I switched claude.ai to Fable 5 and gave it one tricky debugging task — here’s what stood out
Claude Fable 5 launched in June 2026, got pulled mid-June under U.S. export controls, and came back online on July 1. With all the noise, the real question is simple: is it worth using? This isn’t a spec reprint. I used my own Claude subscription, switched the model to Fable 5 inside claude.ai, and gave it a debugging task with a hidden trap — capturing the actual screens. The single thing that stood out: at the highest effort, it didn’t just fix the bug I described; it proactively caught a second bug I never mentioned, hiding in an edge case. That “catches what you missed” behavior is where it earns its price.
Below I keep hands-on and official facts clearly separated: hands-on is labeled and backed by a real screenshot; official facts are labeled and linked.
Contents
How to use Fable 5 and what it costs (July 2026 status)
Here’s the actual UI. In claude.ai’s model menu, Fable 5 sits at the top, tagged “Included until July 7 / For your toughest challenges” — matching Anthropic’s note that after the reopening it’s included in paid plans through July 7. The moment I picked Fable 5, the effort control jumped to “High” on its own (Sonnet 5 defaults to Medium):
Both screenshots below come from the same hands-on session as the Chinese version of this review — the same batch of screenshots, logged in our screenshot record on 2026-07-05, and used by both language versions.
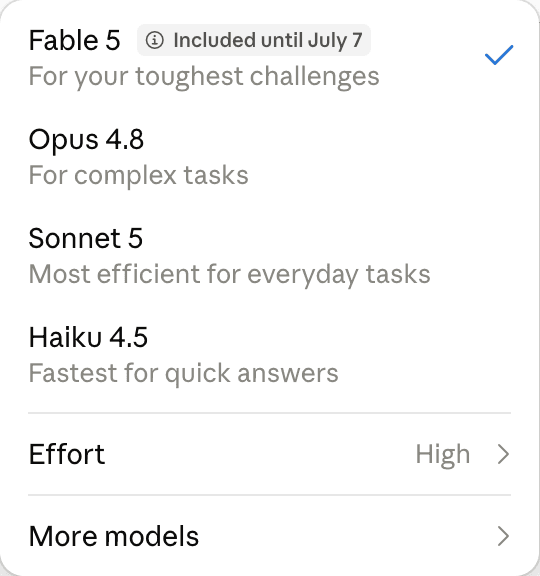
Official facts (not my testing — sources linked):
- Positioning & specs: Anthropic calls Fable 5 its “most capable widely released model” (model ID
claude-fable-5), with a 1M-token context window, up to 128k output tokens, and pricing of $10 per million input tokens and $50 per million output tokens. - Effort, not on/off thinking: its only mode is adaptive thinking (can’t be disabled); you control depth and cost with the effort parameter. Anthropic says at the highest effort it “reflects on and validates its own work” — which I could actually feel in the test below.
- It can refuse — and fall back to Opus 4.8: a refusal returns
stop_reason: "refusal"as a normal HTTP 200, and you retry on another model via server- or client-side fallback. Anthropic says this triggers in under 5% of sessions (announcement). - Why it’s back on July 1: export controls imposed June 12 led Anthropic to suspend access; controls lifted June 30, and Fable 5 reopened globally July 1 with a stronger classifier. Paid plans get it at up to 50% of weekly limits through July 7, then usage-credit pricing (redeployment note).
The test: a debugging task with a hidden trap
Instead of an abstract puzzle, I used something engineers hit daily: code that looks right but has two traps. The function is meant to return the second-largest DISTINCT number, but it’s buggy:
def second_largest(nums):
nums = sorted(nums, reverse=True)
return nums[1]
# e.g. second_largest([5,5,3,2]) should return 3The traps are layered: the obvious bug is “no de-duplication” (for [5,5,3,2], nums[1] grabs the second 5, not 3). The subtler one: if there are fewer than two distinct values, nums[1] throws IndexError. I only told it about the first — to see if it would find the second on its own.
What Fable 5 actually did (at High effort)
It caught both. Beyond the de-dup bug I described, it proactively flagged that a list with fewer than two distinct values would raise IndexError — the trap I deliberately left out. Its fix was clean: sorted(set(nums), reverse=True) to de-dup, plus if len(unique) < 2: return None to guard the edge. Then it validated its own answer with five edge-case checks ([5,5,3,2]→3, [7]→None, [4,4,4]→None, []→None, [1,2]→1), and even discussed the design trade-off — set()‘s cost, an O(n) single-pass alternative for large lists, and whether to return None or raise ValueError. That last layer — reasoning about design, not just producing runnable code — is the part a strong senior engineer would add, and it’s what the effort setting buys you.
![Real screenshot of the model's High-effort answer on the debugging task: it flags that sorted(nums, reverse=True)[1] does not remove duplicates (returns 5 instead of 3) and can throw IndexError, then gives a corrected set-based version handling the empty, single, and all-same-value cases.](https://aistoollab.com/wp-content/uploads/2026/07/8881-handson-high-effort-debug-answer.png)
So is it actually better than Opus or Sonnet? Honest take
Honestly, this specific task is solvable by Opus 4.8 and probably Sonnet 5 too — it isn’t Fable-only hard. What stood out in the hands-on wasn’t “can it solve it” but “how far it goes on its own”: at High effort it hunts for edge cases, writes its own tests, and weighs design choices, like a more careful senior dev. Anthropic’s headline numbers (SOTA, top FrontierBench, first past 90% on a core analytics benchmark) also come from the hardest, longest tasks. So:
- Everyday tasks: you may not feel it beating Opus/Sonnet — but you’ll pay more.
- Hard, long, can’t-fail tasks: that proactive, self-validating rigor is where it saves you debugging and rework.
- Cost and limits are real: $50 per million output tokens isn’t cheap, and it burns through claude.ai limits faster — after just a few prompts my account flagged it was approaching the weekly limit. It’s included through July 7, then usage credits.
- It can refuse: cybersecurity/bio/chem/health prompts may be declined and handed to Opus 4.8 — plan for it if you work in those areas.
Who it’s for — and who should wait
Reach for it if you do the heaviest reasoning, long-horizon agentic runs, or complex analysis, want the model to check its own work, and can justify the higher cost — and turn effort up to get its value. Hold off if your workload is everyday Q&A, writing, or ordinary code — in my testing Opus 4.8 was already plenty, and the Fable 5 premium (and heavier usage draw) may not pay off. For a wider comparison, see our AI models ranking and why benchmarks don’t predict real production.
FAQ
How do I access Fable 5 right now?
In claude.ai, pick “Fable 5” from the model menu (shown above). Developers use the Claude API and platforms like AWS, Google Cloud, and Microsoft Foundry. It reopened globally on July 1. Selecting it sets effort high by default; you can adjust it.
How much does Fable 5 cost?
Per Anthropic’s docs, $10 per million input tokens and $50 per million output tokens on the API. In claude.ai, paid plans include Fable 5 through July 7, 2026, then it shifts to usage-credit pricing. Check the official announcement for current billing.
Is it really better than Opus 4.8?
Anthropic calls it its most capable released model, leading most benchmarks. But in my debugging test, “can it solve it” was close; the real difference was how thoroughly it hunted edge cases, self-validated, and discussed design at high effort — plus the hardest, longest tasks Anthropic cites. Everyday use may not show a gap.
Why was it unavailable, and is it back for good?
The U.S. government imposed export controls on June 12, 2026, and Anthropic suspended access. Controls were lifted June 30, and Fable 5 reopened globally on July 1 with a stronger safety classifier.
Will it refuse requests?
Yes. Fable 5’s safety classifiers can decline cybersecurity/bio/chem/health prompts and fall back to Opus 4.8; Anthropic says this triggers in under 5% of sessions. Wire up the fallback path when integrating via API.
The “hands-on” sections are the author’s real session in claude.ai with a Claude subscription, model set to Fable 5 (High effort), running the debugging task; the screenshot is unmodified. “Official” sections cite Anthropic’s docs and announcements, linked inline. Specs and pricing follow Anthropic’s latest notices; the test reflects this one session only.
Last updated: July 2026
Found this hands-on useful?
👉 Browse the AI Tools Library to find the right tools for your workflow.