The Number That Means Everything and Nothing
Here’s a confession from a decade of writing about AI tools: I used to do the thing everyone does. A new model drops, I scroll straight to the benchmark table, find the MMLU score, and go “ah, 88 percent, that’s the smart one.” Done. Verdict formed in four seconds, somewhere between my first and second sip of coffee.
The problem? That number tells you almost nothing about whether the model will actually help you write a marketing email, debug a gnarly piece of TypeScript, or summarize a 40-page contract without inventing a clause that isn’t there. Models with near-identical MMLU scores can behave like completely different employees — one a careful senior engineer, the other an overconfident intern who’s read the textbook but never shipped code.
So let’s pull these benchmarks apart. What does MMLU actually test? Why does a high HellaSwag score not guarantee the model won’t hallucinate? And in 2026, with agentic systems and multimodal models everywhere, are these decade-old academic tests even measuring the right things anymore? Grab your coffee — this one’s worth the read if you’ve ever stared at a leaderboard and felt vaguely lied to.
Contents
What Each Benchmark Actually Measures (In Plain English)
Every benchmark is a specific exam with a specific format, and understanding the format tells you what the score really means. Treating them as one interchangeable “intelligence” measure is the single biggest mistake I see in Reddit threads and product comparisons.
MMLU — Breadth of Knowledge, Multiple Choice
MMLU (Massive Multitask Language Understanding) spans 57 subjects, from elementary mathematics to US history, law, and college-level biology. It’s a multiple-choice test — the model picks A, B, C, or D. That format matters enormously. A high MMLU score means the model has absorbed a huge breadth of factual and academic knowledge and can recognize the correct answer when it’s sitting right there among four options.
What it does not measure: whether the model can generate that knowledge from scratch in a real conversation, whether it reasons step-by-step, or whether it knows when it doesn’t know. Multiple choice rewards recognition, not generation. A model can ace MMLU and then confidently fabricate a citation when asked the same topic in an open-ended prompt. The exam format flatters them.
HellaSwag — Commonsense Sentence Completion
HellaSwag tests commonsense reasoning by giving the model the start of a scenario (“A woman is outside with a bucket and a dog. The dog is running around trying to avoid a bath. She…”) and asking it to pick the most plausible continuation. The clever bit is that the wrong answers were specifically engineered to fool earlier AI models while being obvious to humans. It’s a test of whether the model understands how the physical, everyday world actually works.
Modern frontier models score very high here — so high that HellaSwag has become somewhat saturated, meaning the top models are bunched near the ceiling and the benchmark no longer separates them well. A 95 versus a 96 here tells you essentially nothing useful.
TruthfulQA — Resisting Plausible Falsehoods
This is my favorite, and the most underrated. TruthfulQA measures whether a model gives truthful answers to questions where humans commonly hold false beliefs or where the internet is full of misinformation. Think questions designed to bait a model into repeating a popular myth. A model can be brilliant at MMLU and still flunk TruthfulQA by confidently parroting something that sounds right but isn’t.
If you care about hallucination and reliability — and if you’re using AI for anything client-facing, you absolutely should — TruthfulQA is far more predictive of real-world headaches than raw knowledge scores.
MATH and GSM8K — Multi-Step Reasoning
The MATH benchmark uses competition-level math problems that require genuine multi-step reasoning, not just recall. GSM8K covers grade-school word problems but still demands chained logic. These benchmarks are useful proxies for a model’s ability to hold a problem in working memory and reason through it sequentially — which correlates loosely with how well it handles complex coding tasks and structured analysis.
ARC — Grade-School Science Reasoning
The ARC (AI2 Reasoning Challenge) consists of grade-school science questions split into an “easy” and a “challenge” set, where the challenge questions resist simple retrieval and keyword matching. It rewards models that can combine facts and reason rather than pattern-match. It’s older now, and like HellaSwag, the top models have largely flattened it out.
Why High Scores Don’t Always Mean Good in the Real World
This is the heart of it. Benchmark scores and real-world usefulness are correlated, but the correlation is much weaker than the marketing slides suggest. Here’s why the gap exists.
Contamination is real. Many of these benchmarks have been around for years, which means their questions — and answers — have almost certainly leaked into training data scraped from the web. When a model has effectively “seen the test before,” its score reflects memorization, not capability. Researchers have flagged data contamination as a serious and growing problem in LLM evaluation, and it’s one reason scores keep climbing while real-world improvements feel more incremental.
The format mismatch. Almost nobody uses an AI by handing it four multiple-choice options. Real work is open-ended: “Rewrite this in our brand voice,” “Find the bug,” “Plan this project.” A model optimized to pick the right letter isn’t necessarily optimized to generate genuinely useful long-form output, maintain context across a 20-message conversation, or follow nuanced instructions.
Benchmarks don’t measure the things you feel. Latency. Tone. How it handles ambiguity. Whether it asks a clarifying question instead of charging ahead with a wrong assumption. Refusal behavior. How gracefully it admits uncertainty. None of these show up in a single benchmark number, yet they’re often what makes one model a joy to use and another a chore. I dug into this trade-off more in my Open LLM Leaderboard Review 2026, where the rankings shuffle dramatically depending on which axis you weight.
How to Actually Read a Leaderboard
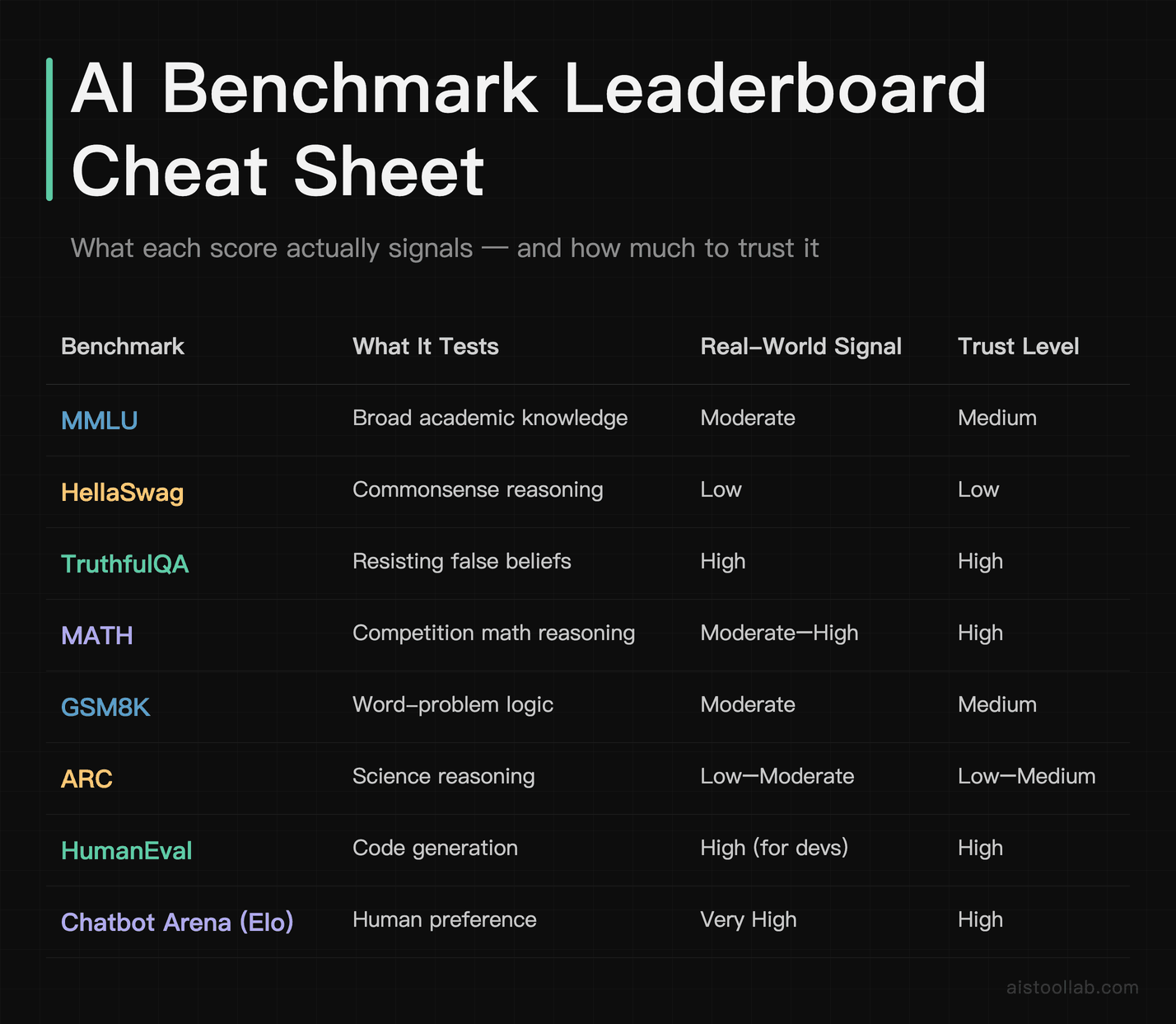
My rule of thumb: never judge a model on one number. Cross-reference at least three — ideally one knowledge benchmark (MMLU), one reasoning benchmark (MATH or HumanEval), and one human-preference signal (something like the LMSYS Chatbot Arena, where real people vote blind on which of two anonymous responses is better). When all three agree, you’ve got a reliable signal. When they diverge wildly, the model probably has a spiky profile — great at one thing, weak at another — and you need to test it on your specific task.
The 2026 Shift: Beyond Academic Trivia

The genuinely interesting development is that the field has finally admitted the old benchmarks are running out of road. Several trends are reshaping how we evaluate models this year, and they map much more closely to how people actually use AI.
Agentic task evaluation. As models graduate from chatbots to agents that take multi-step actions — browsing, calling APIs, editing files — the question shifts from “did it pick the right answer?” to “did it complete the task?” Newer benchmarks evaluate end-to-end task completion: can the agent book the flight, fix the failing test suite, or research and compile the report? This is messy to score but far more honest. I went deep on how these systems work in my piece on Agentic AI Systems Explained, and the evaluation problem is one of the hardest parts of the whole field.
Multimodal benchmarks. With vision-language models now mainstream, text-only benchmarks miss half the picture — literally. Newer evaluations test whether a model can read a chart, interpret a diagram, reason about a screenshot, or answer questions about an image. If you’re picking a model for anything involving documents, design, or UI, the text benchmarks are nearly irrelevant. I unpacked the mechanics in Vision Language Models Explained.
Domain-specific and private evals. The smartest teams I talk to have stopped trusting public leaderboards entirely for procurement decisions. Instead they build small, private evaluation sets — 50 to 200 prompts that look exactly like their real work — and score candidate models against those. It’s the only way to dodge contamination and measure what actually matters to your business. A legal team’s eval looks nothing like a game studio’s, and that’s the point.
Who Should Care About Which Metrics
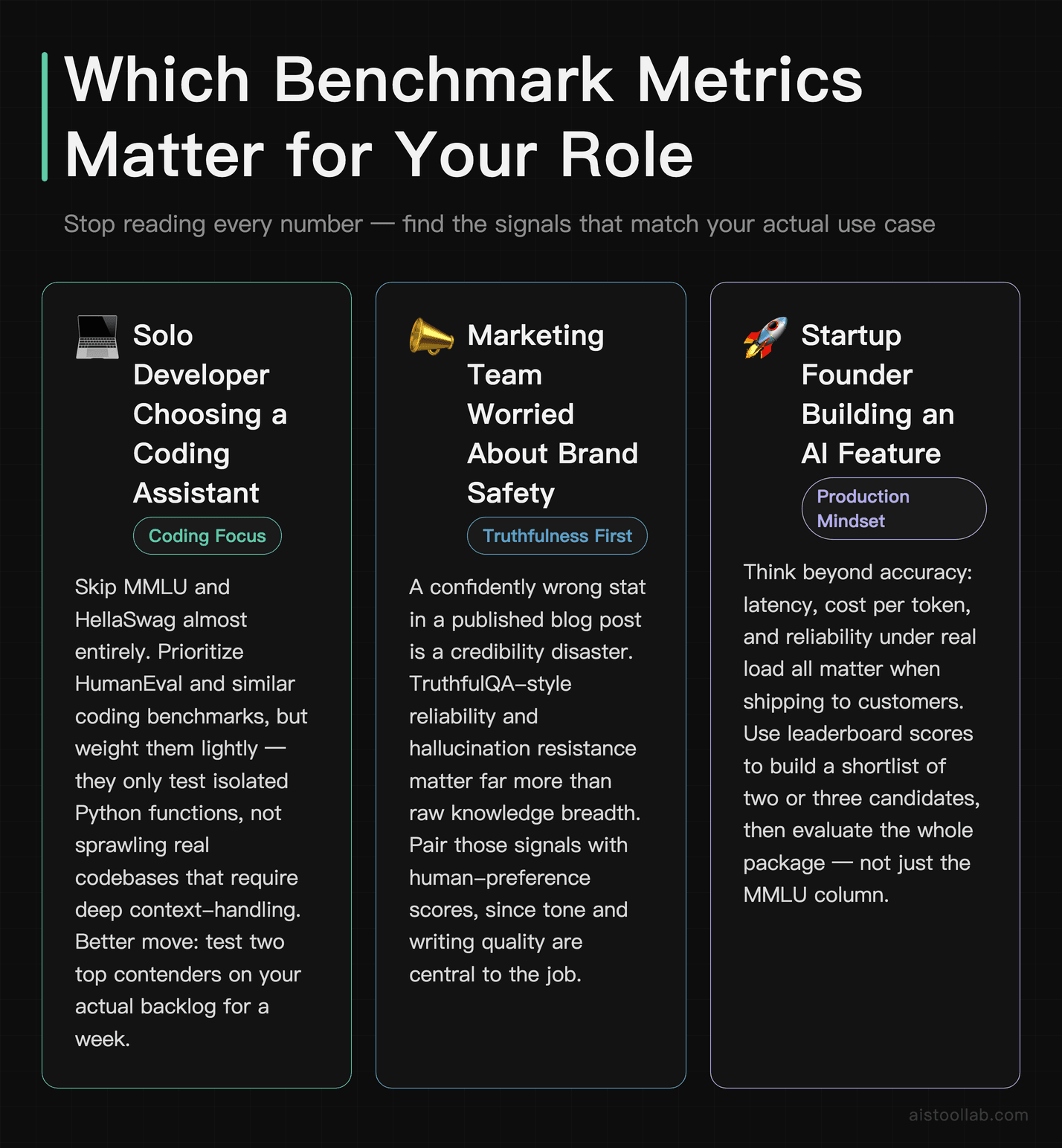
The Solo Developer Choosing a Coding Assistant
If you’re a freelance developer juggling three client projects, ignore MMLU and HellaSwag almost entirely. Look at HumanEval and similar coding benchmarks, but weight them lightly — they test isolated Python functions, not your sprawling React codebase. The better move is to take two top contenders and run them on your actual backlog for a week. Real-world coding ability diverges from benchmark scores more than in almost any other category, because real codebases require context-handling that no benchmark captures.
The Marketing Team Worried About Brand Safety
A two-person SaaS marketing team publishing AI-assisted content cares most about one thing benchmarks rarely headline: truthfulness. A confidently wrong stat in a published blog post is a credibility disaster. For this crowd, TruthfulQA-style reliability and the model’s willingness to hedge matter more than raw knowledge breadth. Pair that with human-preference scores, since tone and writing quality are central to the job.
The Startup Founder Building an AI Feature
If you’re shipping an AI feature to customers, you need to think about the whole package — latency, cost per token, refusal rates, and consistency under load — none of which appear on a knowledge leaderboard. I’d start with the Chatbot Arena Elo as a sanity check on overall quality, then build a private eval against your specific use case. The benchmark number that matters is the one you measure on your own data. For a worked example of how price and performance trade off, my best LLMs comparison breakdown lays out where each model earns its keep.
Frequently Asked Questions
Is a higher MMLU score always better?
Not really, and this trips up a lot of people. A higher MMLU score means the model recognizes more correct answers across a broad range of academic subjects — but it’s a multiple-choice format, so it rewards recognition rather than the open-ended generation you’ll actually use day to day. Two models can sit within a point or two of each other on MMLU and behave completely differently in practice: one might reason carefully and admit uncertainty, the other might hallucinate confidently. MMLU also suffers from likely data contamination, since the test has been public for years and almost certainly appears in training sets. So treat a high MMLU as a positive signal about knowledge breadth, but never as a verdict on overall capability. Always cross-reference it with a reasoning benchmark and a human-preference score before drawing conclusions. The single biggest mistake I see is people treating one MMLU number as a model’s “IQ” — it isn’t, and the gap between recognition and real generation can be enormous.
What’s the difference between MMLU and HellaSwag?
They measure fundamentally different things even though both use a multiple-choice format. MMLU tests breadth of academic and factual knowledge across 57 subjects — it asks whether the model knows things. HellaSwag tests commonsense reasoning about everyday situations — it asks whether the model understands how the ordinary physical and social world works, by having it choose the most plausible continuation of a scenario. A model could theoretically know a lot of college-level facts (high MMLU) while still occasionally botching basic commonsense (lower HellaSwag), though in practice frontier models tend to do well on both. The more important practical difference in 2026 is that HellaSwag has become saturated — the top models are all bunched near the ceiling, so it no longer separates them meaningfully. MMLU still has a bit more room to differentiate, but it too is approaching its limit. If you’re comparing modern frontier models, HellaSwag scores are largely noise; focus your attention on benchmarks that still produce a meaningful spread between contenders.
Why do models score differently on different leaderboards?
Several reasons, and understanding them saves you a lot of confusion. First, leaderboards use different prompting setups — some give the model examples before the test questions (few-shot), others don’t (zero-shot), and that alone can swing scores by several points. Second, they may use different versions of a benchmark or different scoring methods, especially for open-ended tasks where a judge model or human grades the output. Third, some leaderboards measure human preference (like blind head-to-head voting) while others measure accuracy on fixed tests, which capture genuinely different qualities. Fourth, the exact model version matters — a provider might update a model silently, so the “same” model tested at different times isn’t really the same. My advice: don’t try to reconcile exact numbers across leaderboards. Instead, look at the relative ordering within a single leaderboard and trust consistency across multiple independent sources. If a model ranks near the top on several different evaluation methodologies, that’s a far stronger signal than one impressive number on a single board.
Can benchmark scores be gamed or inflated?
Yes, and this is one of the most under-discussed problems in the field. The most common form is data contamination — when benchmark questions and answers end up in a model’s training data, the model effectively memorizes the test rather than demonstrating genuine capability. Because most popular benchmarks have been public for years, this contamination is widespread and hard to fully prevent. There’s also the more deliberate concern that a lab could fine-tune specifically to perform well on known benchmarks, optimizing for the test rather than real usefulness — a phenomenon researchers compare to “teaching to the test” in education. This is exactly why private, held-out evaluation sets have become so important in 2026: if you build your own test from prompts that resemble your real work and have never been published, no model could have trained on them. I always recommend treating any single benchmark number with healthy skepticism, especially round, impressive figures that appear right around a launch. The defense is cross-referencing multiple independent evaluations and, ideally, testing on your own data.
Which benchmark best predicts real-world usefulness?
If I had to pick one, it would be human-preference evaluations like the LMSYS Chatbot Arena, where thousands of real people vote blind on which of two anonymous responses they prefer. Because it captures the messy, subjective qualities that matter in actual use — helpfulness, tone, instruction-following, reasoning — it correlates with real-world satisfaction better than any single academic test. That said, it has its own biases: it can reward responses that are longer or more confident-sounding regardless of correctness, and popular models attract more votes. So even the best single predictor isn’t perfect. For specific domains, the most predictive benchmark is the one closest to your task — HumanEval for coding, MATH for quantitative reasoning, TruthfulQA for factual reliability. The honest answer is that no public benchmark predicts your real-world usefulness as well as a small private eval built from your own prompts. Public benchmarks narrow the field; your own testing makes the final call.
Are old benchmarks like ARC and HellaSwag still useful in 2026?
They’re useful as a sanity check, not as a differentiator. Both ARC and HellaSwag have become largely saturated — today’s frontier models cluster near the top, so the gap between a 94 and a 96 is mostly noise rather than a meaningful capability difference. Where they still earn their keep is at the lower end: if a smaller or open-weight model scores poorly on these, that’s a genuine red flag about its basic reasoning. So for evaluating budget models, fine-tunes, or experimental open-source releases, they retain some diagnostic value. For comparing the leading commercial models, they’re effectively retired. This pattern — benchmarks becoming saturated and then obsolete as models improve — is exactly why the field keeps inventing harder tests. It’s an arms race: every time a benchmark gets “solved,” researchers build a tougher one to restore the ability to discriminate between top models. The lifecycle of a benchmark from challenging to saturated to obsolete has been getting shorter, which tells you something about the pace of improvement.
How do multimodal benchmarks differ from text benchmarks?
Text benchmarks like MMLU and TruthfulQA only test what a model can do with words — they’re blind to images, charts, diagrams, and screenshots. Multimodal benchmarks evaluate whether a model can perceive and reason about visual information alongside text: reading a graph and answering questions about the trend, interpreting a UI mockup, extracting data from a table image, or describing what’s happening in a photo. As vision-language models became standard, these evaluations grew essential because a huge chunk of real work involves visual context — think analyzing a dashboard, reviewing a design, or parsing a scanned document. A model can have stellar text benchmark scores and still struggle to read a simple chart correctly. If your use case touches anything visual, text-only benchmarks are nearly useless for your decision, and you should prioritize multimodal evaluations instead. The field is still maturing here — multimodal benchmarks are newer, less standardized, and more prone to inconsistency between leaderboards — so treat the scores as directional rather than precise.
Should I trust benchmarks or just test models myself?
Both, in that order. Benchmarks are excellent for narrowing the field quickly — they tell you which models are roughly in the right tier and save you from testing a dozen options. But they should never make the final decision for anything you’re betting real money or reputation on. The reason is simple: benchmarks measure general capability on standardized tasks, while you care about performance on your specific task with your data, tone, and constraints. The gap between those two can be large and unpredictable. A reliable workflow is to use public leaderboards to pick two or three finalists, then build a small private eval — even just 30 to 50 prompts that mirror real work — and run each finalist against it. Score them on the dimensions that actually matter to you, which often includes things benchmarks ignore entirely, like latency, cost, and refusal behavior. You’ll usually know within an afternoon which model fits. Benchmarks get you to the shortlist fast; trying the models on your own tasks makes the call.
The Bottom Line on Benchmark Scores
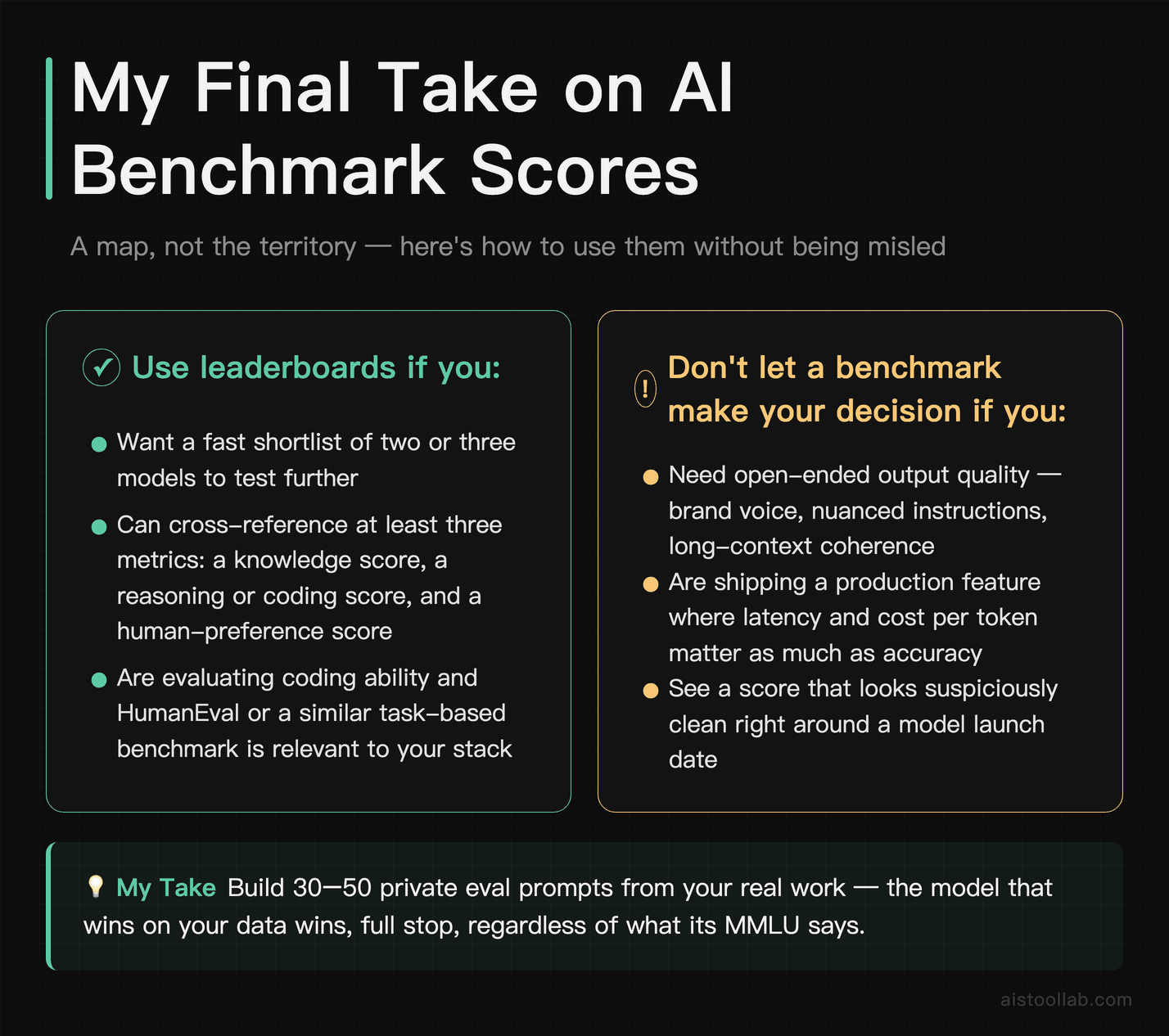
If it were my money and my product on the line, here’s exactly what I’d do: use the public leaderboards to build a shortlist of two or three models, and cross-reference at least three different metrics — a knowledge benchmark, a reasoning or coding benchmark, and a human-preference score — rather than fixating on a single number. Then I’d ignore the leaderboards entirely and build a private eval from 30 to 50 prompts that look exactly like my real work. The model that wins on my data wins, full stop, regardless of what its MMLU says.
Benchmarks aren’t useless — they’re just badly misunderstood. They’re a map, not the territory. MMLU tells you about knowledge breadth, TruthfulQA flags hallucination risk, MATH signals reasoning depth, and human-preference scores capture the feel of actually using the thing. Read them together, distrust any number that looks too clean right around a launch, and never let a leaderboard make a decision you could make better with an afternoon of testing your own use case. The scores point you in a direction. Your own eyes confirm the destination.
Last updated: 2026
Explore more AI tools
👉 Browse the AI Tools Library to find the right tools for your workflow.
Related reading: AI Model Latency in 2026: How to Read Inference-Speed Benchmarks (TTFT, p95 and the Metrics That Matter)