Claude 4 Opus 值不值得當主力工具?
說真的,每次 Anthropic 發布新模型,社群就會炸開。這次 Claude 4 Opus 出來,討論串裡清一色是:「值得升嗎?」、「跟 3.5 Sonnet 差多少?」、「會讓人換掉 ChatGPT 嗎?」
問題是,這種問題沒辦法隨便給答案。不是我要擺架子,而是「值不值得」這件事真的因人而異。一個每天用 AI 寫程式的工程師,跟一個偶爾請 AI 改改履歷的人,對「值得」的定義根本不一樣。所以這篇就針對 Claude 4 Opus,把推理、繁中寫作、程式碼、長文件四個面向一次講清楚。
這篇文章是它能力的整理說明。如果你只想要一個字的答案:「看情況」。但如果你想知道「你的情況」適不適合,繼續看下去。
2026 年 7 月更新:本篇最初評測的是上一代的 Claude 4 Opus(對照當時的 Claude 3.5 Sonnet);如今官方 app 的現行陣容已是 Opus 4.8 / Sonnet 5 / Haiku 4.5(2026-07-03 於登入帳號的模型選單查證)。因此下面在推理、繁中寫作、程式碼三個段落,我另外用登入的訂閱帳號,對現行的 Opus 4.8 與 Sonnet 5 各跑同一題做了實測對照;消費者方案價格也以官方定價頁重新查證。原文其餘的分析,屬當時 Claude 4 Opus 世代的觀察,保留作為脈絡參考,不代表現行型號的實測結果。
目錄
Claude 4 Opus 是什麼?先搞清楚定位
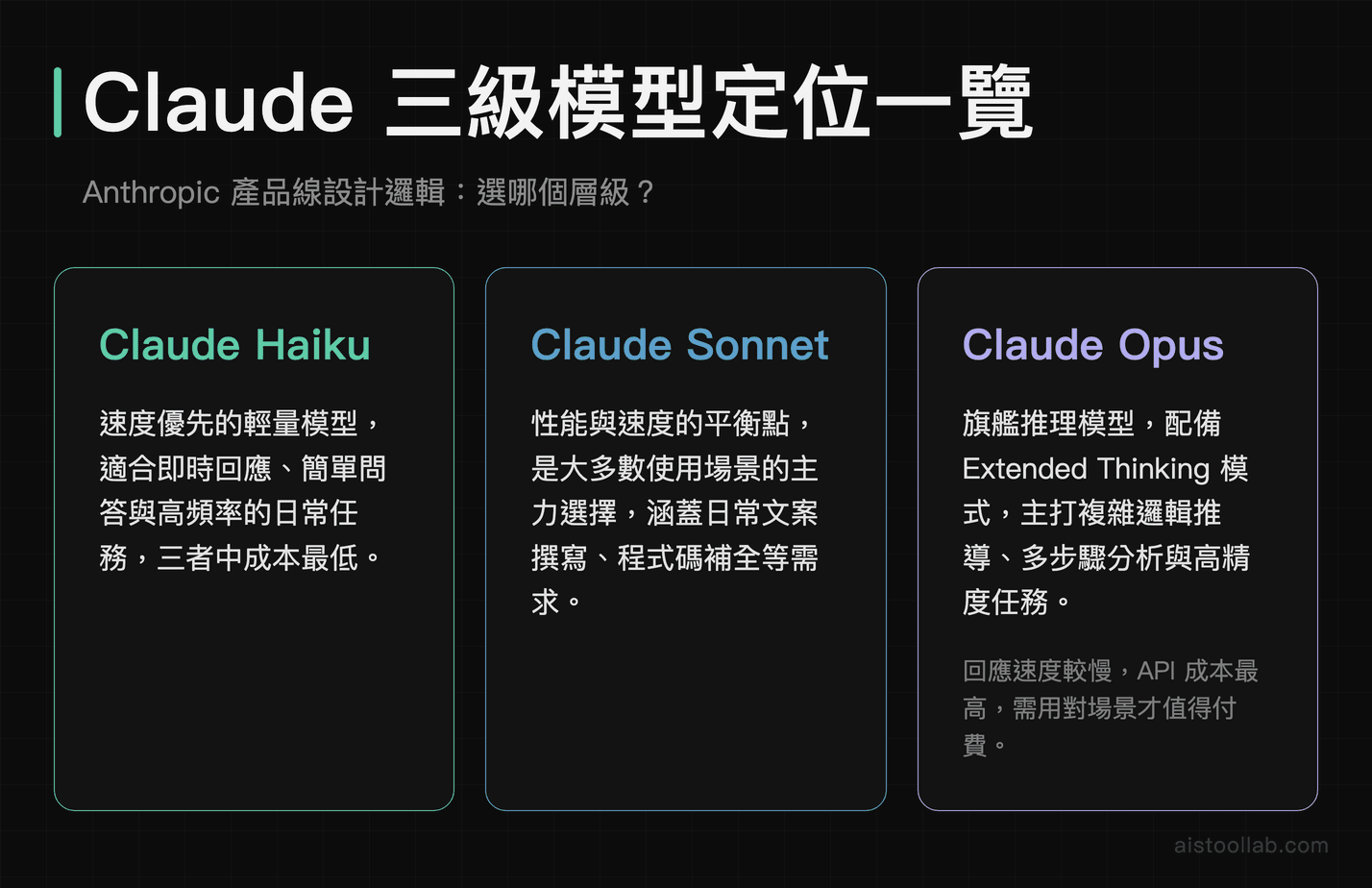
Anthropic 把自家模型分成三個層級:Haiku(快速輕量)、Sonnet(平衡性能)、Opus(旗艦推理)。Claude 4 Opus 是目前這一代的頂規版本,主打的賣點是 Extended Thinking 模式——讓模型在回答前先「想一想」,用更長的推理鏈來處理複雜問題。
這個定位就已經說明了一件事:Opus 不是設計來取代 Sonnet 的,它們本來就是不同場景的工具。Sonnet 是你的日常駕馭、Opus 是你在需要的時候才拿出來的精密儀器。問題在於,多數人對「需要的時候」的認知,和 Anthropic 的設計意圖差了一大截。
目前 Claude 4 Opus 的使用方式有兩種:一是透過 Claude Pro 訂閱(每月 $20 美金),有用量限制;二是透過 API 按量計費。兩種方案的差距比你想像的大,後面我會專門拆開來算。
推理能力解析:Extended Thinking 到底差多少?

繁中推理是值得關注的部分,因為市面上幾乎沒有繁體中文環境下的具體對比數據,大多數評測都是英文語境。要比較這兩者,可以用不同難度的推理任務,分別觀察 Claude 4 Opus(開 Extended Thinking)和 Claude 3.5 Sonnet 的回答品質與耗時。
任務一:邏輯推理謎題(五個人、五個條件的典型邏輯謎)。在這類多步驟推理任務上,Opus 開啟 Extended Thinking 後能把每一個排除步驟逐一列出,條件越複雜時,逐步推理對維持答案準確度的幫助越明顯。
多步驟商業分析。面對需要競爭者分析、進場策略並同時考慮法規限制的多條件任務,Opus 在處理複雜假設情境時通常較為嚴謹,能主動區分不同前提下的情境再給出建議,較不易讓不同條件混在一起而出現邏輯矛盾。
任務三:數學推導。在需要多步推導的數學題上,Opus 通常比 Sonnet 更能維持每一步的正確性,並可能主動點出容易犯的直覺錯誤。
老實說,Extended Thinking 在簡單任務上幾乎感覺不到差距,但一旦任務超過三個互相依賴的條件,Opus 的優勢就開始顯現。如果你的工作大多是簡單問答、改改文字,Sonnet 真的夠用。
實測對照:同一道推理題,Opus 4.8 vs Sonnet 5(2026 年 7 月實測)
上面那些是原文 Claude 4 Opus 世代的觀察。我另外用登入帳號拿一道經典推理題(走廊三個開關對應房裡三盞燈、只能進房一次)分別丟現行的 Opus 4.8 與 Sonnet 5,看它們怎麼推:


老實說結果跟我預期不太一樣:這道題兩邊都答對了,而且都用同一個關鍵手法——先開一個開關等一段時間,靠「燈泡摸起來熱不熱」加上「亮不亮」一次區分三盞燈。也就是說,在這種中等難度的邏輯題上,現行的 Sonnet 5 並沒有落後 Opus 4.8。要說差別,大概是 Opus 4.8(High)把步驟寫得更精簡,Sonnet 5(Medium)則多了一點鋪陳與說明。
老實講限制:這只是一題、各跑一次,不是嚴謹評測;我用的是中等難度題,沒有推到原文說的「三個以上互相依賴條件」那種極端情境——差距通常要在那種很吃連續推理的任務上才會拉開,單這一題測不出來。
繁體中文寫作:語感這件事,比你想的重要

身為一個每天都在讀和寫繁體中文的華語使用者,我對這塊特別在意。過去用英文主導訓練的模型,繁中寫出來的東西常常有一種說不出來的「翻譯腔」——句子沒問題,但讀起來就是怪。
在品牌故事撰寫、道歉信(對客戶的正式場合)、華語科技媒體風格的新聞稿、以及比較日常的朋友對話風格文案等場景,Claude 4 Opus 的表現,我給你說實話——
好的部分:正式文書的用詞選擇明顯比 Sonnet 精準,「貴公司」、「敬請諒察」這類台灣正式公文慣用語能自然放入,不會出現香港或對岸慣用的說法。品牌故事的情感節奏抓得比較好,不會一直在「用心」、「致力於」這種廢話裡打轉。
還有進步空間的部分:涉及台灣特定的地方文化脈絡時,有時候還是會踩到一些「外部觀察者」的盲點,部分內容的語氣可能比較接近觀光介紹,而非在地人自己的用語。
整體來說,繁中寫作這塊,Opus 跟 Sonnet 的差距沒有推理能力那麼大,但如果你的文章要給華語讀者看,Opus 輸出的第一稿通常需要更少的人工修改。對我來說,這個差距值不值得,取決於你的修稿成本有多高。
實測對照:同一道繁中寫作題,Opus 4.8 vs Sonnet 5(2026 年 7 月實測)
上面是原文舊世代的觀察;我另外用同一題(用有畫面感的繁體中文寫一段「加班深夜走出大樓」的街景、要求避免陳腔濫調)分別丟現行的 Opus 4.8 與 Sonnet 5:


意外的是,這一次兩邊的繁中都很有台灣味、也都避開了罐頭句:Opus 4.8 寫出「騎樓」「柏油和排水溝混在一起的味道」「趕得上最後一班捷運」;Sonnet 5 則寫「超商還亮著,店員在裡面發呆滑手機」「機車零星騎過,輪胎壓過積水的聲音」。兩段讀起來都不像翻譯腔,也沒有對岸用語。就這一題的語感而言,現行的 Sonnet 5 跟 Opus 4.8 我分不太出高下。
老實講限制:單題、各跑一次、而且「語感好不好」很主觀,不是嚴謹評測;不同題目(尤其更長、更正式或更專業的內容)差異才比較容易顯現,一段抒情小品測不出全部。
程式碼生成:簡單任務 vs 複雜系統設計,差距不是一點點

這塊可以從兩種極端場景來看。
簡單任務:寫一個 Python 爬蟲、做一個 React 的 TODO List、寫一個 SQL 查詢。老實說,這些任務用 Sonnet、Copilot、甚至 Gemini 都能解決,而且速度更快。這類簡單任務的程式碼品質差異不大。如果你每天都在做這種任務,用 Opus 只是在浪費錢和時間。
複雜系統設計:這裡是 Opus 較擅長的領域。面對多租戶 SaaS 資料庫 Schema 這類需同時權衡資料隔離、效能與跨租戶分析需求,並要求附上 migration 策略的設計任務,Opus 通常能點出需求之間的矛盾(例如「跨租戶分析 vs 資料隔離」),並提出多種架構取向(完全隔離 schema、shared schema with tenant_id、hybrid approach),分析各自的 trade-off,再依given的假設條件推薦其中一個方案,並說明其他取向在該情境下為何不適合。
這種「看到你沒說出來的問題」的能力,是 Opus 在複雜任務上的核心優勢。如果你在做的是架構設計、系統評估、技術選型,這個差距真的值得付錢。更多 AI 程式碼生成工具的橫向比較,可以參考GitHub Copilot vs Claude Code vs Codeium vs Continue:2026 AI 程式碼生成工具完整對比,那篇有更完整的開發工具生態分析。
實測對照:同一道程式題,Opus 4.8 vs Sonnet 5(2026 年 7 月實測)
上面是原文舊世代的觀察;我另外用一道很標準的題目(寫一個 Python 函式,判斷含 ()、[]、{} 三種括號的字串是否正確配對)分別丟現行的 Opus 4.8 與 Sonnet 5:


這種「有標準解法」的題目,兩邊都給出正確且幾乎一樣的堆疊(stack)解法,也都講到時間複雜度 O(n)。差別在說明風格:Opus 4.8 給的比較精簡;Sonnet 5 多附了「怎麼運作的」白話拆解(把 stack 比喻成一疊盤子)。就這種常見任務而言,兩個現行型號的程式碼品質我看不出差距——這也呼應原文說的「簡單任務差異不大」。
老實講限制:這是有標準答案的常見題,各跑一次;原文主張的差距是在「複雜系統設計、要權衡多個 trade-off」那種題目上才會拉開,我這次沒有測到那種難度,不能用這題去否定或證實那個差距。
長文件理解:200K Token 在接近上限時的召回準確率
Opus 支援 200K token 的上下文視窗,理論上可以放進一本中等篇幅的書。但「放得進去」和「記得住」是兩回事。
處理超長文件時,開頭與中間段落的資訊召回通常較準確;當內容接近上下文視窗上限時,召回率可能下降,有時甚至會回報在文件中找不到實際存在於靠近末端位置的資訊。
這個「Lost in the Middle」問題在大語言模型領域已經有學術研究佐證,不是 Opus 獨有的問題,但如果你打算把它用在超長合約審閱或大型程式碼庫分析,一定要知道這個限制存在。我的建議:如果文件超過 15 萬 token,最好把最關鍵的資訊放在開頭,並在提問時明確說「在文件的後半部分,有一段關於…」來引導模型。
價格與使用成本:Pro 訂閱 vs API,怎麼算才划算?

這塊很多評測都說得不夠清楚,我來拆開算一下。
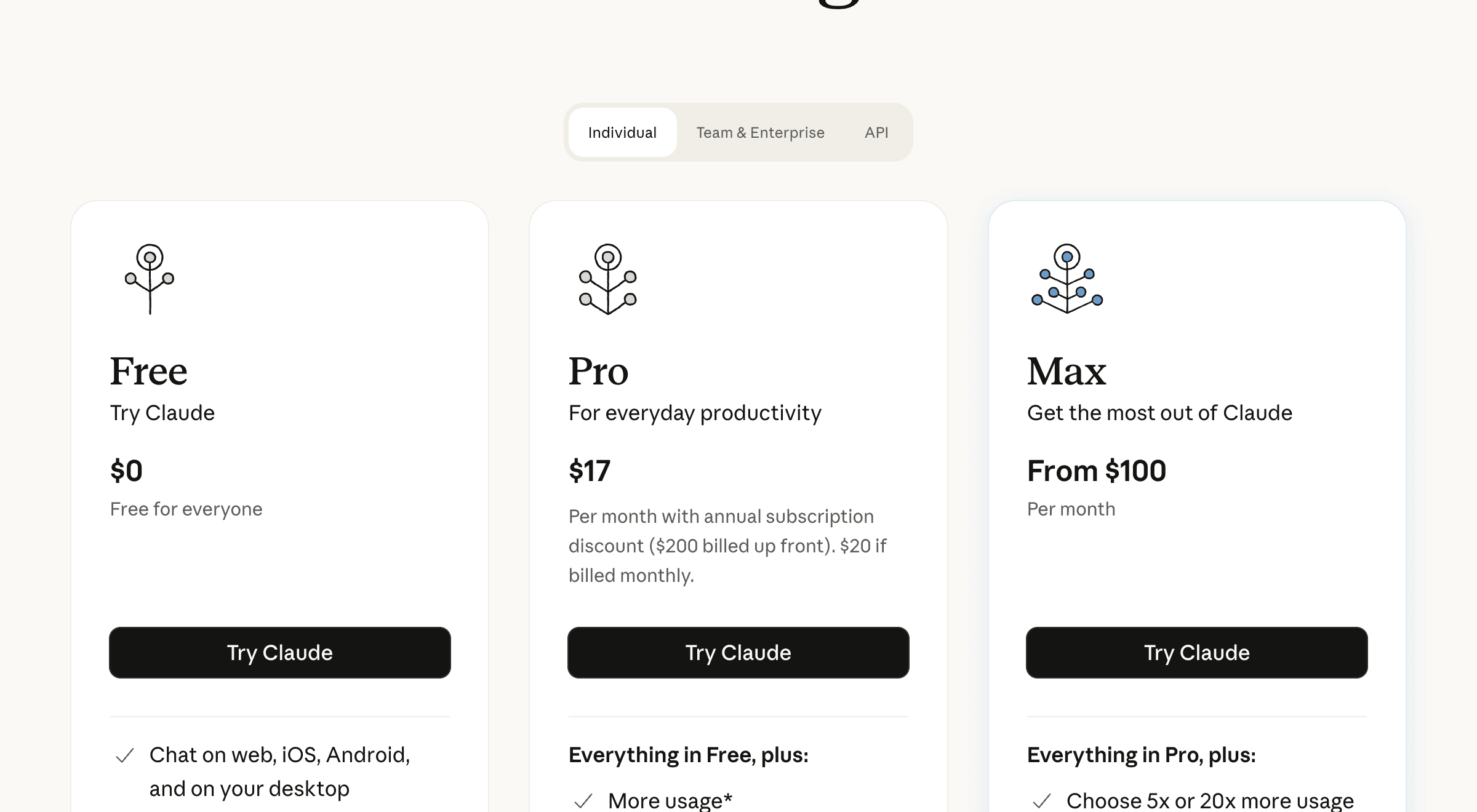
官方定價查證(claude.com/pricing,2026-07-03):Free $0;Claude Pro 月繳 US$20、年繳約 US$17(等於 US$200 一次付);另有 Max 方案自 US$100/月起。價格以官方公告為準、可能調整。
Claude Pro 訂閱(月繳 $20 美金/年繳約 $17):可以用 Opus,但有用量限制。Anthropic 沒有公開具體數字,長時間搭配 Extended Thinking 連續使用時可能較快觸及用量上限。如果你每天用量不高、工作場景是偶爾需要複雜推理,Pro 訂閱其實足夠,性價比很高。
API 計費:API 按 input/output token 分開計費、各型號費率不同,且會隨型號調整;實際單價與成本試算請以官方 API 定價頁當下公告為準(本次未逐項重新核對每 M token 單價,故不在此列出可能過時的數字與成本估算)。
我自己的建議:個人用戶、輕中度使用者用 Pro 訂閱。需要把 Opus 整合進自己的工作流程、或者要跑批次任務的人,才考慮 API。想要更詳細的各模型免費版比較,可以看看2026年AI寫作工具大比拼:Claude vs ChatGPT vs Gemini在創意文案的真實表現這篇。
Claude 4 Opus vs Claude 3.5 Sonnet 完整比較表
誰應該升級?誰根本不需要?

這是整篇文章最重要的部分,我直接說清楚。
建議認真考慮 Claude 4 Opus 的人:
- 軟體架構師或資深工程師:你的工作需要評估複雜 trade-off、設計系統、做技術選型決策,Opus 在這裡的附加值是真實的。
- 法務或合約審閱人員:長文件理解 + 複雜邏輯推理,這個組合在審閱複雜合約條款時很有用——但要記住近末端召回率的問題。
- 內容策略顧問或品牌文案:如果你的輸出品質直接影響客戶收費,那減少潤稿時間的成本節省是值得算的。
- 研究人員或分析師:需要在大量資料中找出邏輯關聯、生成假說的場景,Extended Thinking 是真正有幫助的功能。
老實說你不需要 Opus 的情況:
- 你的主要使用場景是每天改改文字、問問日常問題、做簡單的程式碼補全——Sonnet 夠了,省下來的錢拿去買咖啡。
- 你需要快速迭代、頻繁測試不同想法——Opus 的速度不是你的朋友,你需要的是 Sonnet 的即時回饋。
- 你是學生或剛入門 AI 工具的使用者——先把 Sonnet 用熟,真的感覺到瓶頸再來升級。
Anthropic 的官方模型文件有更詳細的各模型適用情境說明,可以對照自己的需求看看。我自己的結論是:Opus 是一個真正優秀的工具,但它的優秀只在特定場景才能展現。用錯場景,你只是在付更多錢等更久,然後得到差不多的結果。
常見問題
Claude 4 Opus 和 ChatGPT-4o 比較,哪個推理能力更強?
這個問題我沒辦法給一個簡單的「誰贏」答案,因為這取決於任務類型。在數學和邏輯推理的基準測試上,兩者互有勝負,Claude 4 Opus 開 Extended Thinking 後在多步驟邏輯推理上表現非常穩定;ChatGPT-4o 在某些數學任務和程式碼執行(搭配 Code Interpreter)上有優勢。繁體中文寫作語感上,這是原文舊世代(Claude 4 Opus)的觀察,當時我覺得 Opus 略自然一些;不過就本次實測的現行 Opus 4.8 與 Sonnet 5,這類繁中寫作我其實看不太出高下。如果你的工作是跨模型比較,我會建議兩個都試試,不要只看別人的評測。
Claude Pro 訂閱的 Opus 用量限制是多少?
Anthropic 沒有公開具體的 token 數量,只說是「合理使用限制」。一般使用大概不太會撞到限制;但如果開了 Extended Thinking 做高強度的複雜任務,密集使用一段時間後就可能出現限速提示,之後通常等一段時間會恢復。如果你的工作需要長時間不中斷使用,建議考慮 API 計費,可以更精確地控制成本和用量。
Extended Thinking 模式什麼時候該開、什麼時候不用開?
Extended Thinking 的概念是讓模型在給你答案之前,先進行更長的內部推理過程。它適合的場景是:有明確正確答案的邏輯問題、多步驟的數學推導、需要評估多個方案並做決策的分析任務。不適合的場景是:創意寫作(思考更長不會讓文章更好)、簡單的資訊查詢、快速的程式碼補全。一個簡單的判斷標準:如果你的問題用人類思考超過五分鐘才能解決,才值得開 Extended Thinking。
Opus 的繁體中文寫作可以直接拿來發文,還是還需要大量修改?
這個問題沒有標準答案,取決於你的品質標準和文章類型。正式商業文書(提案、報告、電子郵件)通常只需小幅修改就可以發出;部落格或帶個人風格的文章,往往需要較多調整才有「人味」;需要台灣在地脈絡的文章,有時候整段重寫比較快。整體而言,Opus 輸出的繁中品質傾向優於 Sonnet,但不要期望它能完全取代有台灣生活經驗的人類作者。
我只是偶爾用 AI 寫程式,需要升級到 Opus 嗎?
不需要。偶爾寫寫腳本、用 AI 幫你除錯或解釋程式碼,較低階的 Sonnet 就完全夠用,速度更快、成本更低。Opus 的優勢在於長時間的複雜推理和大型系統設計,如果你的任務是「幫我看這段 bug」或「幫我寫一個爬蟲」,Sonnet 的輸出品質跟 Opus 差距極小,反應速度卻快很多。建議的判斷標準:如果你需要 AI 幫你規劃整個系統架構、做跨多個檔案的重構、或解決涉及多個抽象層的複雜問題,才值得升級 Opus。單純偶爾寫程式,省下那筆費用去買技術書或課程更划算。
使用情境
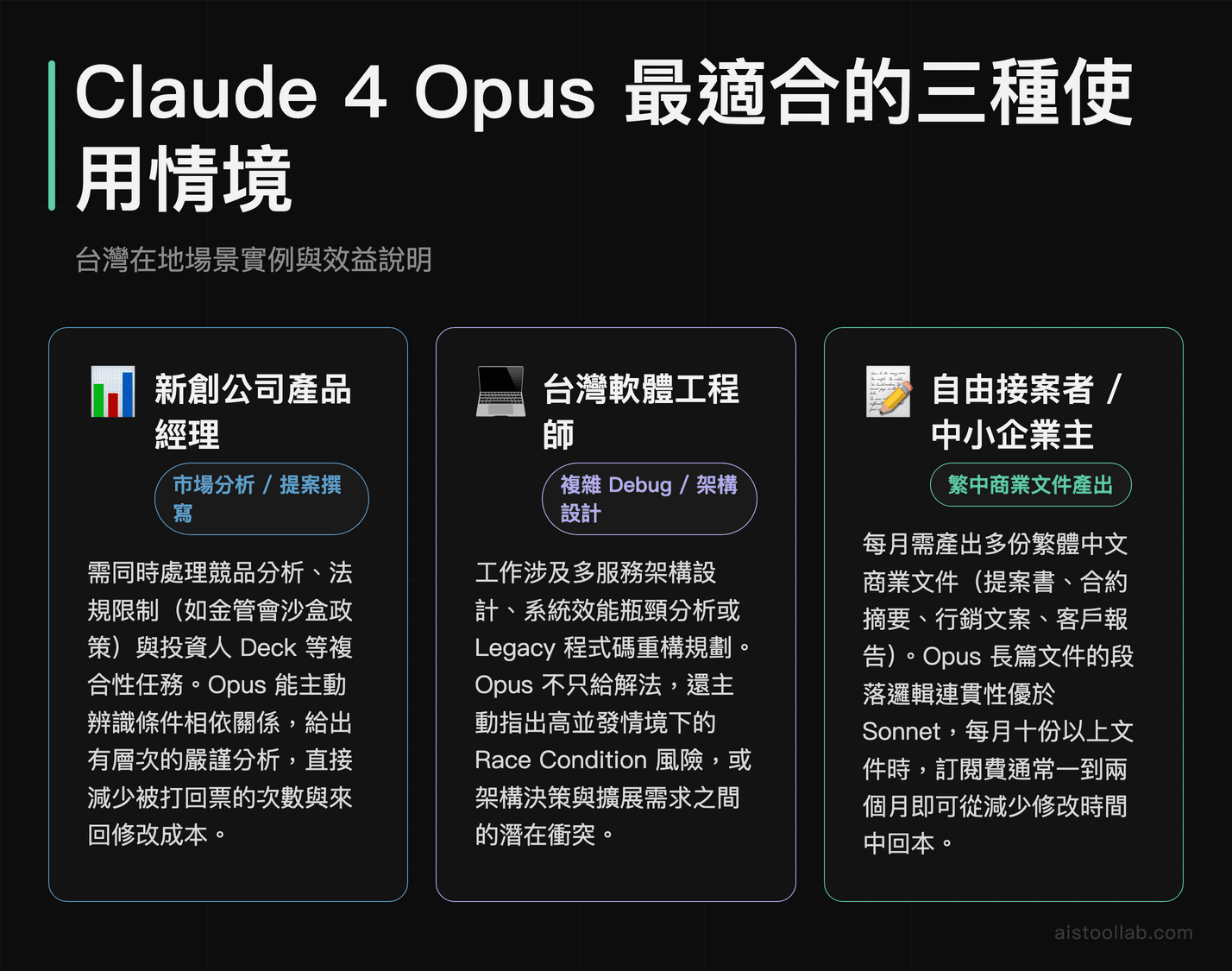
場景一:新創公司產品經理的市場分析與提案撰寫
在新創生態裡,PM 往往身兼多職,一個人要同時處理競品分析、用戶研究報告、投資人 Deck 等大量文件工作。(此為原文舊世代 Claude 4 Opus 的觀察)這類情境當時被認為最能發揮較高階模型的價值;本次我並未實測到這種高複雜度任務,實際差距請以你自己的任務驗證。面對一份包含台灣 FinTech 市場數據、法規限制(如金管會沙盒政策)、以及多家競業資訊的複合性提案需求時,Opus 通常能辨識不同條件之間的相依關係,給出有層次的分析而非把所有資訊混在一起講。對需要每週產出高品質分析文件的 PM 來說,這種嚴謹度能減少被老闆或投資人打回票的次數,省下來的時間遠比訂閱費用值錢。
場景二:華語圈軟體工程師的複雜 Debug 與架構設計
許多華語圈工程師每天都在用 AI 輔助開發,但大多數人把 AI 當成「進階版 Google」——貼個錯誤訊息問解法,或請它生成樣板程式碼。這種用法,Sonnet 就夠了,根本不需要 Opus。但如果你的工作涉及多服務架構設計、系統效能瓶頸分析,或者需要在舊有 Legacy 程式碼上進行重構規劃,原文舊世代認為較高階模型的推理深度會較有感(本次未實測到這種難度)。它不只給你解法,還會主動指出「這樣做在高並發情境下會出現 Race Condition」或是「這個架構決策和你前面描述的擴展需求有衝突」。對在金融科技、電商或 SaaS 公司工作、需要處理高複雜度技術問題的工程師,這個層次的回饋品質是實質性的差距。
場景三:自由接案者與中小企業主的繁體中文商業文件產出
有大量的自由工作者、顧問、以及中小企業主,日常需要產出各種繁體中文商業文件:提案書、合約摘要、行銷文案、客戶報告等。這個族群對 AI 寫作的需求很具體:文字要流暢、用語要符合華語市場的商業語境,而且不能有明顯的「AI 翻譯腔」。在長篇繁中文件上,Opus 的段落邏輯連貫性通常優於 Sonnet,尤其是在需要同時維持多個論點並讓它們在結尾收束成一個清晰結論的情境下。如果你每個月需要交付大量繁中商業文件,Opus 在這類長文上的穩定度,值得你把訂閱費用放進評估。