The “Cheap Inference” Pitch — Does Together AI Actually Deliver?
Here’s a number that makes engineering managers do a double-take: running an open-source model like Llama 3 through a serverless inference provider can cost a fraction of what you’d pay for a comparable proprietary API call. Not “a little cheaper.” A different order of magnitude, depending on the model and the workload. That gap is the entire reason platforms like Together AI exist — and the entire reason your CFO keeps forwarding you links to them.
But “cheaper per token” is the oldest trick in the SaaS playbook. Cheaper per token means nothing if the latency is awful, the uptime is shaky, the model you actually need isn’t supported, or you spend three weeks rewriting your stack to migrate off the OpenAI SDK. The real question isn’t “is Together AI cheap?” — it obviously markets itself that way. The real question is whether the total cost of ownership, including developer time and reliability headaches, actually beats the alternatives for your specific situation.
So that’s the angle here: pricing and value, compiled from Together AI’s official documentation, public pricing pages, and the reviewer consensus floating around Reddit, Hacker News, and developer forums. No hands-on lab claims — just a clear-eyed read of the evidence on whether Together AI is the affordable inference platform it claims to be, or just another “open-source but with a margin” middleman.
Together AI in One Paragraph
Together AI is a cloud inference and fine-tuning platform built around open-source and open-weight models. Instead of self-hosting Llama, Mistral, DeepSeek, Qwen, and dozens of other models on your own GPU infrastructure — which means provisioning A100s or H100s, managing CUDA, batching, and autoscaling — you call them through an API that’s intentionally OpenAI-compatible. According to its official documentation, the platform offers serverless per-token pricing for a wide model catalog, plus dedicated endpoints and GPU clusters for teams with heavier or more predictable workloads.
The pitch sits in a specific niche. You’re not locked into one vendor’s proprietary model (the OpenAI/Anthropic route), but you’re also not signing up for the operational pain of running your own inference stack from scratch. It’s the “I want open-source economics without becoming a DevOps shop” play. Whether that middle ground is the right place to stand depends heavily on your volume, your team size, and how much you value not paging an engineer at 2am when a GPU node falls over. Let’s get into the numbers.
Pricing and Value: The Comparison That Actually Matters
I’ll be direct about the table below: exact per-token rates shift frequently across every provider in this space, so treat these as directional comparisons of the model rather than guarantees of a specific figure. Always confirm live pricing on each provider’s official page before you budget. What’s stable is the shape of the tradeoff — and that’s what this table captures.
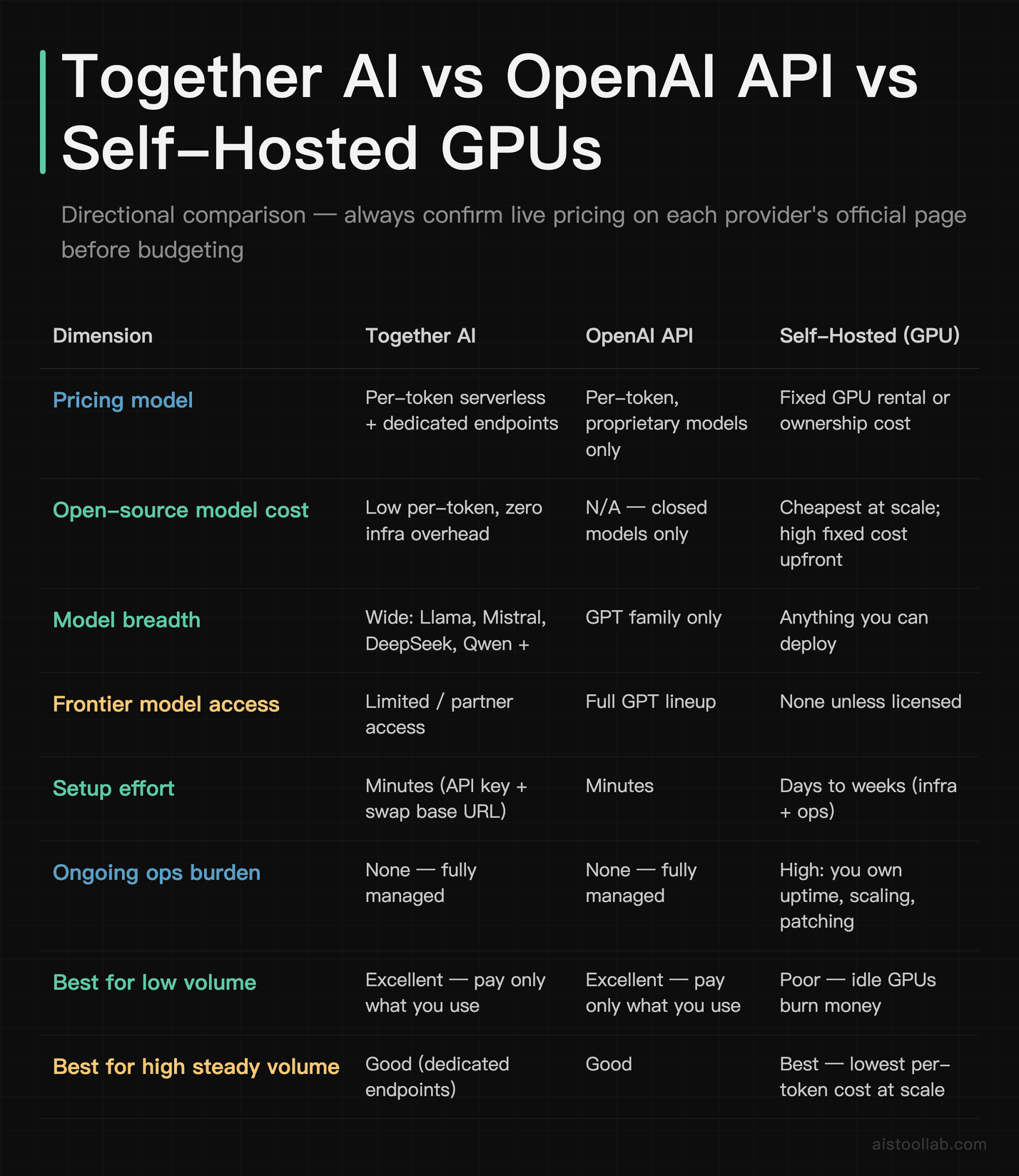
The headline takeaway from this matrix: Together AI wins decisively in the “low-to-moderate volume, want open-source models, don’t want to run infrastructure” quadrant. That’s a huge slice of the real market — startups, indie developers, and teams prototyping fast. Where it gets murkier is at the extremes. If you genuinely need GPT-4-class proprietary reasoning, OpenAI is still the destination. If you’re pushing billions of tokens a month at high, predictable utilization, owning or long-term-renting your own GPUs can eventually undercut any per-token provider. Together AI’s sweet spot is the broad middle — and most teams live in that middle.
For a deeper look at when open weights genuinely beat closed models on cost and capability, I went into the tradeoffs in detail in Open-Source LLMs vs Cloud-Based Models in 2026. The short version: the “open-source is always cheaper” claim is true on raw token price but ignores the engineering tax of self-hosting — which is exactly the tax Together AI is designed to remove.
Model Selection: The Real Differentiator

Cost is the headline, but breadth is what keeps people on the platform. According to Together AI’s official model catalog, you get serverless access to a deep bench of open-weight families — the Llama series from Meta, Mistral and Mixtral, DeepSeek’s reasoning and coding models, Qwen, and a long tail of community and specialized models for embeddings, vision, and code. That matters more than it sounds.
The practical benefit is that you can model-shop without re-architecting. Building a customer support bot? Start with a smaller, cheaper Llama variant, and if quality isn’t there, bump up to a larger model or swap to DeepSeek for reasoning-heavy tasks — same API, one line changed. On a closed platform you’re stuck inside one vendor’s quality-vs-price curve. Here, you arbitrage across the entire open ecosystem. For high-volume use cases, the ability to route easy requests to a cheap small model and only escalate hard ones to a larger model is where the serious savings live.
Two honest caveats. First, “proprietary frontier access” is limited compared to going direct to OpenAI or Anthropic — if your product’s moat depends on the absolute strongest closed reasoning model, this isn’t a full replacement for those vendors. Second, model availability on any serverless catalog changes over time; specific models get added, deprecated, or moved to dedicated-only. Check the live catalog for whatever you’re depending on rather than assuming it’ll be there forever. If you want a framework for choosing between models on actual capability rather than vibes, the Hugging Face Model Hub Tutorial 2026 pairs well with this — evaluate first, then deploy on whatever inference layer fits.
Latency and Throughput: The Honest Picture
Here’s where I have to set expectations carefully, because this is the area where compiled evidence beats made-up benchmarks. Together AI positions itself on optimized inference — its documentation and public materials emphasize speed-tuned serving stacks for open models. Public reviews generally describe latency as competitive and good enough for most production chat and generation workloads. But “competitive” is the honest word, not “fastest on the planet.”
If raw tokens-per-second and ultra-low time-to-first-token are your single obsession — think real-time voice agents or latency-critical UX — the dedicated speed-specialist providers built on custom silicon are the names that come up most often in that conversation. I broke down that category in the Groq AI Inference Platform Review 2026, and the short version is that purpose-built inference hardware can post latency numbers that general-purpose GPU clouds find hard to match. Together AI’s trade is breadth and price flexibility rather than being the outright speed king.
What you can reasonably expect, based on the documented behavior and reviewer consensus: smaller models (7B–8B class) return responses quickly enough for interactive apps, while larger models (70B+ and big mixture-of-experts) carry the latency you’d expect from their size anywhere. Throughput scales better when you move from shared serverless to a dedicated endpoint, because you’re no longer contending with other tenants. The pragmatic move is to benchmark your own prompts on your own traffic pattern — synthetic numbers rarely predict your reality, a point I hammered in Production vs Synthetic. Twenty minutes with your actual workload tells you more than any vendor chart.
ROI by Team Size and Usage Pattern

This is the section your finance person actually cares about, so let’s make it concrete by profiling different team shapes rather than waving at “it depends.”
The solo developer / indie hacker
You’re building a side project or a small SaaS, you have spiky, unpredictable traffic, and you absolutely cannot justify paying for idle GPUs. For you, serverless per-token pricing is close to ideal — you pay essentially nothing when no one’s using your app, and the open-source model prices keep your unit economics sane even before you have revenue. Self-hosting at this stage is financial self-harm: a single always-on GPU instance can cost more per month than your entire app earns. Together AI’s value here is high and the risk is low.
The early-stage startup (2–15 people)
You’ve got product-market fit signals and growing but still uneven volume. The ROI case stays strong because you avoid hiring an ML-infra specialist purely to keep inference running — that salary alone dwarfs most inference bills at this stage. The smart pattern here is tiered routing: cheap small models for the bulk of requests, larger models only when quality demands it. As certain endpoints become high-traffic and predictable, you graduate those specific workloads to dedicated endpoints for better cost-per-token and consistent latency, while keeping the long tail on serverless.
The scaled product (high, steady volume)
This is the one case where the math gets genuinely competitive and you should run real spreadsheets. If you’re pushing enormous, predictable token volume at high GPU utilization, self-hosting or long-term reserved GPU capacity can undercut any per-token provider — that’s just how fixed-cost economics work once utilization is high. But “high utilization” is the load-bearing phrase. Most teams overestimate theirs, end up paying for half-idle hardware, and would have been better off on managed dedicated endpoints. The honest answer: model both scenarios with your real numbers before committing capital to your own fleet.
Developer Experience: The Quiet Selling Point
The smartest design decision Together AI made — and reviewers consistently call this out — is OpenAI SDK compatibility. According to the official documentation, you can point the standard OpenAI client at Together’s base URL, drop in your API key, and start calling open-source models with code you’ve largely already written. For teams already built on the OpenAI ecosystem, that turns a potentially scary migration into a configuration change you could ship before your coffee gets cold.
That compatibility is worth more than it first appears. The biggest hidden cost of switching inference providers is usually engineering time, not the bill itself. When the migration cost is “change two lines and run your test suite,” the calculus of trying a cheaper provider flips entirely — you can A/B a new model on real traffic, measure quality and cost, and roll back instantly if it disappoints. That low switching friction is, ironically, one of the strongest arguments for the platform.
Beyond the API, the documented feature set includes fine-tuning, dedicated endpoints, and tooling for embeddings and RAG-style workloads. Public reviews on developer experience skew positive on the API design and docs, with the usual grumbles you’ll find about any growing platform — occasional model deprecations to track, and the need to monitor a catalog that evolves. Nothing in the reviewer consensus suggests the kind of integration pain that would scare off a competent team.
Pros and Cons — The Compiled Verdict

Pulling together the documentation and the reviewer consensus, here’s where things net out.
What’s genuinely good:
- Open-source economics without the ops burden — you get cheap open-model pricing without provisioning or babysitting GPUs.
- Exceptional model breadth — Llama, Mistral, DeepSeek, Qwen and a deep long tail, all behind one API.
- Near-zero migration friction — OpenAI-compatible SDK means trying it costs almost no engineering time.
- Flexible scaling path — start serverless, graduate hot workloads to dedicated endpoints as volume grows.
- Strong fit for the most common team shapes — indie devs and early-stage startups get the clearest ROI.
What to watch out for:
- Not the absolute latency champion — speed-specialist providers on custom silicon often post lower latency for real-time use cases.
- Limited proprietary frontier access — if you need GPT-4-class closed reasoning, this doesn’t fully replace going direct.
- Cloud data model — if regulatory or privacy needs demand on-prem control, self-hosting still wins.
- Catalog churn — models get added and deprecated; don’t assume any specific model is permanent.
- Self-hosting can beat it at extreme scale — at very high, steady utilization, owning hardware may be cheaper.
Frequently Asked Questions
Is Together AI actually cheaper than the OpenAI API?
For open-source and open-weight models, yes — generally and often dramatically so on a per-token basis, because you’re running models like Llama and Mistral that don’t carry proprietary frontier-model pricing. But the comparison isn’t strictly apples-to-apples, and that’s the important nuance. OpenAI’s GPT models and the open models on Together AI are different products with different capability profiles. If a smaller open model handles your task just as well as GPT-4-class output, the savings are very real. If your use case genuinely needs the strongest proprietary reasoning, the cheaper token price is irrelevant because the cheaper model can’t do the job. The honest way to evaluate this is to define your quality bar first, find the cheapest model that clears it, and only then compare prices. For a large share of production tasks — summarization, classification, structured extraction, routine chat — a well-chosen open model on Together AI clears the bar at a much lower cost. Always confirm current rates on both providers’ official pricing pages before budgeting, since these change frequently.
Can I just swap my existing OpenAI code over to Together AI?
Largely, yes — and this is one of the platform’s strongest selling points. According to the official documentation, Together AI offers OpenAI SDK compatibility, meaning you can keep using the standard OpenAI client library, change the base URL to point at Together’s endpoint, plug in your Together API key, and call open-source models with code you’ve mostly already written. In practice the migration for a basic chat-completion workflow is closer to a configuration change than a rewrite. The caveats: you’ll need to update model identifiers to Together’s model names, and any features specific to OpenAI’s proprietary ecosystem (certain tool-calling behaviors, specific endpoints, or OpenAI-only model capabilities) may behave differently or not exist. The smart approach is to run your existing test suite against the new provider on a branch, A/B a portion of real traffic, and measure both quality and cost before committing. Because the switching cost is so low, trying it is nearly free in engineering hours — which is itself a reason to test it rather than assume.
What models does Together AI support, and will my model still be there next year?
The catalog is broad and centered on open-weight models: the Llama family from Meta, Mistral and Mixtral, DeepSeek’s reasoning and coding models, Qwen, plus embedding models, vision models, and a long tail of specialized community options. According to the official model catalog, this spans chat, code, embeddings, and more. The honest caveat on longevity: serverless model availability across every provider in this space evolves. Models get added as new open releases drop, and older or less-used ones can be deprecated or moved to dedicated-only hosting. This isn’t unique to Together AI — it’s the nature of a fast-moving open-model ecosystem. The practical defense is to not hard-depend on a single specific model without a fallback, to subscribe to the provider’s deprecation notices, and to design your code so swapping a model identifier is trivial (which the OpenAI-compatible API makes easy). If a particular model is mission-critical, a dedicated endpoint gives you more stability than relying on the shared serverless catalog.
How does latency compare to speed-focused providers like Groq?
Based on compiled public reviews and documentation, Together AI’s latency is best described as competitive and production-adequate for most chat and generation workloads, but it’s not positioned as the outright speed leader. Providers built on custom inference silicon are the names that dominate the “lowest latency” conversation, and for genuinely latency-critical applications — real-time voice agents, ultra-responsive interactive UX — they often post numbers that general-purpose GPU clouds find hard to match. I covered that category in detail in the Groq review. Together AI’s value proposition is different: breadth of models and pricing flexibility rather than being the fastest possible token machine. For the vast majority of applications — a support chatbot, content generation, RAG retrieval, batch processing — its speed is perfectly fine and unlikely to be your bottleneck. The only reliable way to know if it’s fast enough for your app is to benchmark your actual prompts on your actual traffic pattern, because synthetic latency charts rarely predict the experience your users get in production.
Should a solo developer use Together AI or self-host?
For a solo developer or indie hacker, Together AI’s serverless model is almost always the better call, and the reason is brutal economics. Self-hosting means paying for a GPU instance that runs 24/7 regardless of whether anyone is using your app. For a side project or early SaaS with spiky, unpredictable traffic, that always-on cost can easily exceed your entire revenue — you’d be burning money on idle silicon. Serverless per-token pricing flips this: you pay essentially nothing when traffic is zero and scale costs directly with usage. You also dodge the entire operational burden — no CUDA, no autoscaling config, no 2am pages when a node dies, no time spent on infra instead of product. The only scenarios where a solo dev should consider self-hosting are strict data-privacy requirements that forbid cloud processing, or a genuine hobbyist interest in running models on hardware you already own. For everyone else building a real product with limited time, managed serverless inference is the rational, time-respecting choice.
When does self-hosting actually become cheaper than Together AI?
Self-hosting wins on raw cost only when you have high and steady GPU utilization — that’s the load-bearing condition most teams get wrong. The economics are simple: owning or long-term-renting GPUs is a fixed cost, so the more tokens you push through that fixed capacity, the lower your effective cost-per-token. At very high, predictable volume where your GPUs run near-continuously, self-hosting can undercut any per-token provider. The trap is that real traffic is rarely as steady as projections assume. Teams provision for peak, run at half utilization, and end up paying for idle hardware that erases the theoretical savings — often landing them worse off than managed dedicated endpoints would have. You also have to price in the engineering cost: someone has to build and maintain the serving stack, handle scaling, patching, and uptime, and that salary is real money. The honest recommendation is to model both options with your actual token volume and a realistic utilization estimate, then add the fully-loaded cost of the engineering time. For most teams below massive scale, managed inference wins once you count everything.
Is Together AI suitable for production, or just prototyping?
It’s positioned and used for production, not just experimentation. The platform offers dedicated endpoints and GPU infrastructure specifically aimed at teams running real workloads that need consistent latency and throughput without competing against other tenants for shared serverless capacity. The typical maturity path reflected in reviewer discussions looks like this: prototype on serverless where pay-per-use and zero setup let you move fast, validate which models hit your quality bar, then promote your high-traffic, latency-sensitive endpoints to dedicated capacity as you scale. That said, “production-ready” always depends on your specific reliability and compliance requirements. If you operate under strict data-residency or regulatory constraints, you’ll need to verify that the platform’s data handling and any available compliance certifications meet your obligations — check the official documentation and, for serious deployments, talk to their team directly. For the typical startup or product team without exotic compliance needs, the documented feature set and reviewer consensus support using it as a genuine production inference layer rather than just a sandbox.
Does Together AI support fine-tuning, or only inference?
Both. According to the official documentation, the platform supports fine-tuning open models in addition to serving them for inference, which matters if your use case benefits from a model adapted to your domain, tone, or task format. Fine-tuning a smaller open model on your specific data can sometimes let it match or beat a much larger general model on your narrow task — which is both a quality and a cost win, since you then run inference on a cheaper, smaller model. The practical workflow is to start with off-the-shelf models to validate your use case, and only invest in fine-tuning once you’ve confirmed there’s a quality gap that prompt engineering and model selection can’t close. Fine-tuning adds complexity and cost, so it’s not the first lever to pull — but having it on the same platform as your inference avoids the friction of stitching together separate training and serving providers. As always, check the current documentation for which specific models are fine-tunable and the exact pricing, since the supported list and rates evolve over time.
The Verdict: Who Should Actually Use It

After weighing the documented capabilities and the reviewer consensus, the picture is refreshingly clear for a category that’s usually muddy. Together AI isn’t trying to be the fastest inference provider or the home of frontier proprietary models — and pretending otherwise would be the kind of hype I try to avoid. What it is, based on the compiled evidence, is the most sensible default for teams that want open-source model economics without signing up to run their own GPU fleet.
If you’re a solo developer or an early-stage startup with spiky traffic and a tight budget, this is close to an easy yes — the serverless pricing, the model breadth, and the near-zero migration cost stack up in your favor, and the downside risk of trying it is tiny. If you’re chasing the absolute lowest latency for a real-time voice product, look hard at the speed-specialist providers first. If you need GPT-4-class proprietary reasoning as your core differentiator, go direct to that vendor. And if you’re operating at genuinely massive, steady scale, do the self-hosting spreadsheet honestly before you commit either way.
For everyone in the broad middle — which is most of you — the next step is simple and cheap: grab an API key, point your existing OpenAI-compatible code at it, and benchmark your real prompts on your real traffic. Because switching cost is basically two lines of config, you’ll know within an afternoon whether the value lives up to the pitch. That’s a far better use of your time than reading one more pricing table — including this one.
Last updated: 2026
Found this review helpful?
Subscribe to aistoollab.com for weekly AI tool reviews, tutorials, and comparisons — straight to your inbox.
👉 Browse the AI Tools Library to find the right tools for your workflow.