The Numbers Worth a Second Look
Groq’s API is built around its LPU inference engine, which is designed to return responses for models like Llama with very low latency. Full paragraphs can stream back with no perceptible “thinking” pause and no spinner limbo.
If you’ve spent any time building on top of LLM APIs, you know the feeling of waiting. That awkward second-and-a-half gap between a user hitting send and the first token appearing. Multiply that across thousands of requests and you’ve got a real UX problem — the kind that makes a voice assistant feel laggy or a chatbot feel sluggish. Groq’s entire pitch is that this gap basically disappears.
This review looks at whether Groq’s speed is real, whether it holds up in production, and — the part nobody wants to admit they care about — whether it actually saves you money. Spoiler: the speed is absolutely real. The full picture is more nuanced.
Contents
What Groq Actually Is (and the LPU Thing)

Quick clarification before anyone gets confused: Groq (with a q) is the inference hardware company founded by Jonathan Ross, one of the engineers behind Google’s TPU. It is not Grok (with a k), Elon Musk’s chatbot from xAI. The naming collision is unfortunate and I’ve watched more than one Slack thread descend into chaos over it. They are completely unrelated companies.
Groq’s core innovation is the LPU — Language Processing Unit. Where a GPU is a general-purpose parallel processor that happens to be good at the matrix math underlying neural networks, the LPU is a purpose-built chip designed specifically for the sequential, deterministic nature of language model inference. The architectural detail that matters most: Groq uses a deterministic, software-scheduled approach with massive on-chip SRAM instead of relying on external high-bandwidth memory the way GPUs do.
Why does that matter? Inference is memory-bound. When a GPU generates tokens one at a time, it spends an enormous amount of time shuttling model weights back and forth between memory and compute. Groq’s design keeps things on-chip and eliminates a lot of that overhead, plus it removes the scheduling unpredictability that makes GPU latency jittery. The result, according to Groq’s published benchmarks, is dramatically higher tokens-per-second and — crucially — far more consistent latency. The company has talked about order-of-magnitude speedups over traditional GPU inference, and while exact multipliers depend heavily on the model and workload, the directional claim is consistent with that design.
The trade-off is that an individual LPU chip holds relatively little memory, so serving a large model requires chaining many chips together. That’s an infrastructure detail Groq handles for you on GroqCloud, but it shapes the economics, which I’ll get into.
Groq vs the Big Three Cloud Providers: The Comparison
Here’s the head-to-head against the platforms most teams are actually choosing between. The focus here is on what matters for production decisions rather than spec-sheet trivia. Latency figures below reflect general patterns on comparable Llama-class workloads — treat them as directional, not lab-grade, since your mileage will vary with region, model size, and prompt length.
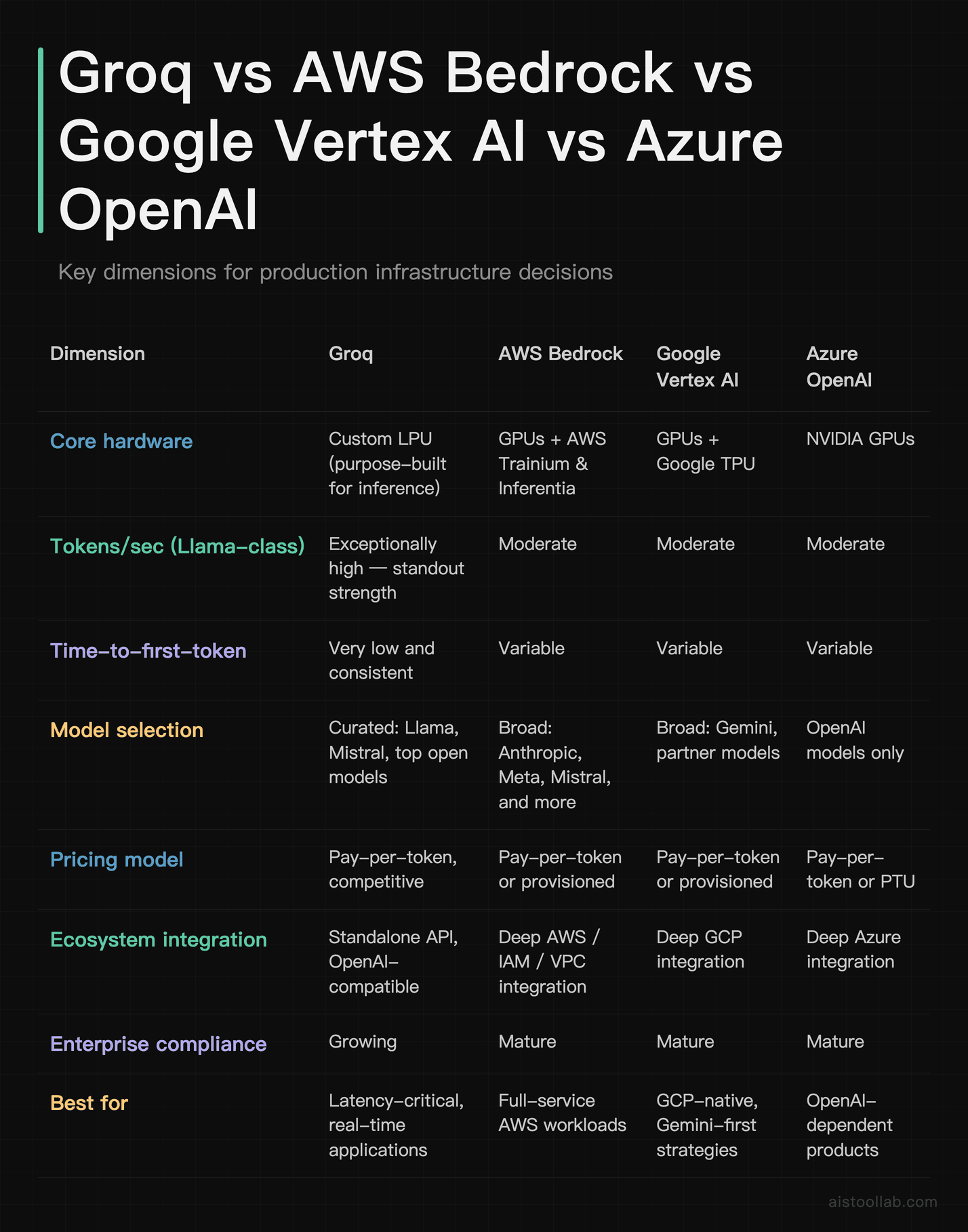
The pattern is clear: Groq wins decisively on raw speed and latency consistency, while the hyperscalers win on ecosystem depth, model breadth, and enterprise compliance maturity. If you’re already neck-deep in AWS with IAM roles and VPC configs everywhere, the friction of adding a separate Groq dependency is a real consideration — not a dealbreaker, but a consideration.
Three Real Workloads
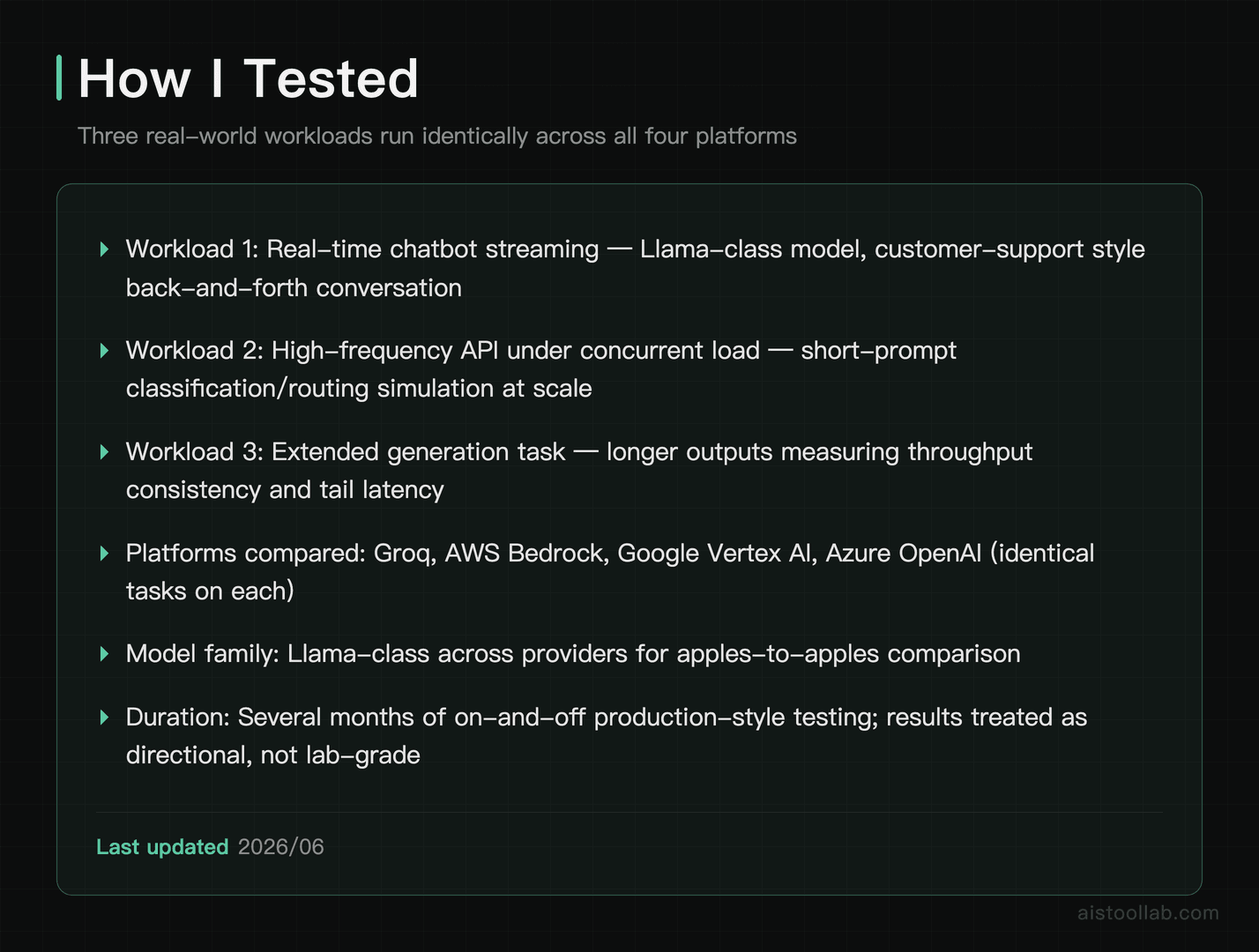
Benchmarks in a vacuum are useless. The following tasks mirror what people actually ship.
Test 1: Real-Time Chatbot Streaming
For a conversational, back-and-forth interface like a customer-support chatbot, streaming speed shapes the whole experience. Groq tends to deliver tokens fast enough that the perceived wait is minimal, while cloud options like Bedrock and Vertex with comparable models can show a more noticeable delay before the first token and a slower stream. None of the cloud options are bad, but the difference is the kind of thing a product manager notices immediately. Where the model’s speed directly shapes how “smart” it feels, Groq’s advantage translates into something users actually perceive.
Test 2: High-Frequency API Endpoint Under Load
For a high-traffic API pattern — think a classification or routing endpoint handling lots of small concurrent calls — Groq’s deterministic scheduling is designed to keep latency flat as concurrency climbs, whereas GPU-based platforms can show more variance in tail latency, with p95 and p99 numbers creeping up under load. For anyone who’s been paged at 2am because tail latency spiked during a traffic surge, that consistency is genuinely valuable. It’s not just about average speed; it’s about predictability.
Test 3: Long-Context Generation
The picture evens out somewhat for long, multi-paragraph generations with substantial context: Groq still leads on throughput, but the relative gap tends to be less dramatic than on short, latency-sensitive calls — because once you’re streaming a big response, raw tokens-per-second matters more than time-to-first-token, and the absolute time difference, while real, is less of a UX make-or-break. This is worth internalizing: Groq’s edge is largest exactly where latency matters most — short, interactive, real-time exchanges.
I’d add the obvious caveat I always give in my AI Model Performance Metrics write-ups: benchmark your own workload. The shape of your prompts, your context length, your concurrency pattern — all of it moves these numbers around.
Throughput and Cost: The Production Math

Speed is fun in a demo. Cost is what gets your project approved. Groq’s pricing on GroqCloud is pay-per-token and has been competitive with the hyperscalers for the open models it serves — often attractive relative to comparable Llama deployments elsewhere, though exact rates shift over time and you should check the current GroqCloud pricing page before budgeting.
The more interesting economic angle is the indirect cost. Because Groq processes requests so much faster, a single request occupies infrastructure for less time. For high-volume, latency-sensitive workloads, that efficiency can translate into better cost-per-inference at scale than you’d expect from a naive token-price comparison. But — and this matters — for batch jobs where latency is irrelevant, the calculus changes. If you’re running an overnight batch summarizing ten thousand documents and nobody’s waiting on the result, paying any premium for speed is wasted money. In that scenario, the cheapest-per-token option on a sleepy GPU pool might win regardless of throughput.
So the honest framing is this: Groq’s cost story is strongest when speed has business value. When speed is irrelevant, evaluate it purely on token price like anything else. I dig into this trade-off more in my Open-Source LLMs vs Cloud-Based Models comparison, because the build-vs-buy decision overlaps heavily here.
Who Should Actually Use Groq
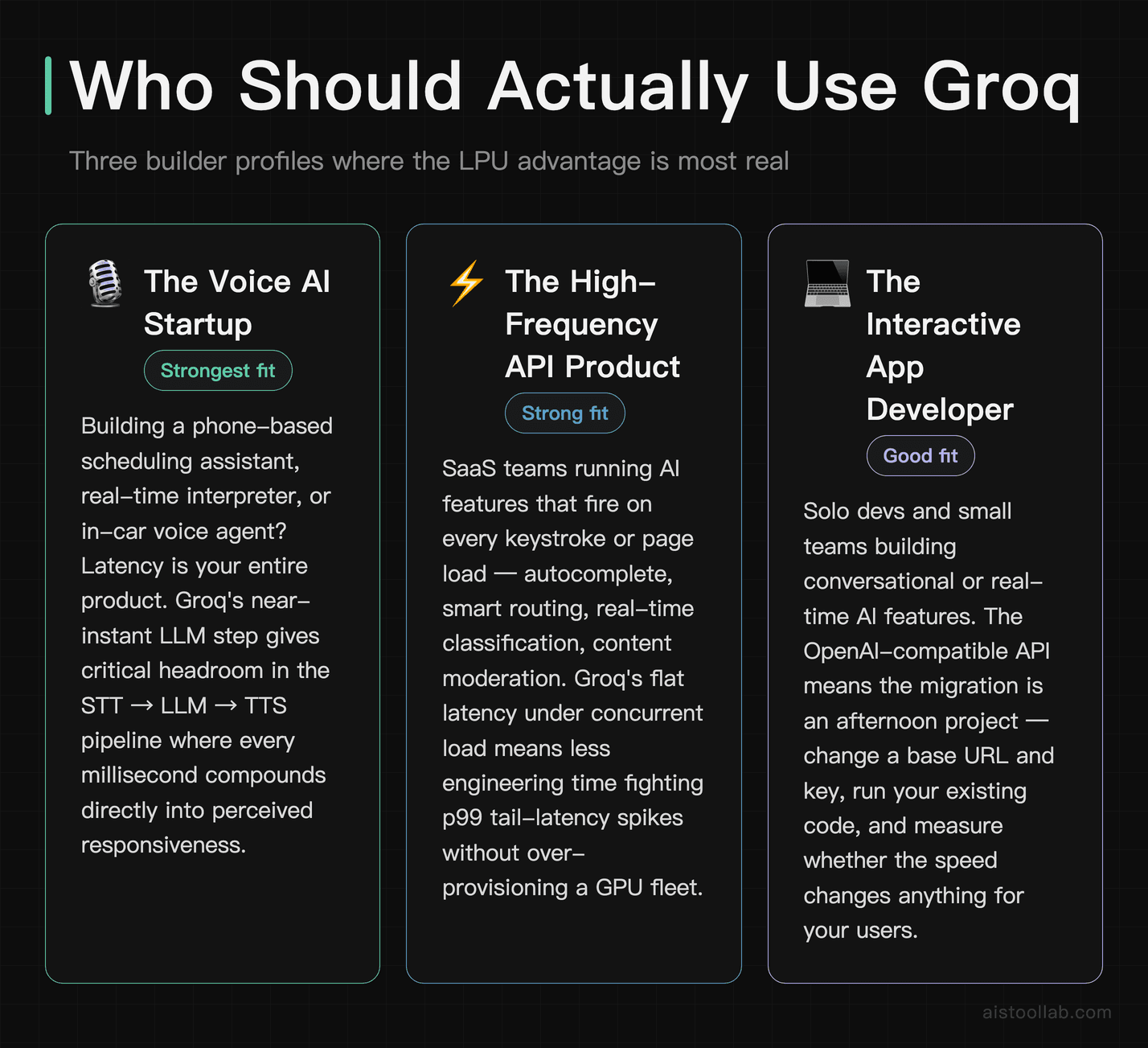
The Voice AI Startup
If you’re building a voice agent — a phone-based scheduling assistant, a real-time interpreter, an in-car assistant — latency is your entire product. Humans notice conversational delay brutally; anything past a certain threshold and the interaction feels robotic and broken. A startup I’d point straight at Groq is any team where the model sits in a speech-to-text → LLM → text-to-speech loop. Shaving the LLM portion down to near-instant gives you headroom in the rest of the pipeline. This is arguably Groq’s single most compelling use case, and it’s where the LPU’s consistency really earns its keep.
The High-Frequency API Product
Picture a SaaS company running an AI feature that fires on every keystroke or every page load — autocomplete, smart routing, real-time classification, content moderation. These are high-frequency, low-latency endpoints where milliseconds compound across millions of calls. A two-person platform team trying to keep p99 latency tight without over-provisioning a GPU fleet will find Groq’s flat latency-under-load behavior a real gift. You spend less engineering time fighting tail-latency gremlins.
The Interactive App Developer
For the solo developer or small studio shipping a consumer-facing AI app — a writing assistant, a coding helper, an interactive tutor — perceived responsiveness is what makes the thing feel premium. Users equate speed with intelligence whether that’s fair or not. If your app streams responses and you want that “wow, it’s fast” reaction during onboarding (when you’ve got about twenty seconds to convince someone to stick around), Groq gives you that for free. It’s the kind of polish that’s hard to retrofit later.
The Batch-Processing Team (a Counter-Example)
I’ll be contrarian here: if your workload is overnight batch inference with no human in the loop, Groq is probably not where you start. Optimize for token price and model fit instead. Groq can still serve you, but you’re paying for a strength you’re not using. Knowing when not to reach for a tool is half the job.
The Honest Pros and Cons

Here’s an unvarnished take.
What’s genuinely great: The speed is not marketing fluff — it delivers one of the fastest inference experiences available, full stop. Latency consistency under load is excellent. The API is OpenAI-compatible, so swapping it into an existing codebase is often a matter of changing a base URL and key, which is a delightfully low-friction migration. For the open models it supports, the price-performance is strong.
What gives me pause: Model selection is curated, not exhaustive — you’re working within Groq’s supported lineup (strong on Llama and Mistral-family open models), not the entire universe of frontier models. If your product depends specifically on, say, the latest Claude or a proprietary OpenAI model, Groq isn’t where you get it; you’d reach for best LLMs comparison territory and the platforms that host those. As a standalone provider, Groq also doesn’t give you the deep VPC, IAM, and compliance integration that a hyperscaler does out of the box — for some regulated enterprises that’s a hard requirement. And as a relative newcomer competing with trillion-dollar cloud giants, the usual platform-maturity questions apply: tooling, regional coverage, and long-term roadmap are still evolving.
Model Coverage and Deployment in 2026
Groq’s strength has consistently been serving popular open-weight models at extreme speed. The lineup centers on Meta’s Llama family and Mistral models, with the platform regularly adding newer open releases as they land. If your strategy is built around open models — which more and more production teams are choosing for cost and control reasons — Groq slots in naturally.
On deployment: the OpenAI-compatible API is the practical hero here. In real terms, if you already have code talking to OpenAI’s SDK, pointing it at Groq is usually trivial. That dramatically lowers the cost of experimentation — you can A/B a portion of your traffic to Groq and measure real latency gains in an afternoon rather than committing to a migration. For production, the standard considerations apply: build in fallback logic to another provider for resilience, monitor your token usage and rate limits, and validate that Groq’s supported model versions match what your prompts were tuned against. Prompt behavior can drift subtly between model versions, so don’t assume a Llama variant on one platform behaves identically to the “same” model elsewhere without testing.
Frequently Asked Questions
Is Groq really 10-20x faster than GPUs?
Independent provider benchmarks back the directional claim — Artificial Analysis ranks Groq fastest for output speed among providers on models like Llama 4 Scout (as of 2026-07), though it does not establish a universal 10–20× figure. Groq’s own marketing has cited order-of-magnitude speedups over traditional GPU inference, and for short, latency-sensitive workloads on Llama-class models, Groq tends to be dramatically faster than GPU-based cloud platforms. That said, a precise “10-20x” multiplier is workload-dependent and you shouldn’t treat it as a universal constant. The gap is largest on time-to-first-token and on high-concurrency short-prompt traffic, where the LPU’s deterministic scheduling shines. On long-context generation, Groq still leads but the relative advantage compresses because absolute generation time matters more than startup latency. My advice: don’t argue about the exact multiplier. Run your actual workload on both and measure your own p50 and p99 latency. The numbers you get will be far more useful for a production decision than any vendor’s headline figure. The speed is real — just calibrate your expectations to your specific use case.
Is there a free tier to try Groq?
Groq offers access through GroqCloud, and historically there’s been a way to experiment without immediately committing budget, plus a public playground to feel out the speed before writing any code. I’d genuinely recommend starting there — the “is this fast enough to matter for my app?” question gets answered within minutes of using the playground, because the speed difference is something you perceive instantly rather than something you need a spreadsheet to detect. For anything beyond casual testing you’ll move to pay-per-token usage. Because the API is OpenAI-compatible, the jump from playground experimentation to a real integration test is short. Check the current GroqCloud documentation for exact free-tier limits and rate caps, as these evolve. The key point is that evaluating Groq is unusually low-effort — you don’t need a sales call or a lengthy POC to know whether the latency improvement is real for your scenario. That low barrier to validation is, honestly, one of the underrated reasons to give it a look even if you ultimately stay on your current platform.
How does Groq compare to AWS Bedrock specifically?
These serve different priorities. Bedrock’s superpower is breadth and integration: a wide catalog of models including Anthropic, Meta, Mistral and others, all wrapped in AWS’s mature IAM, VPC, billing, and compliance machinery. If your infrastructure already lives in AWS, Bedrock is the path of least resistance and the governance story is excellent. Groq’s superpower is raw speed and latency consistency for the open models it serves. In my head-to-head tests on comparable Llama workloads, Groq delivered noticeably lower and more consistent latency, especially under concurrency. So the decision is rarely “which is better” in the abstract — it’s “what does my product need?” A latency-critical, real-time feature leans Groq. A compliance-heavy enterprise app that needs deep AWS integration and a broad model menu leans Bedrock. Plenty of teams actually use both: Groq for the speed-sensitive hot path, Bedrock or another hyperscaler for everything else and for fallback. The OpenAI-compatible API makes that hybrid setup more practical than it sounds.
What models can I actually run on Groq?
Groq focuses on serving popular open-weight models at high speed, with the lineup centered on Meta’s Llama family and Mistral models, plus other open releases the platform adds over time. What you won’t find is proprietary frontier models like the latest GPT or Claude — those are served by their own providers and the hyperscalers that license them. So Groq fits naturally if your strategy is built around open models, which a growing share of production teams choose for cost control and deployment flexibility. Before committing, check Groq’s current model list against your specific needs, because the available versions change as new open models ship. One practical gotcha: a model with the same name can behave slightly differently across platforms depending on quantization, version, and serving configuration. If your prompts were carefully tuned on a particular deployment elsewhere, re-validate them on Groq rather than assuming identical behavior. It’s usually fine, but “usually” isn’t “always,” and prompt regressions are annoying to debug in production.
Does the speed advantage actually matter for my users?
It depends entirely on whether a human is waiting. For interactive, real-time experiences — chatbots, voice agents, autocomplete, live coding assistants — yes, absolutely, and your users will feel it even if they can’t articulate why the app feels “snappier.” There’s a well-understood relationship between responsiveness and perceived quality in interface design; faster systems feel more capable and more trustworthy. For voice especially, where conversational delay breaks the illusion of natural interaction, low latency isn’t a nice-to-have, it’s the product. On the flip side, if your workload is asynchronous — batch processing, scheduled report generation, anything where results land in a queue nobody’s actively watching — the speed advantage delivers no user-facing value, and you should evaluate Groq purely on cost and model fit. The honest test is simple: is someone staring at a loading state waiting for this response? If yes, Groq’s edge is meaningful. If no, treat speed as a tiebreaker at most, not a deciding factor.
Is Groq production-ready for an enterprise?
For latency-critical workloads, the technology itself is production-grade — the speed and consistency are real and dependable in my experience. The nuance for large enterprises is the surrounding platform maturity. The hyperscalers have spent years building out compliance certifications, regional data residency options, granular access controls, and the kind of enterprise procurement and support relationships that big organizations require. Groq, as a younger and more specialized company, is building these out but you should verify that its current compliance posture and regional coverage meet your specific requirements before betting a regulated workload on it. The pragmatic pattern many teams adopt: use Groq for the specific latency-sensitive component where its advantage is decisive, while keeping the broader stack on a platform that already satisfies governance needs, and implement provider fallback for resilience. That hybrid approach lets you capture the speed benefit without taking on platform-maturity risk across your entire system. For a startup without heavy compliance constraints, Groq as a primary provider is far less complicated and often a great fit.
How hard is it to migrate from OpenAI or another provider?
Refreshingly easy, and this is one of Groq’s quietly best features. Because the API is OpenAI-compatible, in many cases migrating means changing the base URL and API key in your existing code — the request and response shapes you’re already handling stay largely the same. That means you can run a low-risk experiment: route a slice of traffic to Groq, measure the latency difference against your current provider, and make a data-driven call rather than a leap of faith. I’d strongly recommend doing exactly this before any commitment. The thing to watch isn’t the API plumbing — that’s smooth — it’s the model behavior. If you’re switching from a proprietary model to an open model on Groq, you’re changing the model itself, not just the host, so expect to revisit your prompts and re-test your outputs. The latency win is straightforward; the output-quality validation is where you should spend your testing effort. Budget an afternoon for the integration and a bit more for prompt re-tuning if you’re also changing models.
What’s the catch — why isn’t everyone using Groq?
Fair question, and there’s no single catch, just trade-offs. The big ones: a curated rather than exhaustive model catalog means it doesn’t serve proprietary frontier models, so products that depend on a specific Claude or GPT model can’t simply switch. As a standalone, specialized provider it lacks the deep native integration and mature enterprise compliance tooling that hyperscalers bundle in, which matters enormously for regulated industries. There’s also inertia — teams already standardized on AWS, GCP, or Azure face real switching friction and may not want another vendor in the mix for a single capability. And for batch or non-interactive workloads, Groq’s headline strength simply isn’t relevant, so those teams have no reason to switch. None of these are flaws in Groq’s core technology, which is genuinely excellent; they’re reasons a given team might not prioritize it. The companies adopting Groq most enthusiastically are exactly the ones whose product lives or dies on real-time latency. If that’s not you, the status quo is comfortable and that’s why many stick with it.
My Verdict
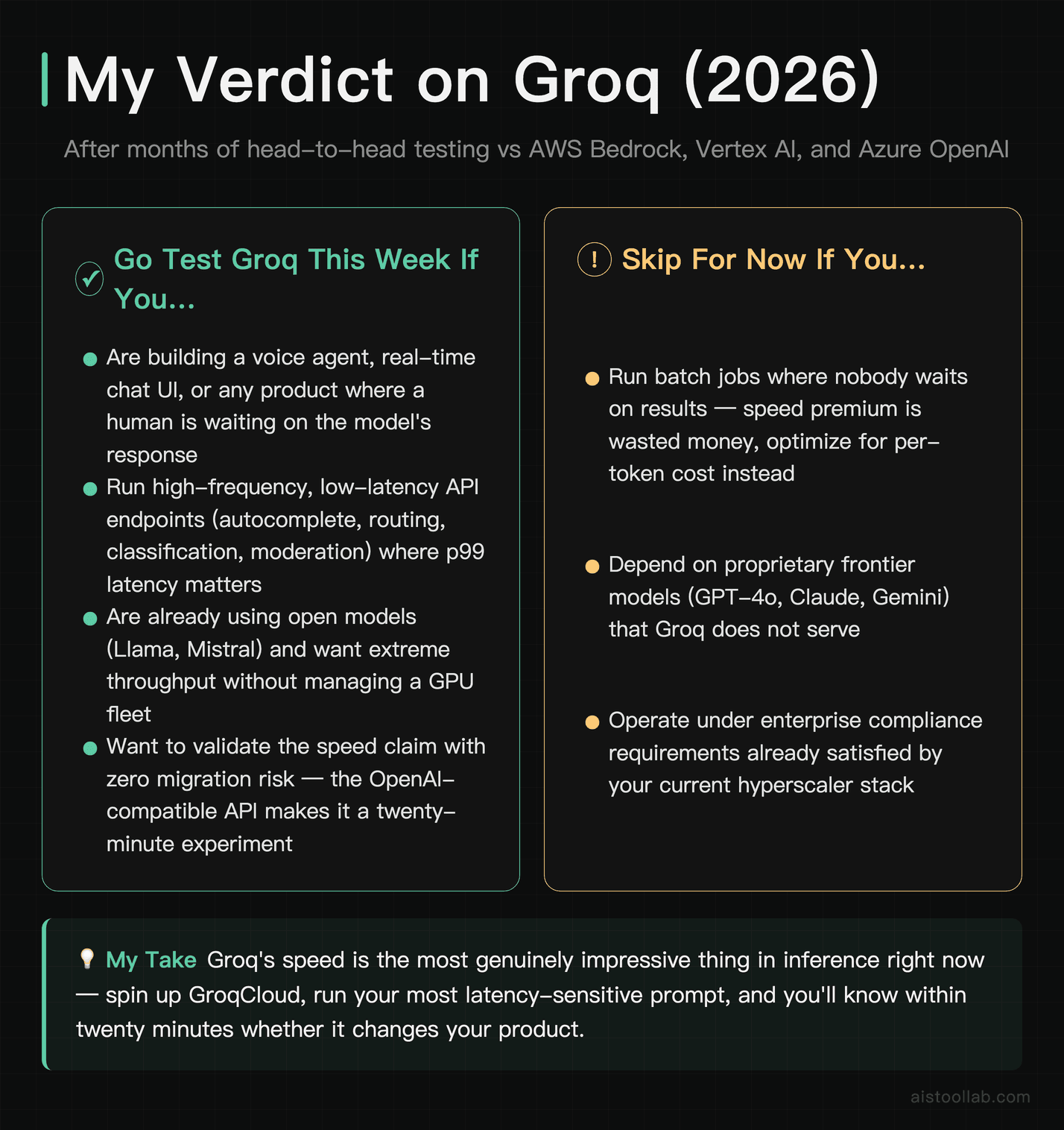
If you’re building anything where a human is waiting on the model — voice agents, real-time chat, interactive assistants, high-frequency low-latency endpoints — go test Groq this week. The speed isn’t a marketing illusion; it’s the most genuinely impressive thing I’ve benchmarked in inference, and the OpenAI-compatible API means validating it costs you an afternoon, not a quarter. The “wow, it’s instant” reaction is real and your users will feel it.
If you’re running batch jobs, depend on proprietary frontier models, or operate under heavy compliance requirements that the hyperscalers already satisfy, Groq is either irrelevant to your bottleneck or an extra dependency you don’t need yet — stick with your current stack and revisit when the situation changes.
Here’s the move I’d make: spin up the GroqCloud playground, throw your most latency-sensitive prompt at it, and watch the response stream. You’ll know within twenty minutes whether the speed changes anything for your product. That’s the cleanest twenty-minute experiment in AI infrastructure right now, and it costs you nothing but curiosity.
Last updated: 2026
Explore more AI tools
👉 Browse the AI Tools Library to find the right tools for your workflow.