“Which benchmark actually tells me if this model can do my job?”
Some version of that question comes up constantly. A founder wants to swap a pricey API for a self-hosted model and needs proof it won’t tank quality. A solo developer sees three Llama fine-tunes all claiming to “beat GPT-4” and has no idea which one is lying. A marketer just wants a chatbot that won’t hallucinate the company refund policy. And every single one of them eventually lands on the same place: a leaderboard full of acronyms like MMLU, HellaSwag, GSM8K, and MATH, with a column of decimals that may as well be hieroglyphics.
Here’s the honest truth: most people read leaderboards completely wrong. They sort by the top score, grab whatever model sits at rank one, and act surprised when it flops on their actual workload. A leaderboard isn’t a “best model” list. It’s a diagnostic panel — like blood work. The number only means something once you know what it’s measuring and whether that thing matters for what you’re building.
So this is the deep-dive I wish someone had handed me years ago. We’ll decode what each benchmark really tests, walk through reading rankings by capability instead of by overall score, and get into the power-user stuff — running your own evals, testing fine-tunes against baselines, and tracking whether your tweaks actually helped or just moved the noise around.
Contents
What the Open LLM Leaderboard actually is (and its current status)

The Open LLM Leaderboard started life as a Hugging Face project — a public, reproducible scoreboard that ran open-weight models through a fixed battery of academic benchmarks using the EleutherAI lm-evaluation-harness. The whole pitch was standardization: instead of every lab cherry-picking flattering numbers in their own press release, everyone got run through the same pipeline on the same hardware with the same prompts. You could trust that two models on the board were measured the same way.
The original “v1” board used six tests: ARC, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8K. By 2024 those got saturated — models were scoring so high the benchmarks stopped separating the good from the great — so Hugging Face launched a v2 with tougher tasks: MMLU-PRO, GPQA, MuSR, MATH (hard subset), IFEval, and BBH. One thing to flag up front, because it matters in 2026: according to Hugging Face’s own public communications, the official Open LLM Leaderboard was moved to an archived, static-snapshot state in 2025 rather than remaining a live, continuously updated board. Treat the exact timing and status as something to confirm against Hugging Face’s current pages, since these projects change. The data and methodology remain enormously useful as a reference, and the underlying evaluation harness is still published and maintained on GitHub — but if you want fresh rankings of the very latest models, you’ll be pairing it with live alternatives I’ll cover later.
That archival doesn’t make the leaderboard useless. Far from it. The benchmark methodology it standardized is now the lingua franca of model evaluation. Understanding how to read it is how you read every other board too.
Decoding the benchmarks: what each one really measures
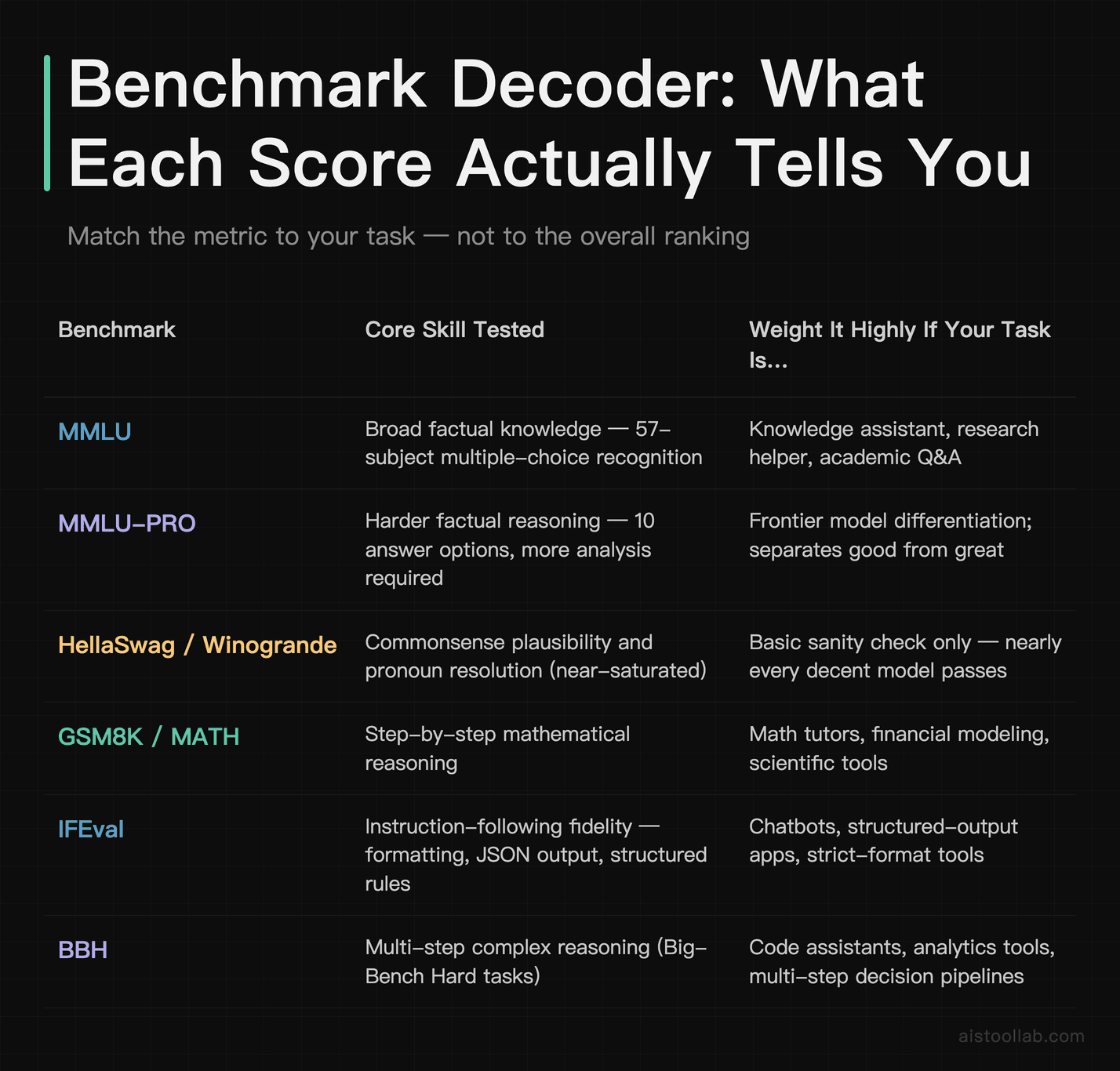
This is the part people skip and then regret. Every benchmark has a personality. Knowing it changes how much weight you give a score. For a deeper side-by-side on the three benchmarks people confuse most, see MMLU vs GPQA vs GSM8K explained.
MMLU and MMLU-PRO — breadth of knowledge
MMLU (Massive Multitask Language Understanding) is 57 subjects of multiple-choice questions, from US history to college physics to professional law. A high MMLU means the model has broad factual coverage and can pick the right answer from four options. What it does not mean is that the model writes well, follows instructions, or reasons step-by-step — it’s recognition, not generation. MMLU-PRO ups the difficulty (ten answer options, harder questions, more reasoning required) and is far better at separating frontier models. If your use case is a knowledge assistant or research helper, weight these heavily. If you’re building a code tool, they’re almost irrelevant.
HellaSwag and Winogrande — commonsense plausibility
HellaSwag asks the model to pick the most plausible continuation of a sentence. Winogrande tests pronoun resolution that requires real-world understanding (“The trophy didn’t fit in the suitcase because it was too big” — what’s “it”?). These are nearly saturated now; almost every decent model scores high. Treat them as a sanity floor, not a differentiator. If a model scores low on HellaSwag in 2026, something is genuinely broken.
GSM8K and MATH — two very different kinds of math
This pair trips people up constantly. GSM8K is grade-school word problems — multi-step arithmetic, but conceptually simple. MATH is competition-level mathematics (algebra, calculus, number theory) that demands actual symbolic reasoning. A model can ace GSM8K and faceplant on MATH. If your product does invoicing logic or simple calculation, GSM8K is your signal. If it does anything resembling quantitative analysis, MATH is the one that matters, and the gap between models there is enormous.
IFEval — does it follow instructions?
IFEval is, in my opinion, the most underrated benchmark for real products. It tests whether a model actually obeys constraints: “respond in exactly three bullet points,” “don’t use the word ‘great’,” “write in JSON.” For anyone building structured outputs, agents, or anything that feeds into downstream code, IFEval predicts real-world pain better than MMLU ever will. In my experience, models with mediocre MMLU scores can run circles around “smarter” models in production simply because they reliably do what you tell them.
BBH, GPQA, and MuSR — the reasoning tier
BBH (Big-Bench Hard) is a collection of tasks specifically chosen because earlier models struggled with them — multi-step logic, deduction, weird formatting. GPQA is graduate-level science questions written to be “Google-proof,” so memorization won’t save you. MuSR tests multi-step soft reasoning over longer narratives (think murder-mystery logic). These three are where you separate genuine reasoning ability from pattern-matching. If you’re evaluating models for an Agentic AI Systems Explained pipeline that has to plan and chain steps, these are your headline numbers.
If you want to see how these same benchmarks play out across the frontier chatbot models rather than open-weight ones, our breakdown of how the top AI models actually compare on benchmarks covers Claude, GPT-5, Grok and Gemini in the same honest spirit.
The real pros and cons of leaderboard-driven decisions

I’ve made good and bad calls based on these boards, so let me be straight about where they help and where they’ll burn you.
What’s genuinely great: Standardized, reproducible scoring means you can compare a tiny 7B fine-tune against a 70B base model on equal footing. It’s free, transparent, and the methodology is open — you can rerun the exact eval yourself. For open-weight models especially, it’s the single best starting filter to narrow hundreds of candidates down to a shortlist of five worth actually testing.
Where it falls apart: Benchmark contamination is real — when test questions leak into training data, scores inflate without any real capability gain, and it’s nearly impossible to detect from the outside. Static benchmarks also don’t measure the things that make or break products: latency, cost per token, conversational feel, long-context coherence, or how the model handles your domain jargon. A model can top the math chart and still produce robotic, joyless customer-support replies. And because the official Hugging Face board is now archived, it won’t have the newest releases. Treat the leaderboard as the screening interview, never the final hire.
Real-world use cases: who reads this board and why
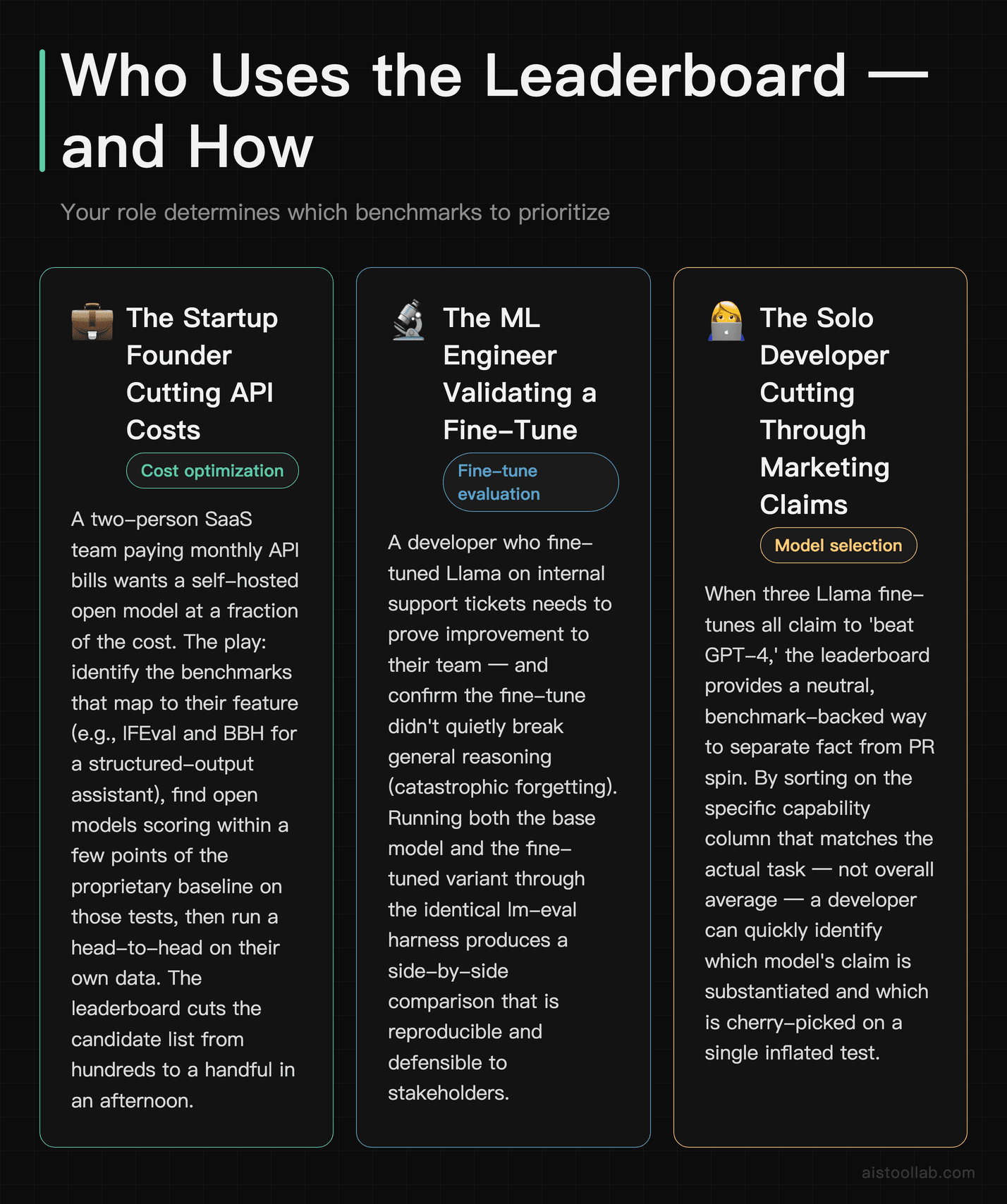
The startup founder swapping an API for self-hosted
Picture a two-person SaaS team paying real money every month for a proprietary API powering an in-app assistant. They want to know if an open model running on their own GPU can do the job at lower cost. The play: identify which benchmarks map to their feature (say, IFEval and BBH for a structured-output assistant), find open models that score within a few points of the proprietary baseline on those specific tests, then run a head-to-head on their own data. The leaderboard cuts the candidate list from hundreds to a handful in an afternoon. I walked through the broader trade-offs in best LLMs comparison, and the short version is: the performance gap that matters is rarely the one in the headline.
The ML engineer validating a fine-tune
A developer fine-tunes an open model on internal support tickets and needs to prove to their boss it actually improved things — and didn’t quietly break general reasoning (a phenomenon called “catastrophic forgetting”). Leaderboard methodology lets them run the base model and the fine-tune through the identical harness, then compare scores benchmark-by-benchmark. If domain accuracy climbed but MMLU and BBH collapsed, that’s a red flag the model overfit. This is the single most valuable use of the eval harness, and most teams don’t do it.
The solo developer cutting through fine-tune hype
Hugging Face is flooded with fine-tunes claiming greatness. A freelance developer evaluating which one to build on can’t trust the model card — those are marketing. The leaderboard (or a self-run eval) gives an apples-to-apples number that ignores the hype. Sorting by the specific capability they need, rather than overall average, surfaces the genuinely useful models that don’t have a flashy README.
Power-user workflow: how I actually read and use the board

Here’s the step-by-step I follow, and it has almost nothing to do with the top of the rankings.
Step 1 — Define your capability profile first. Before opening any leaderboard, write down what your task needs in plain English. “Reliable JSON output, decent reasoning, math doesn’t matter.” That maps to: high IFEval, solid BBH, ignore MATH. Now you have a filter. Sorting by overall average is the rookie move; sort by the column that maps to your job.
Step 2 — Filter by model size and license. Most boards let you filter by parameter count and whether the model is base, instruction-tuned, or a chat variant. If you can only run a 7–8B model on your hardware, there’s no point drooling over a 70B’s scores. Filter ruthlessly. Also check the license — some “open” models forbid commercial use, which kills the whole cost-saving argument before you start.
Step 3 — Look at the spread, not just the peak. A model that scores evenly across all benchmarks is a generalist. A model with one sky-high score and several mediocre ones is a specialist (and sometimes a sign of contamination on that one test). For most products you want consistency. A jagged profile is a warning to investigate, not a reason to celebrate.
Step 4 — Run the harness yourself on a sample. This is where power users separate from tourists. Install the EleutherAI evaluation harness and run your shortlisted models on the specific benchmarks you care about, plus a custom set of your own examples. Swap in whatever model identifier you’re evaluating:
pip install lm-eval
lm_eval --model hf
--model_args pretrained=<your-model-id>
--tasks ifeval,bbh,gsm8k
--device cuda:0
--batch_size autoStep 5 — Build a custom eval for your domain. Public benchmarks won’t test whether the model knows your refund policy or your codebase conventions. Write 50–100 of your own question-answer pairs that mirror real production prompts, and score models against those. This is the eval that actually predicts whether you’ll be happy in three months. Even a rough hand-graded set of 50 prompts beats any public score for your specific use case.
Step 6 — Track over time. Save every run with a date and the model version. When you fine-tune again, or a new base model drops, rerun the identical eval and compare. Performance tracking is only meaningful when the test is frozen — change the questions and you’ve lost your baseline. I keep a simple spreadsheet: model, date, each benchmark score, plus my custom domain score. After a few iterations you can actually see whether your work is moving the needle or just shuffling noise.
Open LLM Leaderboard vs the live alternatives
Because the official board is now archived, you’ll want to know how it stacks against the platforms people use for fresh data. Here’s how the main evaluation resources compare across the dimensions that actually matter.
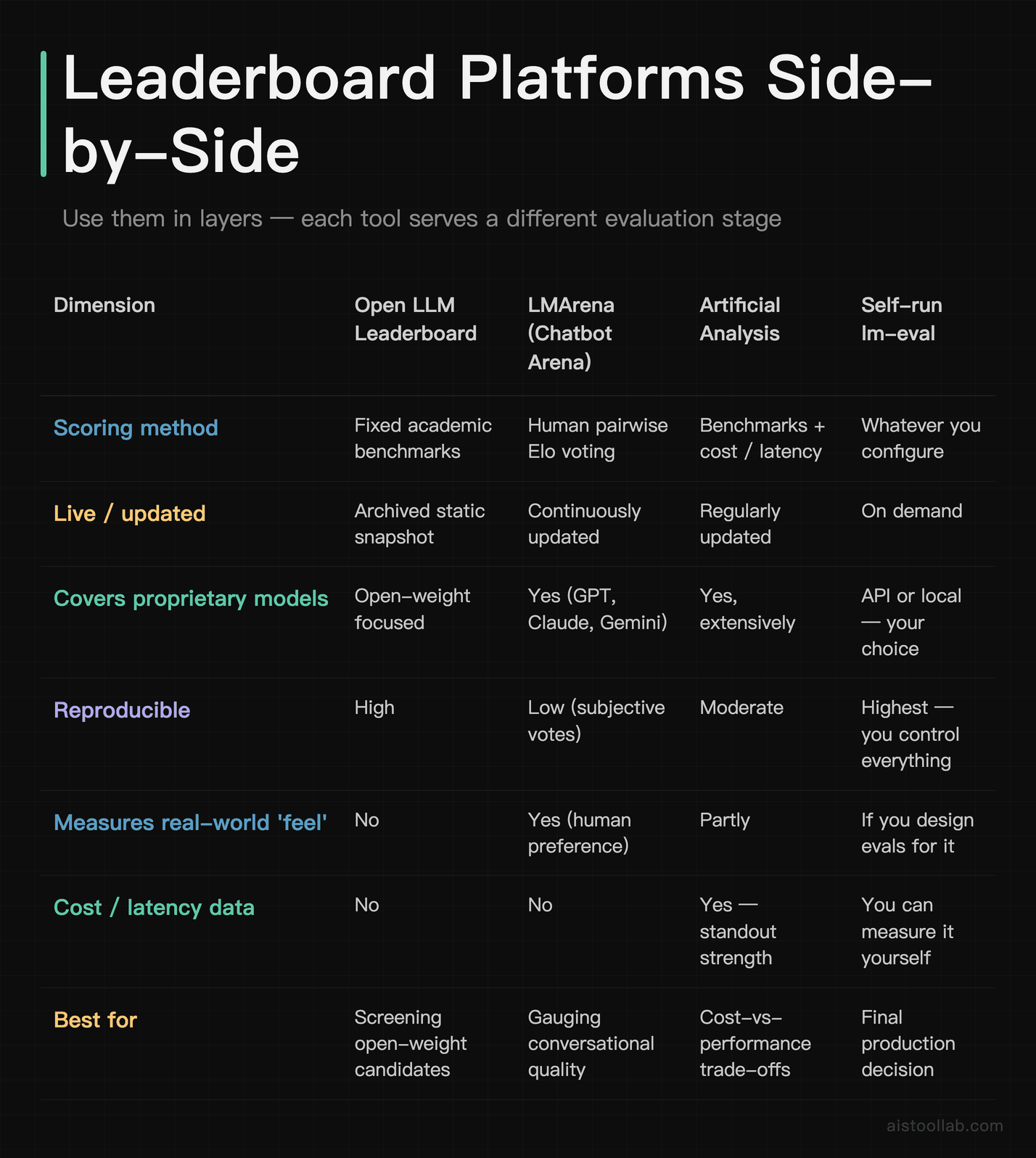
My honest take: use them in layers. Start with the Open LLM Leaderboard methodology to screen open-weight candidates, check LMArena for a gut-feel of conversational quality, glance at Artificial Analysis for cost-per-token reality, then make the final call with your own harness run on your own data. No single board is the answer.
Frequently Asked Questions
Is a higher MMLU score always better for my use case?
No, and assuming so is one of the most common mistakes I see. MMLU measures broad multiple-choice knowledge recognition across 57 subjects — it tells you the model has wide factual coverage and can pick the right answer from a list. That’s valuable for a research assistant or a general knowledge bot. But it tells you nothing about whether the model writes naturally, follows formatting instructions, reasons through multi-step problems, or handles your specific domain. In my experience, models with middling MMLU scores can outperform “smarter” models in production because they reliably follow instructions (high IFEval) and produce clean structured output. If your application is a coding assistant, a customer-support bot, or anything with strict output formats, MMLU should be near the bottom of your priority list. Always match the benchmark to the actual job. The peak overall score is a vanity metric; the score on the capability you need is the one that pays the bills.
Why was the Open LLM Leaderboard archived, and does it still matter?
Per Hugging Face’s own public communications, the Open LLM Leaderboard was moved to an archived, static-snapshot state in 2025 rather than continuing to update live (confirm the exact status against Hugging Face’s current pages). The commonly cited reasons come down to the enormous compute cost of continuously evaluating a flood of new models, benchmark saturation (top models scoring so high the tests stopped separating them), and the broader shift toward human-preference evaluations. Does it still matter? Absolutely. The methodology it standardized — running models through the EleutherAI evaluation harness on a fixed set of academic benchmarks — is now the foundation of how the whole field measures models. The archived data remains a solid reference for understanding relative capabilities of models released up to that point, and the harness itself remains published and maintained on GitHub. So while you wouldn’t rely on the frozen board for the newest 2026 releases, learning to read it teaches you to read every other board, and self-running the same harness gives you reproducible, contamination-resistant numbers for your own decisions.
What’s the difference between GSM8K and MATH, and which should I care about?
They sound similar but test wildly different things. GSM8K is grade-school math — word problems requiring a few steps of basic arithmetic. The reasoning is multi-step but the math itself is simple. MATH, by contrast, is competition-level mathematics: algebra, geometry, calculus, number theory, problems that demand genuine symbolic reasoning. A model can score 90%+ on GSM8K and still struggle badly with MATH, because the latter requires a fundamentally deeper capability. Which one matters depends entirely on your use case. If your product handles simple calculations — splitting bills, basic financial math, inventory counts — GSM8K is a reasonable proxy. If you’re building anything involving quantitative analysis, scientific computation, or advanced problem-solving, MATH is your signal, and the gap between models there is dramatic. Many teams over-index on GSM8K because the numbers look impressive, then discover their model can’t handle the harder math their users actually throw at it. Check both, but weight the one that mirrors your real workload.
Can I trust leaderboard scores, or are they gamed?
Trust them as a screening tool, not as gospel. The biggest threat to leaderboard validity is benchmark contamination — when test questions accidentally (or deliberately) end up in a model’s training data, inflating scores without any real capability gain. It’s genuinely hard to detect from the outside. A telltale sign is a model with one suspiciously high score that’s wildly out of line with its other benchmarks. Some fine-tunes are essentially optimized to score well on specific public benchmarks while being no better, or worse, in real use. This is exactly why I never make a final decision on public scores alone. The defense is straightforward: build a small custom evaluation set from your own data — 50 to 100 prompts that mirror real production usage — and run candidate models against that. Your private data can’t be contaminated because it was never published. Public boards narrow your shortlist; your own eval makes the final call. Treat any single eye-popping number with healthy skepticism until you’ve reproduced it yourself.
How do I test whether my fine-tune actually improved the model?
Run both the base model and your fine-tuned version through the identical evaluation harness, on the same benchmarks, and compare score-by-score. The key word is identical — same tasks, same configuration, same hardware ideally, so any difference reflects the model and not the test setup. Watch two things. First, did your target capability improve? If you fine-tuned on support tickets, your domain-specific custom eval should climb. Second — and this is the one people forget — did general capabilities collapse? Fine-tuning can cause catastrophic forgetting, where the model gets better at your narrow task but loses broad reasoning, math, or instruction-following. If your custom score went up but MMLU and BBH cratered, you’ve overfit and likely created a model that’s brittle outside its training distribution. The healthy outcome is domain gains with general scores holding roughly steady. Save every run with a date and version label so you can track iterations over time. Without a frozen baseline, you can’t tell improvement from random noise.
Should I choose an open-source model or a proprietary API based on benchmarks?
Benchmarks should inform that decision, not make it alone. Start by identifying the performance gap that actually matters for your task. If the best open model scores within a couple of points of a proprietary API on the specific benchmarks your product depends on — say IFEval and BBH for a structured agent — then the open model is likely “good enough,” and self-hosting can cut per-token costs at scale (actual savings depend on your usage and infrastructure). But if there’s a meaningful gap on a benchmark central to your use case, that gap will show up as user-facing quality problems. Beyond raw scores, factor in the stuff leaderboards don’t measure: infrastructure cost and engineering time to self-host, latency, reliability, context length, and ongoing maintenance. For a small team without ML ops experience, a proprietary API’s convenience often outweighs a modest cost premium. For a team with GPU access and scale, an open model that benchmarks competitively on the right metrics can be a huge win. The benchmark tells you if it’s feasible; your team’s resources tell you if it’s wise.
Do I need a GPU to run my own evaluations?
For local open-weight models, yes — practically speaking you’ll want a GPU, since running benchmarks on CPU is painfully slow for anything beyond tiny models. A consumer GPU with enough VRAM can typically handle models in the 7–8B range, depending on the card and quantization; larger models need more serious hardware or aggressive quantization. That said, you have options that don’t require owning hardware. You can rent GPU time by the hour from cloud providers and run the harness there, paying only for the eval run, which for a shortlist of models is usually inexpensive. Alternatively, if you’re evaluating models served through APIs (including some open models hosted by inference providers), the harness can hit those endpoints and you skip local hardware entirely — though you’ll pay per-token API costs instead. For most solo developers and small teams I’d suggest renting cloud GPU for a focused evaluation session rather than buying hardware you’ll use occasionally. Define your benchmark list and custom eval first, spin up an instance, run everything in one sitting, and shut it down. A focused evaluation run is often cheap, but the exact cost depends on the provider’s hourly rates and how many models you test.
How is human preference evaluation different from benchmark scores?
They measure fundamentally different things, and you want both. Benchmark scores like MMLU or BBH are automated and objective — the model picks an answer, it’s right or wrong, you get a number. They’re reproducible and great for measuring specific capabilities, but they don’t capture how a model feels to interact with. Human preference evaluation, like the Elo-style voting on LMArena (Chatbot Arena), works differently: real people compare two anonymous model responses to the same prompt and vote for the better one. Aggregate enough votes and you get a ranking based on what humans actually prefer — tone, helpfulness, clarity, the intangibles. The catch is that human preference is subjective and harder to reproduce; it can favor confident-sounding answers over correct ones, and it doesn’t isolate specific skills. The smart move is to use benchmarks to verify a model can do the technical work, then check human-preference rankings to gauge whether it’s pleasant and natural in conversation. A model that aces benchmarks but ranks low on human preference might be technically capable yet frustrating to actually use.
My verdict: the leaderboard is a starting line, not a finish line

If you’re a developer or a small team trying to pick a model in 2026, here’s exactly what I’d do with my own money and time on the line. Use the Open LLM Leaderboard’s methodology and archived data to understand what each benchmark measures and to screen open-weight candidates down to a shortlist. Cross-check conversational quality on LMArena and cost-versus-performance on Artificial Analysis. Then — and this is the non-negotiable part — run the EleutherAI harness yourself on the specific benchmarks that map to your task, plus a custom eval built from your own real prompts. That last step is what separates people who ship reliable AI products from people who get burned by a flashy rank-one model that can’t do their actual job.
The leaderboard won’t tell you which model is “best.” Nothing can, because “best” only exists relative to a task. What it gives you is a shared, reproducible language for measuring capability — and once you can read it fluently, you stop chasing leaderboard peaks and start choosing models that genuinely fit. Your next move: pick the two benchmarks that matter most for what you’re building, run two models through the harness on them this week, and add your own 50-prompt domain test. You’ll learn more in that afternoon than from a month of staring at score columns.
Last updated: 2026
Explore more AI tools
👉 Browse the AI Tools Library to find the right tools for your workflow.