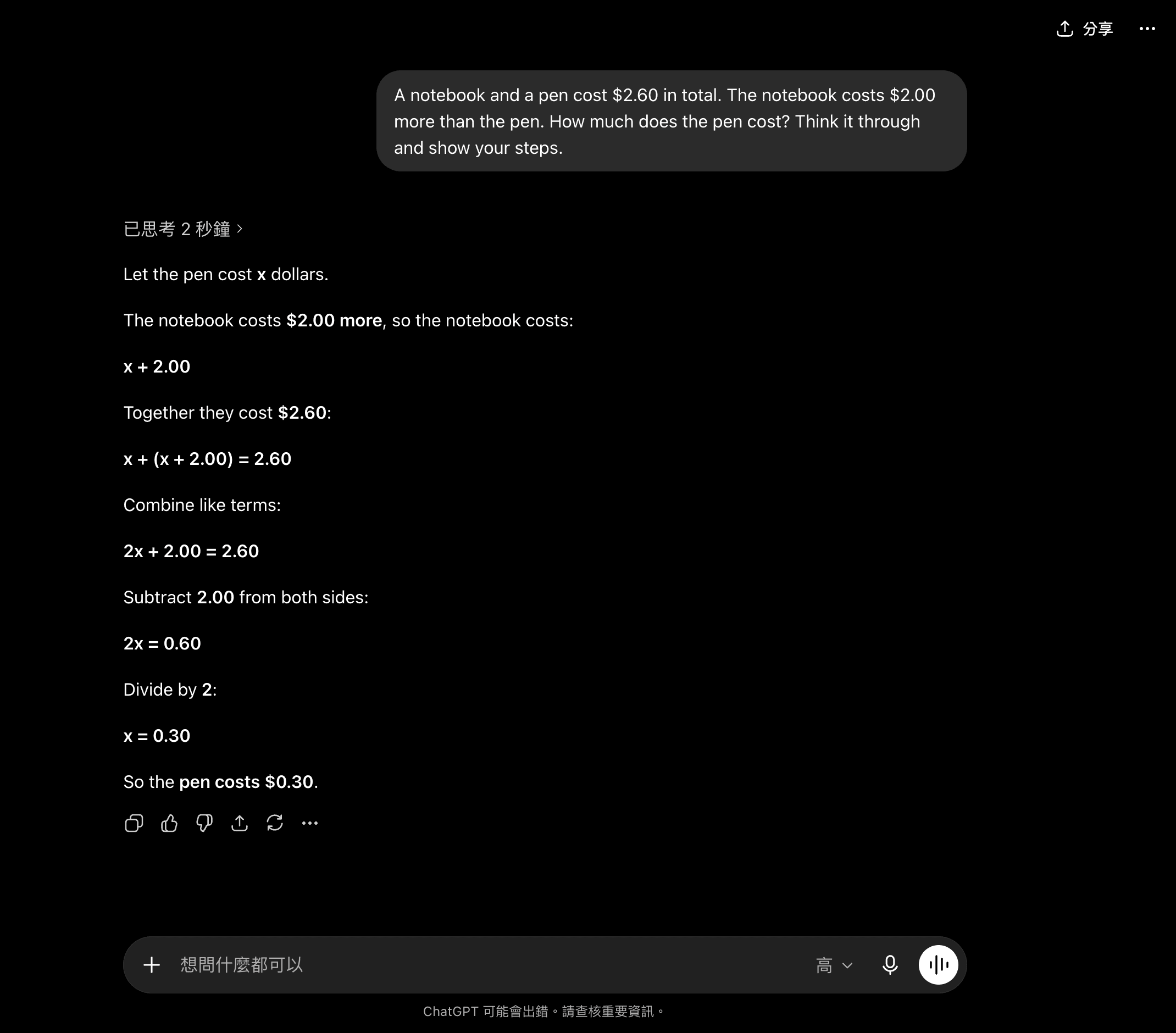
這個「草稿紙」階段為什麼有用?根據 OpenAI 公布的技術說明,o1 是透過大規模強化學習,讓模型學會「如何有效地思考」——不是隨便多寫字,而是學會在推理過程中辨識錯誤、拆解步驟、嘗試不同路徑。關鍵發現是:給模型越多「思考運算量」(test-time compute),它在困難推理任務上的表現就越好。這是一個跟「把模型訓練得更大」不同方向的擴展路線,業界稱為「推理時擴展(inference-time scaling)」。
chain-of-thought 這個概念本身不新,Google 研究團隊在 2022 年的論文就提出「讓模型一步步思考」能提升推理表現。但 o1 之後的突破在於:思考不再是靠 prompt 硬擠出來的,而是被內化進模型的訓練目標裡,模型自己會決定要想多久、想多深。
三家技術路線怎麼比:o1、DeepSeek-R1、Claude Extended Thinking
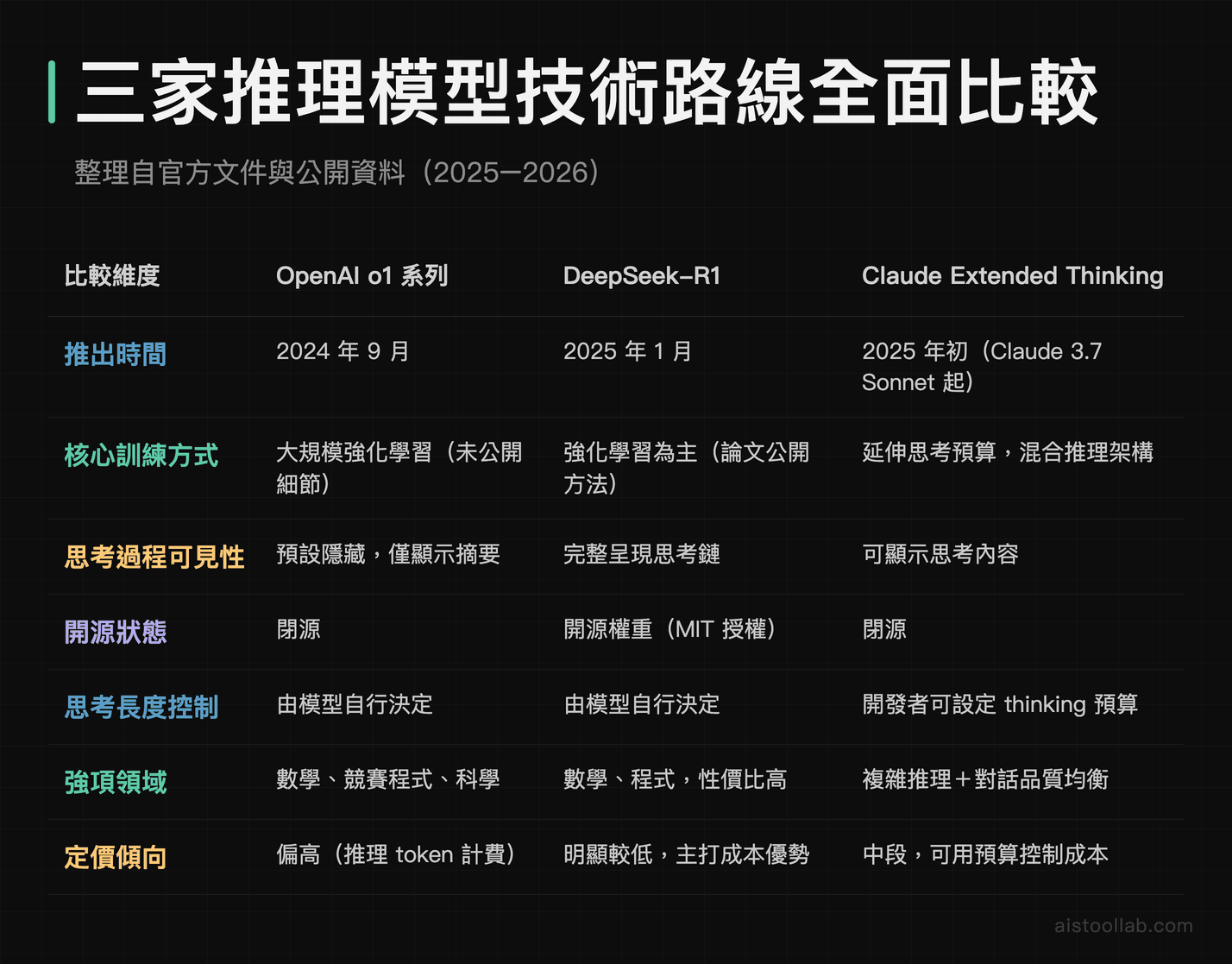
這三套都叫「推理模型」,但實作哲學差很多。我把整理自官方文件與公開資料的重點放在這張表,先給你一個全貌,後面再展開講。
OpenAI o1:把推理當成獨立能力來訓練
o1 是這波的開路先鋒。它最大的特色是把思考過程「藏起來」——你只看得到一段摘要,看不到完整的內部推理鏈。OpenAI 給的理由是安全與商業考量。實務上 o1 的強項非常明確:競賽級數學(AIME)、科學推理(GPQA)、競賽程式(Codeforces)這類有標準答案、需要多步推導的題目,表現相當亮眼。根據 OpenAI 官方公布的資料,o1 在這些 benchmark 上相比前代 GPT-4o 有大幅提升。缺點也明確:貴、慢,而且因為思考過程不透明,你很難 debug 它為什麼這樣答。
DeepSeek-R1:把方法攤開來,還開源

這段講 DeepSeek-R1『把方法攤開來』,我們就開它的『深度思考』模式實測一次。丟一題經典指數推理題,它沒有直接跳答案,而是先把思考草稿攤開(逐步倒推、還自我檢查有沒有理解陷阱),再給出乾淨的分步解答與結論。用了才有感的差別:相較於本文提到『o1 只給思考摘要、看不到完整推理鏈』,R1 願意把過程整段呈現,對想理解或除錯推理邏輯的人特別有用。本次真實測以可免費登入的 DeepSeek-R1 為主,o1 與 Claude Extended Thinking 為官方資料與公開評價整理,未逐一實測。
R1 之所以在 2025 年初引爆討論,原因有兩個。第一,它用論文把「如何用強化學習訓練出推理能力」這件事講得相當清楚,甚至展示了模型在訓練過程中自己「學會」更長思考的現象。第二,它開源權重、採 MIT 授權,等於把一個逼近頂級閉源推理模型的東西免費送出來。對新創與研究團隊來說,這意義很大——你可以自己部署、自己微調,不用每個 token 都付錢給 API。R1 的思考鏈是完整可見的,這對想理解模型怎麼想的開發者非常友善。
Claude Extended Thinking:讓你決定它要想多久
Claude 的做法走了一條比較務實的路。Claude 的 Extended Thinking 把「思考」做成一個可調的預算——開發者可以指定要分配多少 token 給思考階段。簡單任務就少想一點省錢省時間,硬題目就拉高預算讓它慢慢算。這種「混合推理」的設計,等於把推理能力變成一個可以開關、可以調強弱的旋鈕,而不是一個固定模式。對企業來說這很重要,因為你不會想為了一句「幫我潤稿」付出競賽數學等級的運算成本。
實際成效:數學、程式、科學研究的驗證

講原理講半天,最後還是要看它在真實任務上有沒有用。整理目前公開的 benchmark 與評測共識,推理模型在以下三類任務的提升最明顯。
數學推理是差距最戲劇化的領域。在 AIME(美國數學邀請賽)這類題目上,傳統 LLM 常常只能答對個位數比例,而 o1、R1 這類推理模型的正確率有大幅跳升。原因很直觀:數學題最怕中間一步算錯,而推理模型會在草稿階段反覆檢查,把「粗心錯」大量過濾掉。
程式設計方面,推理模型在「需要演算法設計」的題目上特別吃香。它不只是把你要的函式吐出來,而是會先想「這題用什麼資料結構、時間複雜度能不能接受、有沒有邊界情況」。在 Codeforces 這類競賽程式評測上,推理模型的等級分明顯高於傳統模型。不過要講公平:日常的 CRUD、串 API、寫前端這種「不太需要深度推理」的工作,推理模型不見得比快速模型划算,因為你付了思考的錢卻沒用到思考的價值。
科學研究則是最有想像空間、但也最需要謹慎的領域。在 GPQA(研究生級的物理、化學、生物題)這類 benchmark 上,推理模型表現確實往上走。但要強調:benchmark 答得好,不等於能真的做出原創科學發現。目前研究普遍認為,推理模型在「協助推導、檢查邏輯、整理文獻假設」上很有幫助,但它仍會產生看似合理卻錯誤的推理(這現象並未因為推理能力提升而消失),科研場景一定要人類把關。這點我必須老實說,不能因為數字好看就吹過頭。
誰該用、怎麼用:三個真實情境
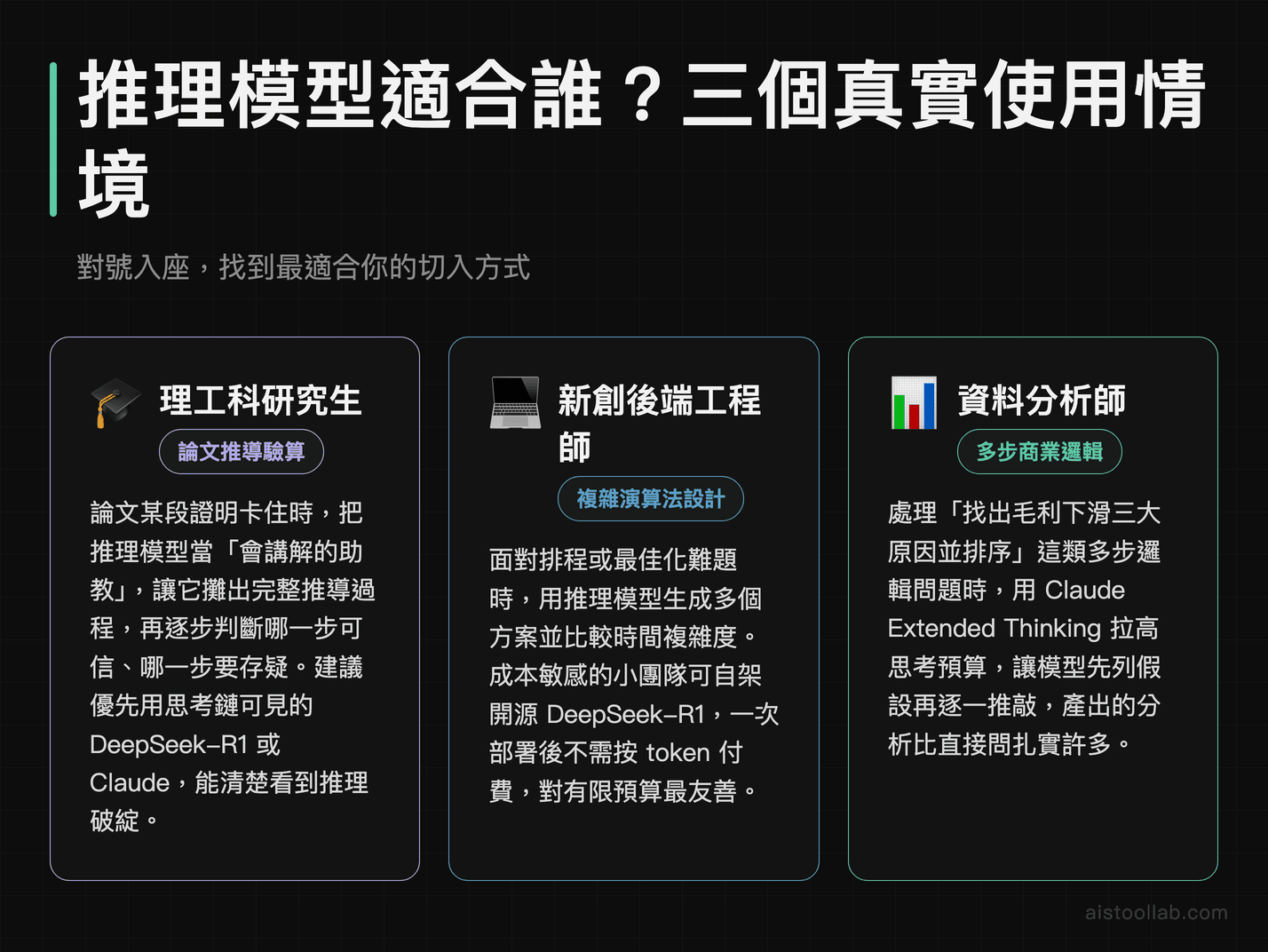
情境一:理工科研究生趕論文的推導與驗算
假設你是理工科的碩士生,論文裡有一段證明卡住了。傳統做法是自己跟白板耗一整晚。現在你可以把問題餵給推理模型,讓它先把推導過程攤出來,你再逐步檢查它哪一步可信、哪一步要存疑。重點是把它當「會講解的助教」而不是「答案產生器」——因為 R1 和 Claude 的思考過程可見,你能看到它的推理邏輯,發現破綻的機會比直接看結論高很多。
情境二:新創團隊的後端工程師處理複雜演算法
很多小型新創沒有資源養演算法專家。當團隊遇到一個需要精心設計的排程或最佳化問題時,與其讓一般模型亂槍打鳥,不如用推理模型先生成幾個方案、比較複雜度。成本敏感的話,自架 DeepSeek-R1 是很實際的選項——一次部署,之後跑再多次都不用付 API 費用,對預算有限的團隊很友善。這也是為什麼 R1 開源這件事在工程圈反應這麼熱烈。
情境三:資料分析師處理需要多步邏輯的商業問題
當老闆丟來一個「為什麼這季某產品線毛利掉了、幫我找出三個可能原因並排序」這種問題,它需要的不是漂亮文字,而是有條理的多步推理。這時用 Claude Extended Thinking 把思考預算拉高,讓它先列假設、再逐一推敲,產出的分析品質會比直接問明顯紮實。這類工作流也能接到既有的AI 工作流自動化平台裡,把推理當成流程中的一個「深度思考節點」。
最現實的權衡:成本、速度、準確率怎麼選

推理模型不是萬靈丹,它的代價很具體:思考要花 token,token 要花錢,而且要花時間。一個傳統模型可能 2 秒回你,推理模型遇到難題思考個十幾秒、幾十秒都正常。這代表三件事——你的 API 帳單會變高、使用者體驗上等待變長、簡單任務用它根本是浪費。
我整理出的判斷原則很簡單:題目越需要「多步推導且容錯率低」,推理模型的價值越高。數學、演算法、邏輯密集的分析,值得付這個錢。但寫文案、翻譯、客服回覆、整理會議記錄這種任務,用快速模型反而又快又省。聰明的做法是「分流」:簡單的走便宜快速模型,難的才路由到推理模型。Claude 那種可調思考預算的設計,本質上就是在幫你做這件事。
成本敏感的華語圈團隊,我會建議這樣排優先序:要省到底、又有技術能力自架,選開源的 DeepSeek-R1;要最強的競賽級推理、預算充足,o1/o3 系列仍是標竿;要在「推理品質」與「對話體驗、成本控制」之間取平衡,Claude Extended Thinking 的可調預算是我會先試的中間選擇。
常見問題
推理模型一定比傳統 LLM 好嗎?我該全部換過去嗎?
不該。推理模型只在「需要多步邏輯推導」的任務上有明顯優勢,例如數學、演算法設計、複雜的因果分析。對於寫文案、翻譯、摘要、閒聊、客服這類任務,傳統的快速模型不只夠用,而且更快更便宜。如果你把所有任務都丟給推理模型,結果就是帳單暴增、回應變慢,卻沒換到對等的品質提升。比較務實的做法是「混用」:建立一個分流機制,簡單任務走快速模型,碰到真正困難、需要深度推理的才升級到推理模型。許多開發框架現在都支援這種路由設計,能幫你在品質與成本之間找到平衡點。
DeepSeek-R1 開源,是不是代表我可以完全免費使用?
權重開源(MIT 授權)的意思是你可以免費下載模型、自己部署、商用也可以,但「免費」不等於「沒有成本」。你需要有夠力的 GPU 硬體或租用雲端運算資源來跑它,而完整版的 R1 對硬體要求不低,自架的算力成本對個人或小團隊可能不便宜。好消息是社群也釋出了多個蒸餾過的小版本,硬體門檻低很多,適合資源有限的場景。如果你不想處理部署,也可以直接用 DeepSeek 官方或第三方平台提供的 API,價格通常比同級閉源推理模型低不少。要不要自架,取決於你的使用量和技術能力。
為什麼 o1 不讓我看完整的思考過程?
OpenAI 官方的說法是基於安全、商業競爭以及使用者體驗的綜合考量,o1 預設只顯示思考過程的摘要,而非完整的內部推理鏈。對一般使用者影響不大,但對想要 debug、想理解模型推理邏輯的開發者來說確實是個限制——你看不到它哪一步開始走偏。這也是 DeepSeek-R1 和 Claude 在開發者圈受歡迎的原因之一,它們的思考過程是可見的,你能順著它的邏輯找出問題點。如果你的工作高度依賴「驗證模型的推理是否正確」,思考過程透明的模型會比較合你的需求。
推理模型還會「一本正經地胡說八道」嗎?
會,這點要誠實講。推理能力提升確實減少了「中間步驟算錯」這類粗心型錯誤,數學和程式題的正確率因此提高。但「幻覺」(產生看似合理、實則錯誤的內容)這個根本問題並沒有被推理能力消除。模型仍可能在一段邏輯嚴密、條理清楚的推理裡,藏著一個錯誤的前提或捏造的事實,而且因為它講得更有條理,反而更容易讓人誤信。所以在科學研究、財務、法律這類高風險場景,絕對不能因為「它會推理了」就放心讓它自動決策。把它當成會講解思路的助手,最終判斷還是要人類來下。
中文使用者可以正常使用這三個模型嗎?用一般信用卡刷卡會有問題嗎?
就目前狀況,中文使用者能否透過官方 API 或網頁介面使用 o1 系列、Claude,應以官方支援的國家/地區清單為準;一般國際信用卡多數可用於訂閱,建議使用支援海外交易的卡別。DeepSeek 的模型因為開源,你可以在本地或自己的雲端環境部署;若要用其官方 API,可用性與付費方式請以官方當下公告為準。整體來說,華語圈團隊可依所在地區評估這三套服務。比較需要留意的是各家定價、額度政策會隨時間調整,實際訂閱前建議到官方頁面確認最新方案與計費方式。
思考時間越長,答案就一定越準嗎?
大方向上「給更多思考運算量能提升困難任務表現」是這波推理模型的核心發現,但這不是無限線性的關係。對於簡單問題,多想並不會讓答案更對,只是浪費時間和成本;對於困難問題,多思考的邊際效益也會隨著時間遞減到某個程度後趨於平緩。Claude Extended Thinking 之所以做成「可調思考預算」,正是因為最佳思考長度會隨任務難度變動——你應該根據題目複雜度來分配,而不是一律拉到最高。實務上的建議是:先用中等預算試,如果答案品質不夠再往上加,找到你這類任務的甜蜜點,而不是預設「越久越好」。
程式開發我到底該用推理模型還是一般的 AI 編程工具?
看你寫的是什麼。如果是日常的串 API、寫 CRUD、刻前端、修小 bug,這些不太需要深度推理的工作,用反應快的一般編程助手(像 GitHub Copilot 這類)效率更高,因為你要的是即時補全與快速迭代,不是慢慢思考。但如果你遇到的是演算法設計、效能最佳化、複雜的架構決策、難纏的 debug,這種「需要先想清楚再動手」的場景,推理模型的價值就出來了。最理想的工作流是兩者搭配:寫程式時用快速工具,卡關時把難題丟給推理模型分析,拿到思路後再回到快速工具繼續。
對企業導入來說,最容易踩的坑是什麼?
最常見的坑是「一刀切」——要嘛全公司都用最貴的推理模型導致成本失控,要嘛完全不用結果在需要推理的場景吃虧。正確做法是先盤點任務類型,把工作分成「需要深度推理」和「不需要」兩類,再對應到不同模型。第二個坑是低估延遲對使用者體驗的影響,推理模型動輒思考數十秒,若放在需要即時回應的前台場景(像即時客服)會很糟,這類場景應放快速模型,推理模型留給後台分析。第三個坑是過度信任,把推理結果直接拿去做高風險決策而沒有人工複核。先從低風險、高價值的內部任務試水溫,建立分流與驗證機制,再逐步擴大,是比較穩的路。
結論:如果是我,我會這樣分配

這個選擇其實沒有標準答案,因為它取決於你手上是什麼任務、預算多少、技術能力到哪。但如果是我來決定,我的配置會是這樣:日常大量、不需要深度思考的工作,全部走便宜的快速模型;真正困難、容錯率低的推理任務——數學推導、演算法、複雜分析——才路由到推理模型。三家裡面,要極致省錢又養得起工程師就自架 DeepSeek-R1,要平衡品質與成本控制就用 Claude Extended Thinking 的可調預算,要最強競賽級推理且預算充足就上 o1/o3。
推理模型最讓我覺得有意思的地方不是「它變聰明了」,而是它讓「思考」第一次變成一個可以用錢和時間買、可以調強弱的東西。這在 AI 的發展史上是個方向性的轉折。當然它還不完美——幻覺沒消失、成本還偏高、延遲還很有感——這些我會持續觀察,有新進展再跟你們更新。
最後更新:2026 年
喜歡這篇評測?
👉 瀏覽 AI 工具庫,找到最適合你工作流程的 AI 工具。
延伸閱讀:Claude Fable 5 實測:我在 claude.ai 用 High effort 跑除錯題,和 Opus 4.8 差在哪(2026)