Who this is for: you already know roughly what MMLU and HellaSwag test, and you want to know why the numbers stopped separating models — plus which newer suites replaced them.
Around this particular problem:
- Benchmark basics — what each classic exam actually asks, in plain English
- Benchmarks mapped to roles — which numbers matter for your particular job
- The benchmarks themselves, ranked — which suites still have discriminating power
Contents
The Dirty Secret About AI Leaderboards: Most of Them Are Measuring 2020
Here’s something that should bother you more than it probably does. When a model maker announces “state-of-the-art performance” and waves a chart at you, there’s a decent chance the headline number comes from a benchmark designed before GPT-3 was a household name. MMLU — the metric everyone still quotes — was published in 2020. HellaSwag is from 2019. We’re evaluating 2026’s reasoning-heavy frontier models with rulers built for a different era of AI.
And the rulers are running out of room. Several top-tier models now cluster in the high-80s to low-90s on MMLU, which sounds impressive until you realize that when everyone scores 89, 90, and 91, the benchmark has basically stopped telling you anything useful. A one-point gap could be noise, contamination, or genuine capability — and you have no way to tell which. This is the “ceiling effect,” and it’s quietly turning a lot of leaderboard rankings into coin flips.
So the real question for 2026 isn’t “which model has the highest MMLU?” It’s “which benchmarks actually discriminate between good and great models for the thing I’m building?” Because MMLU, MATH, HellaSwag, and TruthfulQA each measure genuinely different capabilities — and picking the wrong one to optimize for is how teams end up shipping a chatbot that aces trivia but confidently invents your refund policy. Let’s break down what each one really measures, where they fail, and how to assemble a benchmark stack that won’t lie to you.
The Ceiling Problem: Why High Scores Create Ranking Chaos

Once multiple models pile up near the top of a benchmark, ranking by that benchmark becomes statistical theater. If three models score 90.1%, 90.4%, and 90.9% on MMLU, the differences are well within the range you’d expect from prompt formatting, few-shot example choice, or even benchmark contamination — where test questions have leaked into training data.
This creates a genuinely misleading dynamic: a model that “wins” MMLU by a hair might lose badly on MATH or a hard reasoning suite, yet the marketing only shows you the favorable chart. I’ve seen models that dominate knowledge benchmarks underperform on instruction-following and multi-step reasoning, and vice versa. Ranking on any single saturated benchmark gives you a confident-sounding number that predicts almost nothing about real-world behavior. I dug into this dynamic more in MMLU vs GPQA vs GSM8K, where the same models reshuffle dramatically depending on which test you run.
The fix isn’t a better single benchmark — it’s a portfolio. Newer, harder benchmarks like GPQA (graduate-level, “Google-proof” science questions) and instruction-following suites have far more headroom, so they actually separate the leaders. When you see a model that’s strong across a spread of unsaturated benchmarks, that’s a far more trustworthy signal than a chart-topping number on one tired metric. If you want a deeper methodology walkthrough, my piece on How to Evaluate AI Model Performance Like a Pro covers how to read these spreads without getting fooled.
Side-by-Side: How These Benchmarks Compare
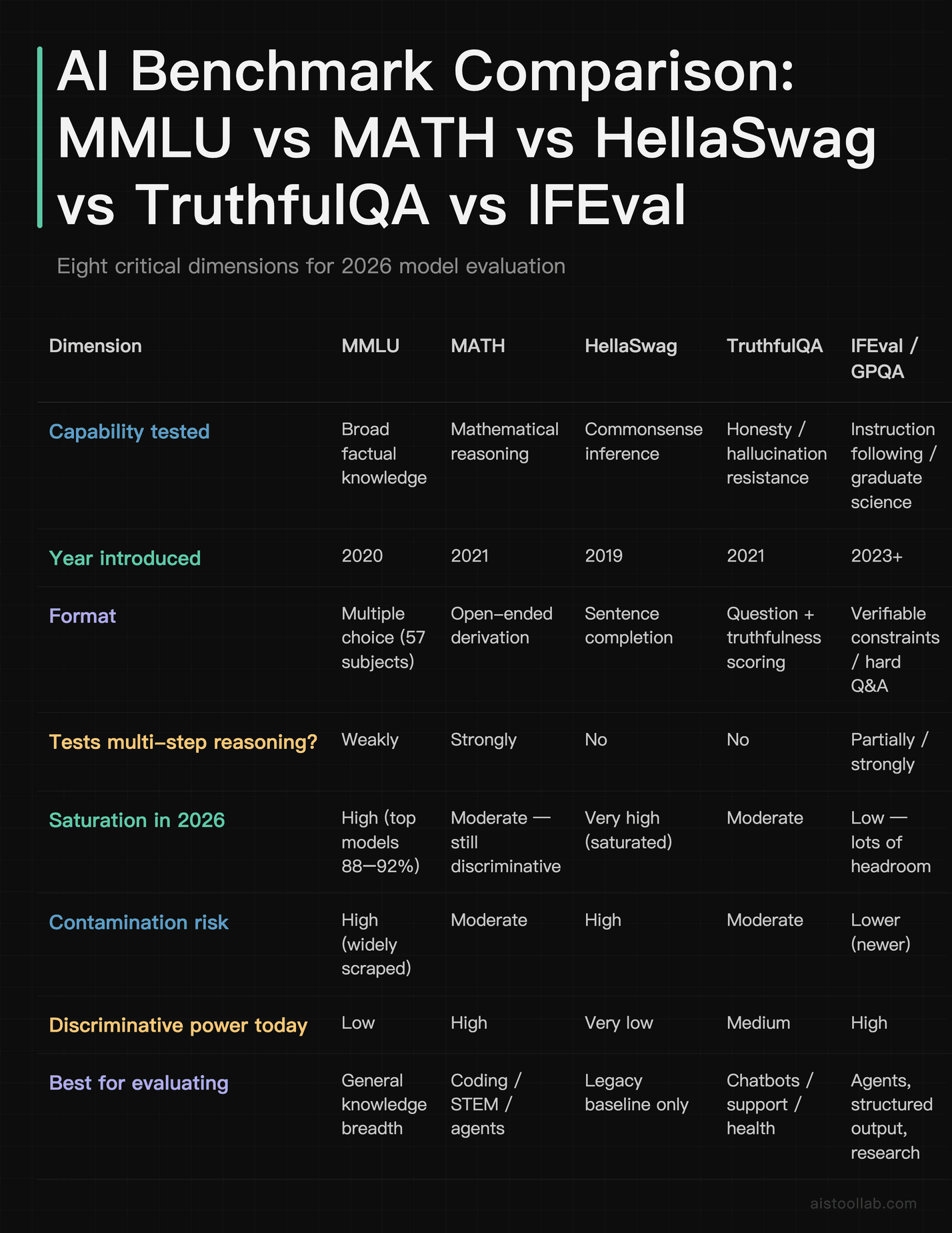
Notice the pattern: the older the benchmark, the more saturated and contaminated it tends to be, and the less it tells you in 2026. That doesn’t make MMLU worthless — it’s still a reasonable sanity check for general knowledge — but it should be a supporting actor, not the star of your evaluation.
What Each Benchmark Actually Tests (They’re Not Interchangeable)

The biggest mistake I see in Reddit threads and procurement docs alike is treating benchmarks as a single “intelligence score.” They’re not. Each one probes a distinct capability, and a model can be a genius on one and mediocre on another.
MMLU (Measuring Massive Multitask Language Understanding) is a broad factual knowledge test. Introduced by Hendrycks and colleagues in 2020, it spans 57 subjects — everything from elementary math to law, medicine, and moral philosophy — in a multiple-choice format. What it really measures is recall and breadth: does the model know a lot of stuff across many domains? What it does not measure well is multi-step reasoning, because multiple choice lets a model pattern-match its way to an answer without genuinely working through a problem.
MATH (also from Hendrycks et al., 2021) is a different beast entirely. It contains competition-level math problems requiring genuine step-by-step derivation, not recall. A model can know every historical date in MMLU and still face-plant on MATH because it can’t sustain a chain of reasoning. This is why MATH — and increasingly competition sets like AIME — have become the go-to discriminators for the “reasoning model” generation.
HellaSwag (Zellers et al., 2019) tests commonsense inference through sentence completion. Given a everyday scenario, the model picks the most plausible continuation. It was deliberately built with adversarial filtering so that wrong answers look superficially reasonable. The catch: modern frontier models have largely saturated it, scoring in the mid-90s, so its power to separate today’s best models is mostly spent.
TruthfulQA (Lin et al., 2021) is the odd one out and arguably the most underrated. Instead of rewarding knowledge, it actively tries to bait the model into repeating common human misconceptions and falsehoods. It measures honesty and resistance to confidently stated nonsense — which, for any customer-facing application, matters more than trivia mastery. A high MMLU model with a weak TruthfulQA score is exactly the kind of system that hallucinates with total confidence.
The 2026 Benchmarks Filling the Gaps

As the classics saturate, a newer generation has stepped in to measure things that actually trip up modern models.
IFEval (Instruction-Following Evaluation), introduced by Google researchers in 2023, is one of the most practically useful. Instead of testing knowledge, it checks whether a model follows verifiable instructions — “respond in exactly three bullet points,” “include the word ‘banana’ twice,” “write at least 400 words.” This matters enormously for production work because a model that’s brilliant but ignores your formatting constraints is a nightmare to build on top of. IFEval has real headroom, so it separates models that MMLU lumps together.
LLMBar is a meta-evaluation benchmark aimed at how well LLMs can judge whether outputs actually follow instructions — useful in the increasingly common “LLM-as-judge” evaluation pipelines. To my knowledge it’s more about discriminating genuine instruction adherence from superficially attractive but wrong responses than a pure factuality test, so treat any “factuality score” framing with caution and check the original methodology before quoting it.
Domain-specific benchmarks are the other big 2026 trend. Medical (MedQA-style), legal, and coding-specific suites like SWE-bench (which tests whether a model can resolve real GitHub issues) are increasingly cited alongside general metrics. These matter because general knowledge scores routinely fail to predict performance on specialist tasks — a point I unpack in Production vs Synthetic, where lab benchmarks and real deployments diverge sharply.
How to Choose Benchmarks for Your Actual Use Case

Building a coding tool or autonomous agent
Weight MATH and AIME-style reasoning benchmarks heavily, and add a coding-specific suite like SWE-bench or HumanEval. Code generation and agentic workflows live or die on sustained multi-step reasoning — exactly what MMLU fails to capture. A model that tops knowledge charts but stumbles on MATH will write code that compiles but logically falls apart on the third step. For a startup shipping a developer-facing assistant, MATH/AIME plus a code benchmark is your core signal; MMLU is a footnote.
Running a customer-facing chatbot or support assistant
TruthfulQA and instruction-following (IFEval) should dominate your scorecard. The failure mode that wrecks support bots isn’t ignorance — it’s confident invention. A model that hallucinates a return window or fabricates a policy will cost you trust and tickets. Here, a strong TruthfulQA score and reliable adherence to system-prompt guardrails matter far more than whether the model knows obscure history. A SaaS company with a two-person support team should screen primarily on honesty and instruction compliance.
Doing research or making a procurement decision
Track at least four metrics across distinct capabilities — say, MMLU for breadth, MATH for reasoning, TruthfulQA for honesty, and IFEval for controllability. The reason is anti-gaming: optimizing for a single benchmark is easy to fake (intentionally or through contamination), but it’s very hard to game four orthogonal ones at once. If a model wins on all four, you’ve got real signal. If it wins on one and lags the rest, you’ve found marketing. For anyone comparing open and closed options, my breakdown in Open-Source LLMs vs Cloud-Based Models shows how this multi-metric approach changes the verdict.
Frequently Asked Questions
Is MMLU still worth paying attention to in 2026?
Yes, but with sharply lowered expectations. MMLU remains a useful sanity check — if a model scores poorly on it, that’s a genuine red flag about broad knowledge gaps. The problem is at the top of the range, where frontier models cluster in the high-80s to low-90s and the differences between them become statistically meaningless. At that level, a higher MMLU number tells you almost nothing about which model will actually perform better on your task. Treat it as a floor test (“does this model know enough general stuff?”) rather than a ranking tool. The other concern is contamination: because MMLU has been publicly available since 2020, large chunks of it have likely been scraped into training datasets, which can inflate scores without reflecting real capability. Use it alongside newer, less-contaminated benchmarks rather than as your headline metric, and never make a model decision based on MMLU alone.
Why do models that win MMLU sometimes lose on reasoning tasks?
Because they’re measuring fundamentally different things. MMLU is multiple choice, which means a model can pattern-match to the most plausible-looking option without genuinely reasoning through the problem. Reasoning benchmarks like MATH and AIME are open-ended — the model has to construct a correct multi-step derivation with no answer choices to anchor on. A model heavily optimized for knowledge recall and answer-matching can ace MMLU while lacking the sustained logical chaining that hard math and coding require. This is exactly why the “reasoning model” generation of 2026 is benchmarked on MATH and competition math rather than MMLU — those tests have the headroom to show real differences. The practical takeaway: never assume a high knowledge score implies strong reasoning. If your application involves multi-step logic, coding, or planning, you must look at reasoning-specific benchmarks, because the correlation between knowledge breadth and reasoning depth is much weaker than most leaderboard charts suggest.
What is the benchmark “ceiling effect” and why does it cause problems?
The ceiling effect happens when a benchmark gets so easy for top models that they all bunch up near the maximum possible score. When several models all hit 90%+ on MMLU or mid-90s on HellaSwag, the remaining gaps are tiny — often smaller than the variation you’d get just from changing the prompt format or the few-shot examples. At that point, ranking models by that benchmark is basically measuring noise. The danger is that these noisy rankings get presented as meaningful: a model marketed as “#1 on MMLU” might be statistically tied with five others, or might actually be worse on tasks you care about. The fix is to use benchmarks with genuine headroom — newer, harder suites like GPQA or IFEval where top models still score well below the ceiling and real differences emerge. Always check how saturated a benchmark is before trusting a ranking based on it; a one-point lead on a saturated test is meaningless.
Does a high TruthfulQA score mean a model won’t hallucinate?
Not entirely — it’s a strong signal, not a guarantee. TruthfulQA specifically tests resistance to common human misconceptions and the tendency to repeat popular falsehoods, so a high score indicates the model is good at not parroting widely believed myths. But hallucination is broader than that. A model can do well on TruthfulQA and still fabricate details when asked about your specific product, recent events, or niche domains it has no real knowledge of. TruthfulQA doesn’t test those situations. For production reliability, you should combine a strong TruthfulQA score with retrieval-augmented generation, domain-specific evaluation, and real-world testing on your own data. Think of TruthfulQA as evidence the model has good honesty instincts — it won’t confidently tell you that a popular myth is true — but not as proof it knows the boundaries of its own knowledge in your specific context. Pair it with grounding techniques for anything customer-facing.
What’s the difference between IFEval and the older benchmarks?
IFEval measures something the classics largely ignore: whether a model actually follows your instructions. Introduced by Google researchers in 2023, it uses verifiable constraints — things a script can objectively check, like “respond in exactly three paragraphs,” “include this specific keyword,” or “do not use the letter e.” This is valuable because in real applications, a model that’s smart but disobeys your formatting and constraint requirements is genuinely hard to build on. MMLU, MATH, and HellaSwag all measure capability in isolation; IFEval measures controllability, which is what determines whether you can reliably wire the model into a pipeline. Crucially, IFEval still has significant headroom in 2026 — models don’t all max it out — so it actually discriminates between leaders. If you’re building structured outputs, agents, or anything where the model needs to obey precise rules, IFEval is far more predictive of real performance than any of the legacy knowledge benchmarks, and it deserves a prominent spot on your evaluation scorecard.
How many benchmarks should I look at before choosing a model?
For a serious decision, at least four, chosen to cover distinct capabilities rather than four versions of the same thing. A good default spread is one knowledge benchmark (MMLU), one reasoning benchmark (MATH or AIME), one honesty benchmark (TruthfulQA), and one instruction-following benchmark (IFEval). The reason for diversity is anti-gaming: it’s relatively easy for a single benchmark to be inflated through contamination or targeted optimization, but very difficult to fake strong performance across four orthogonal capabilities simultaneously. A model that’s consistently strong across all four gives you genuine confidence; one that spikes on a single metric while lagging elsewhere is showing you a marketing story, not a capability profile. If your use case is specialized — medical, legal, coding — add a domain-specific benchmark on top. And whatever the public numbers say, finish your evaluation with a small test on your own real data, because lab scores and production behavior diverge more often than vendors admit.
Is benchmark contamination a real problem or just theoretical?
It’s real and increasingly significant, especially for older benchmarks. Contamination occurs when benchmark questions and answers end up in a model’s training data, so the model effectively “memorized the test.” Because MMLU and HellaSwag have been publicly available for years and widely scraped across the web, there’s a genuine risk that frontier models have seen substantial portions of them during training, which inflates scores without reflecting real generalization. This is one of the strongest arguments for prioritizing newer benchmarks — they’ve had less time to leak into training corpora. Researchers try to detect contamination by testing models on freshly created variants of questions and watching for score drops, and some maintain private or rotating test sets specifically to avoid the problem. As a practical matter, treat suspiciously high scores on old, widely available benchmarks with skepticism, and give more weight to recent benchmarks, private evaluations, and your own held-out test data. Contamination is exactly why a single impressive number should never close a model decision on its own.
Which benchmark matters most if I can only check one?
There’s no universal answer — it depends entirely on what you’re building, which is sort of the whole point of this article. But if someone forced me to pick the single most generally useful benchmark for 2026 production work, I’d lean toward IFEval or a reasoning benchmark like MATH over the knowledge classics, because controllability and reasoning are the capabilities that most often determine whether a deployment succeeds. For a customer-facing chatbot specifically, I’d swap in TruthfulQA, since confident hallucination is the failure that does the most damage there. The honest reality is that any single benchmark is a compromise — each one is blind to capabilities the others measure. If you only have time to check one, check the one that maps most directly to your dominant failure mode: reasoning for coding tools, honesty for support bots, instruction-following for agents. Then, when you have more time, expand to the full four-metric spread before committing real money or engineering effort.
The Verdict: Stop Chasing Single Numbers

If it were my money and my engineering hours on the line, here’s how I’d play it. I’d stop treating MMLU as a scoreboard and start treating it as a floor check. I’d weight my evaluation toward benchmarks that still have headroom — MATH and AIME for anything reasoning-heavy, IFEval for controllability, TruthfulQA for anything users talk to directly — and I’d add a domain-specific suite whenever my use case is specialized. Then I’d finish with a small test on my own data, because the gap between leaderboard glory and real-world reliability is where most disappointed teams end up.
The benchmarks aren’t lying to you, exactly. They’re just answering questions you may not have asked. MMLU tells you what a model knows, MATH tells you whether it can think, HellaSwag tells you whether it understands everyday situations, and TruthfulQA tells you whether it’ll lie to your customers with a straight face. Pick the ones that match your actual risk, ignore the saturated headline charts, and you’ll make far better decisions than anyone ranking models by a single high number. Next step: pull the benchmark spread for your two or three shortlisted models, line them up across these four capabilities, and watch how quickly the “obvious winner” gets complicated.
Last updated: 2026
Found this review helpful?
👉 Browse the AI Tools Library to find the right tools for your workflow.
Related reading: Prime Number Checker Tools Explained: How AI Verifies Primes and Why It Matters for Beginners