The Dirty Secret About AI Benchmarks Nobody Wants to Say Out Loud
Here’s a take that’ll annoy half the people on Hacker News: most of the benchmark scores you see in launch blog posts are theater. Not lies, exactly — the numbers are real — but the way they’re cherry-picked, the way models are quietly tuned to ace the test set, and the way a 0.4-point bump on some leaderboard gets spun into “state of the art” reads more like marketing than measurement.
I’ve spent the better part of a decade watching AI labs wave benchmark numbers around like Olympic medals. And after testing dozens of models against my own real workloads — code, research summaries, long-context reasoning — I’ve come to a slightly uncomfortable conclusion: the benchmark that wins the press release is rarely the one that predicts how a model performs on your actual job.
So instead of another “MMLU good, number big” roundup, I want to rank the major AI benchmarks of 2026 by something more useful: how relevant they actually are to real evaluation, and how widely the industry still trusts them. Some old favorites have aged terribly. A couple of newer ones are genuinely earning their place. Let’s get into it.
Contents
How I’m Ranking These (The Evaluation Criteria)

A benchmark isn’t “good” or “bad” in a vacuum — it depends on what you’re trying to find out. So I scored each one across five dimensions that matter when you’re deciding whether to trust a number.
Real-world relevance is the big one: does a high score actually correlate with the model being useful at tasks people care about? Difficulty headroom matters because a benchmark where frontier models all cluster at 90%+ has basically stopped measuring anything — it’s saturated. Gaming resistance covers how hard it is to inflate a score through contamination (the test data leaking into training) or targeted fine-tuning. Adoption reflects whether labs, leaderboards, and researchers still report it in 2026 — a benchmark nobody cites is hard to compare against. And reliability covers whether the scoring methodology is consistent and reproducible, or whether small prompt changes swing results wildly.
If you want the broader picture on how these feed into model selection, I went deep on that in my AI Model Performance Metrics Explained 2026 piece. This article is specifically about the benchmarks themselves — their guts, their flaws, and when to actually reach for each one.
The 2026 Benchmark Ranking at a Glance
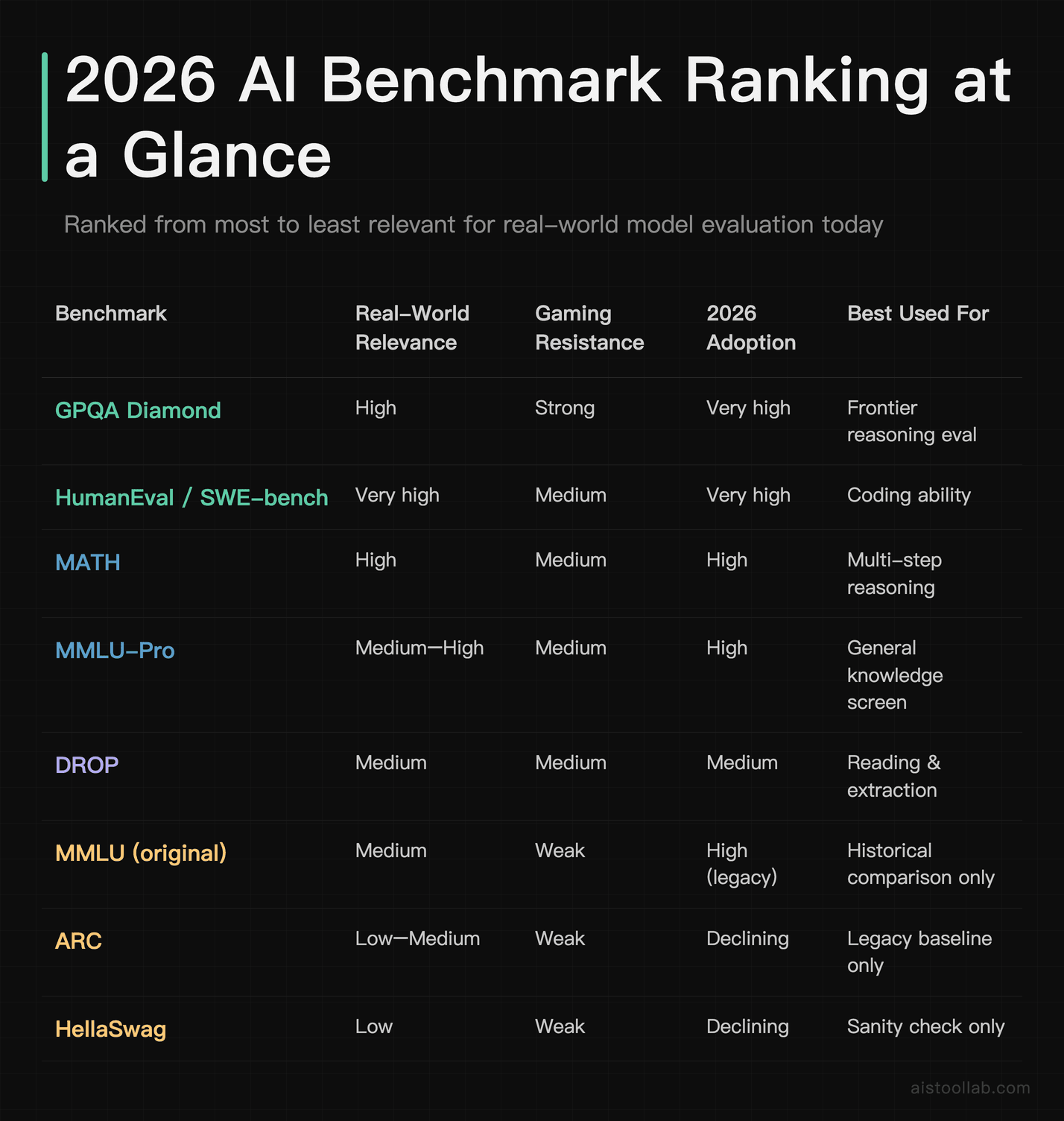
That table is the whole argument in miniature. Notice the pattern: the benchmarks losing relevance aren’t bad tests — they’re finished tests. Models solved them. Let’s go through the ranking from most to least relevant in 2026.
1. GPQA — The Benchmark That Actually Still Hurts
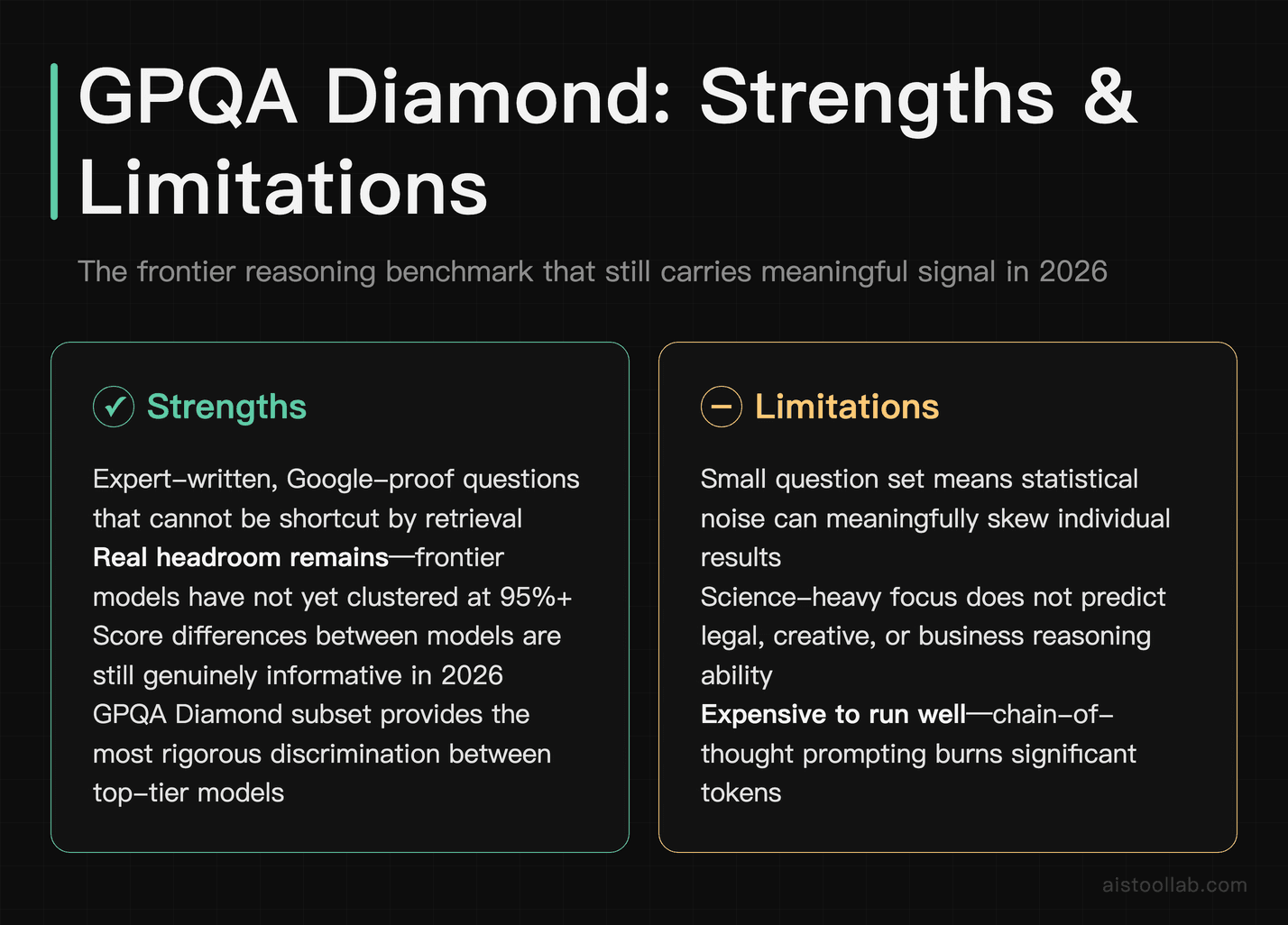
GPQA (“Graduate-Level Google-Proof Q&A”) is the closest thing the field has to a benchmark that frontier models can’t just memorize their way through. The questions were written by domain experts in biology, physics, and chemistry, and deliberately designed so that even smart non-experts with full internet access struggle to answer them. That “Google-proof” design is the whole point — you can’t shortcut it by retrieving an answer.
What makes GPQA, and especially the harder GPQA Diamond subset, so valuable in 2026 is that it still has real headroom. Top models have improved on it, but nobody’s pinned it at 95%+ and called it a day. That means a genuine score difference between two models tells you something. When a lab reports GPQA Diamond results, I pay attention in a way I no longer do for MMLU.
The limitations are honest ones: the question set is relatively small, so noise matters, and because it’s science-heavy, a strong GPQA score doesn’t necessarily predict good performance on, say, legal reasoning or creative writing. It’s also expensive to run well, since the best results come from chain-of-thought prompting that burns tokens. But if you’re evaluating reasoning-class models — the kind I discussed in Best Large Language Models Ranked by Performance Metrics in 2026 — this is the first number I look for.
2. HumanEval and SWE-bench — Where Coding Gets Real
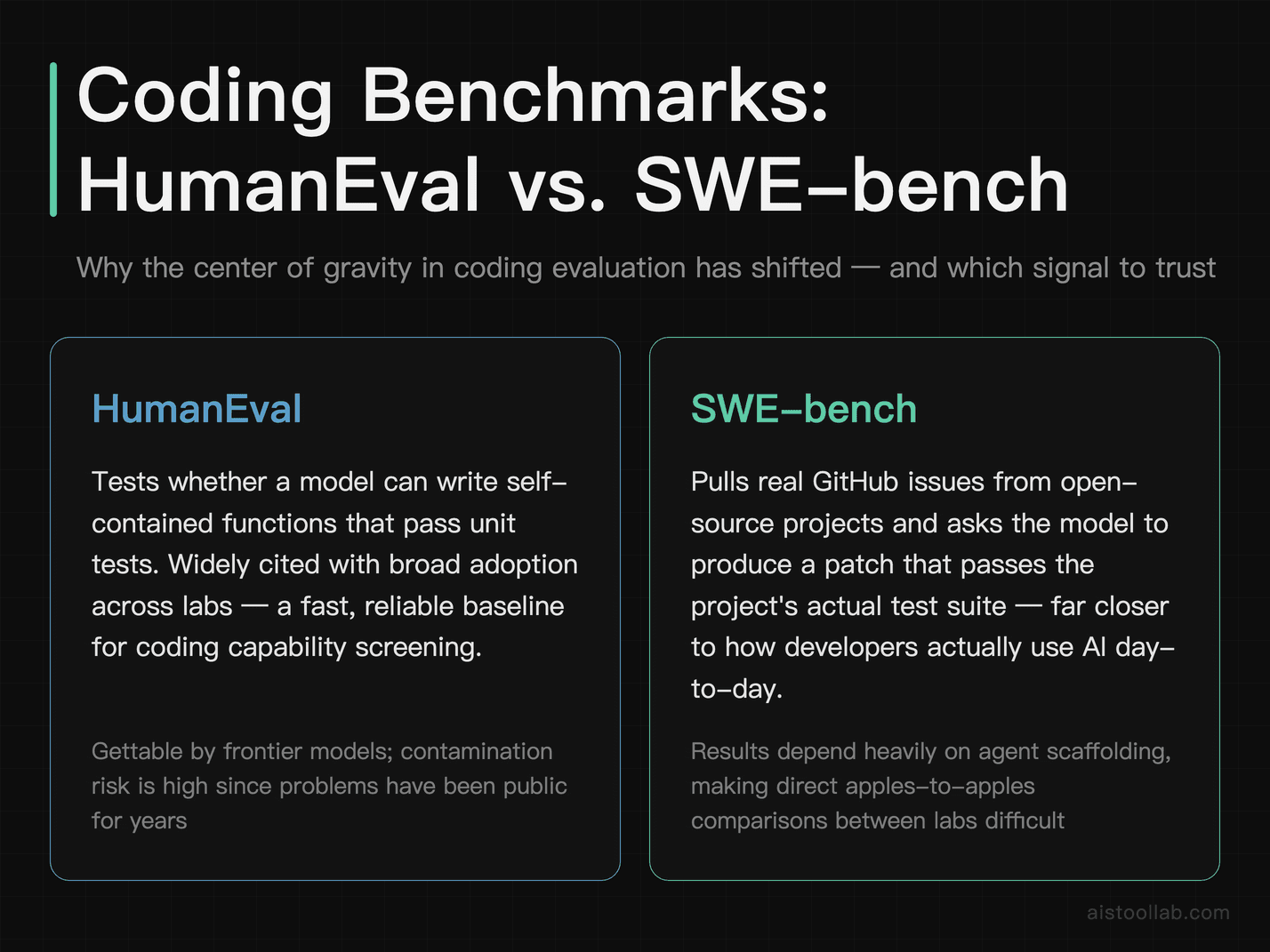
Coding benchmarks deserve a joint entry because the center of gravity has shifted. HumanEval — the classic “write a function to pass these unit tests” benchmark — is still cited everywhere, and it’s genuinely useful for measuring whether a model can produce correct, self-contained code. But it’s also gettable. Frontier models score very high on it now, and contamination is a real worry since the problems have been public for years.
That’s why SWE-bench has become the benchmark coders actually argue about. Instead of toy functions, it pulls real GitHub issues from real open-source projects and asks the model to produce a patch that passes the project’s actual test suite. This is night-and-day more relevant to how developers use AI — it’s the difference between “can you write FizzBuzz” and “can you fix this bug buried in a 40-file Django repo.” A strong SWE-bench number is one of the few benchmark results that maps cleanly onto “will this thing save me time on Monday.”
The catch: SWE-bench is harder to administer, results depend heavily on the agent scaffolding around the model, and that makes apples-to-apples comparisons tricky. Two labs reporting different SWE-bench numbers might just be using different harnesses. Still, for anyone evaluating coding assistants — and this ties directly into the AI Agents Explained world of autonomous coding tools — these two benchmarks together are the most decision-relevant numbers on this whole list.
3. MATH — Reasoning You Can’t Fake
The MATH benchmark consists of competition-level math problems, the kind you’d see in high-school olympiads, requiring multi-step symbolic reasoning rather than retrieval. What I like about it is that the answer is either right or it isn’t — there’s no fuzzy grading, no “well, partially correct.” Either the model worked through the problem and landed on the correct value, or it didn’t.
MATH earned a lot of credibility because for a long time it genuinely stumped models, and the climb up its scoreboard tracked closely with the rise of explicit reasoning and chain-of-thought techniques. When models started getting much better at MATH, it usually meant they’d gotten meaningfully better at structured problem-solving generally — a correlation that doesn’t always hold for knowledge benchmarks.
The reliability concern is contamination and the rise of reasoning models that may have seen similar problem patterns extensively during training. There’s also the question of whether raw math skill predicts the reasoning you care about — being great at integral calculus doesn’t guarantee good judgment on an ambiguous business problem. But as a clean, gaming-resistant test of step-by-step reasoning, MATH still earns its high ranking. Just don’t treat it as a proxy for general intelligence.
4. MMLU-Pro — The Patch for a Saturated Classic
MMLU-Pro exists because the original MMLU broke. As frontier models climbed into the high 80s and beyond on standard MMLU, the benchmark stopped discriminating between good and great models — everyone bunched up at the top, and a chunk of the remaining errors were arguably bad questions rather than model failures. MMLU-Pro responds by adding harder questions, expanding answer options to reduce lucky guessing, and leaning more on reasoning than recall.
In practice, this restored some of the signal. The spread between models is wider on MMLU-Pro than on the original, which is exactly what you want from a benchmark — discrimination. It’s become a standard reporting line on most 2026 leaderboards, and it’s a reasonable single-number proxy for broad knowledge plus light reasoning across dozens of subjects.
That said, it inherits some of MMLU’s DNA: it’s still multiple-choice, which never perfectly mirrors open-ended real-world tasks, and “broad knowledge across 57-ish domains” is a strange thing to optimize for if your actual use case is narrow. I treat MMLU-Pro as a useful generalist screen — a way to filter out clearly weak models — rather than as the deciding factor. If two models are within a couple points here, that gap tells you almost nothing about which will serve you better.
5. DROP — The Underrated Reading Test
DROP (Discrete Reasoning Over Paragraphs) asks a model to read a passage and then perform operations on it — counting, sorting, comparing, simple arithmetic over the facts in the text. It’s less glamorous than the reasoning benchmarks, but it targets something genuinely useful: can the model actually extract and manipulate information from a document rather than just vibe-summarizing it?
For anyone building retrieval pipelines, document-processing tools, or anything that reads contracts and spreadsheets, DROP-style ability is exactly the capability that matters. The problem is that DROP is showing its age — strong models handle a lot of it comfortably now, so saturation risk is climbing, and it doesn’t capture the messier reality of long documents and multi-hop reasoning across many pages.
I keep DROP on the relevant list because reading-and-reasoning is so central to practical workloads, but I’d describe it as a benchmark in transition. It’s being supplemented by long-context and multi-document evaluations that better reflect 2026 use cases. If you’re evaluating models for document-heavy work, look at DROP as one input among several, not the headline.
6, 7, 8 — MMLU, ARC, and HellaSwag: Respect the Veterans, Retire the Tests

I’m grouping the legacy three because they share a fate: they were excellent benchmarks that frontier models have effectively solved. Original MMLU still gets reported constantly, mostly for historical continuity — it’s useful for comparing a 2026 model against a 2023 one on the same scale. But for distinguishing today’s top models? It’s done. The scores are too high and too bunched, and contamination concerns are serious given how long the questions have circulated.
ARC (the AI2 Reasoning Challenge, grade-school science questions) and HellaSwag (commonsense sentence completion) are even further along. Frontier models max these out so thoroughly that a high score tells you nothing except “this model is not broken.” HellaSwag in particular was always a bit of a strange test — it measures whether a model picks the most plausible continuation of a scenario, which mattered a lot more in the pre-instruction-tuning era.
None of this means they were bad benchmarks. They drove real progress in their day. But in 2026 they function as sanity checks, not differentiators. If a new model can’t ace HellaSwag, something is deeply wrong — but acing it earns no credit. I cover why this saturation keeps happening in Open LLM Leaderboard Review 2026, because it’s the single biggest reason leaderboards keep needing new benchmarks bolted on.
Who Should Use Which Benchmark
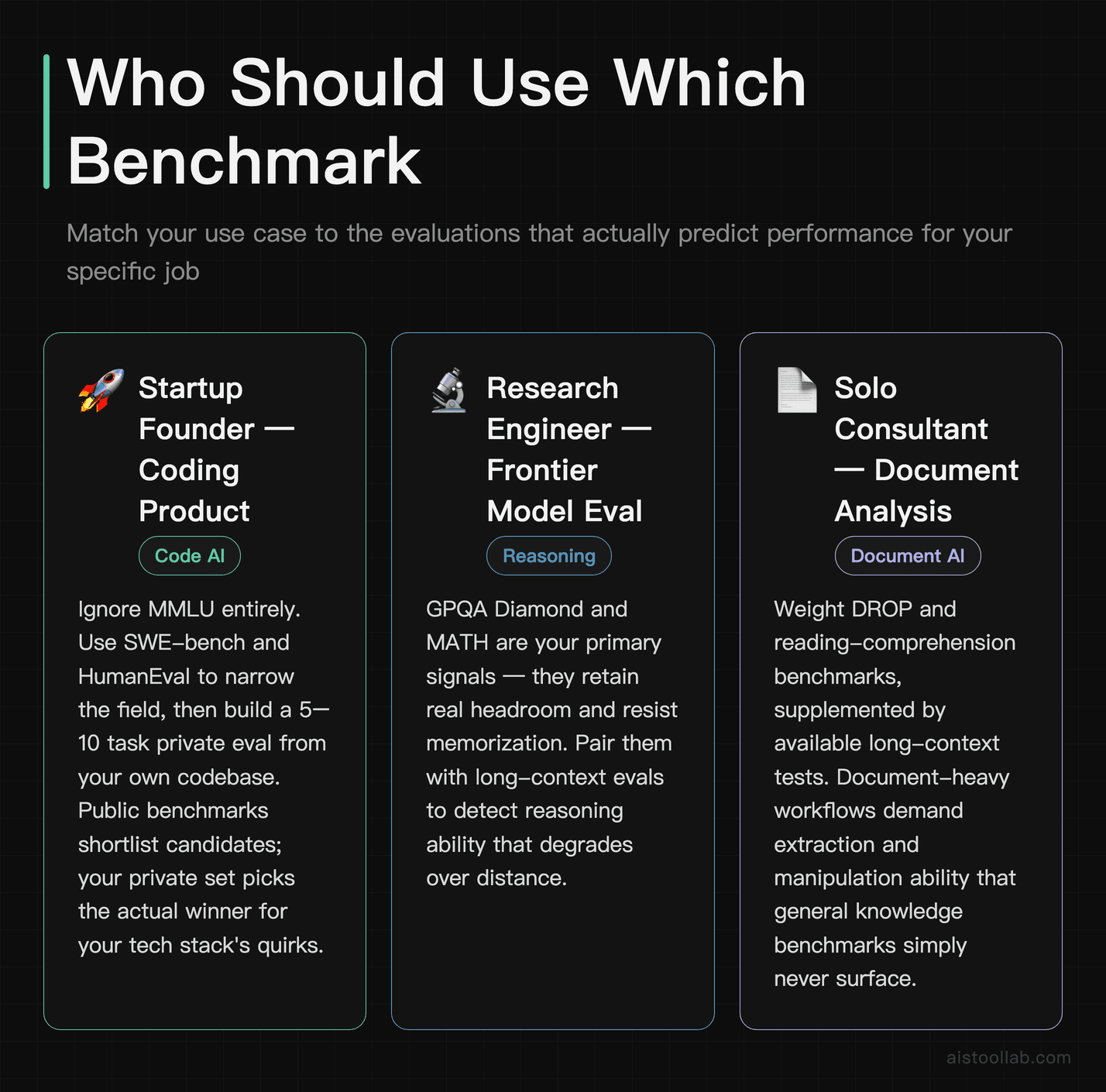
The startup founder evaluating models for a coding product
If you’re a two-person SaaS team picking the LLM that’ll power your code-assist feature, ignore MMLU entirely and live in SWE-bench and HumanEval. Better yet, build a small private eval from your own codebase — five or ten representative tasks — and run candidate models against it. The public coding benchmarks narrow the field; your private set picks the winner. Public numbers can’t see your tech stack’s quirks, and that’s where models actually diverge.
The research engineer comparing frontier reasoning models
For someone benchmarking the latest reasoning-class models against each other, GPQA Diamond and MATH are your bread and butter, because they still have headroom and resist memorization. A researcher tracking genuine capability gains over time wants benchmarks that aren’t saturated — otherwise every model looks identical. Pair these with long-context evals to catch reasoning that degrades over distance.
The solo consultant building a document-analysis workflow
A freelancer building a contract-review or report-summarization tool should weight DROP and reading-comprehension benchmarks, plus whatever long-context tests exist for the models in question. General knowledge scores barely matter here — what matters is whether the model can pull “the termination clause requires 60 days notice” out of a 30-page PDF without hallucinating. That’s a narrow, testable capability, and broad benchmarks will actively mislead you.
Frequently Asked Questions
Why do AI companies keep introducing new benchmarks?
Because the old ones keep getting solved. This is actually a sign of progress, not just marketing. When a benchmark like the original MMLU or HellaSwag gets saturated — meaning frontier models all score so high that the test can no longer tell them apart — it loses its ability to measure anything useful. The field responds by building harder benchmarks (MMLU-Pro instead of MMLU, GPQA instead of older science Q&A) that restore discrimination between models. There’s also a less flattering reason: a lab that builds and publicizes a benchmark where its own model happens to excel gets a convenient marketing narrative. That’s why I always look at who created a benchmark and whether independent third parties have adopted it. A benchmark that only one company reports is far less trustworthy than one cited across competing labs, academic papers, and neutral leaderboards. The healthy churn of new benchmarks is real, but so is the incentive to game the framing, and you have to read both at once.
What does “benchmark contamination” actually mean?
Contamination happens when the benchmark’s test questions — or very similar ones — end up in a model’s training data. When that happens, the model isn’t reasoning through the problem; it’s essentially recalling an answer it’s seen before, which inflates the score without reflecting real capability. It’s a massive problem for older, widely published benchmarks because their questions have been scraped, reposted, and discussed across the internet for years, making them nearly impossible to keep out of training sets. This is exactly why GPQA’s “Google-proof” design and newer held-out test sets matter so much — they’re built to resist this. As a practical reader, the takeaway is to be skeptical of suspiciously high scores on old benchmarks and to weight newer, contamination-resistant tests more heavily. Some labs now run “canary” checks and report decontaminated results, which is a good sign of methodological honesty. When a model crushes a legacy benchmark but underperforms on fresh, private evaluations, contamination is usually a prime suspect.
Is a higher benchmark score always better for my use case?
No, and this trips up a lot of people. Benchmark scores measure specific, narrow capabilities, and a model that tops one leaderboard can underperform on the exact task you care about. A model with a phenomenal MATH score might write clumsy marketing copy; one that aces coding benchmarks might be mediocre at summarizing legal documents. The relevance of a benchmark depends entirely on how closely it resembles your actual workload. The single best thing you can do is build a small private evaluation set — even ten representative examples from your real work — and test candidate models against it directly. Public benchmarks are useful for narrowing the field and eliminating obviously weak options, but they should never be the final word. I’ve seen teams pick a model purely on a leaderboard ranking and then discover it was the wrong choice for their specific needs. Treat benchmarks as a filter, not a verdict, and always validate against your own use case before committing.
Why is HellaSwag still mentioned if it’s saturated?
Mostly inertia and continuity. HellaSwag remains in many standard evaluation suites because keeping it lets researchers compare new models against years of historical results on the same scale. It also still functions as a basic sanity check — if a brand-new model somehow fails a commonsense benchmark that everything else aces, that’s a red flag worth investigating. But as a tool for distinguishing between today’s frontier models, it’s essentially useless, because they all score near the ceiling. The gaps that remain are often noise or arguably flawed questions rather than meaningful capability differences. I’d encourage readers to mentally discount any model comparison that leans heavily on HellaSwag, ARC, or even original MMLU as evidence of superiority. Those benchmarks tell you a model isn’t broken; they don’t tell you it’s good. The interesting action in 2026 is all happening on the harder, less-saturated tests, and a launch post that emphasizes the easy ones may be hiding weaker results on the hard ones.
What’s the difference between MMLU and MMLU-Pro?
MMLU-Pro is a deliberately harder, more reasoning-focused revision of the original MMLU. The original MMLU tests broad knowledge across 57 subjects using four-option multiple-choice questions, and frontier models climbed so high on it that it stopped distinguishing between strong and exceptional models. MMLU-Pro addresses this in a few ways: it adds more challenging questions, expands the number of answer options (which reduces the chance of scoring well through lucky guessing), and shifts the emphasis toward problems that require reasoning rather than pure recall. The practical effect is that the spread between models widens again, restoring the benchmark’s ability to discriminate. In 2026, MMLU-Pro has largely replaced the original as the go-to general-knowledge benchmark on serious leaderboards, though the original still appears for historical comparison. If you see a model reporting a strong MMLU score but staying quiet about MMLU-Pro, that’s worth a raised eyebrow — it may be leaning on the easier, more saturated version where everyone looks good.
Are coding benchmarks like SWE-bench reliable for comparing models?
They’re among the most relevant benchmarks we have, but “reliable for direct comparison” needs a caveat. SWE-bench measures something genuinely useful — whether a model can resolve real GitHub issues by producing patches that pass actual test suites — which maps far better onto real developer workflows than toy benchmarks like HumanEval. The complication is that SWE-bench results depend heavily on the agent scaffolding wrapped around the model: the retrieval, the tool use, the number of attempts allowed. Two labs reporting different SWE-bench numbers might be using different harnesses, so the comparison isn’t purely model-versus-model. When you read a SWE-bench score, check what configuration produced it. Despite that wrinkle, the benchmark’s real-world fidelity makes it one of the best signals available for coding capability. For a buying decision, I’d combine the public SWE-bench number with a hands-on trial on your own repository — that combination beats either source alone, and it’ll surface integration quirks that no leaderboard captures.
Which benchmarks matter most for evaluating reasoning ability?
For reasoning specifically, GPQA Diamond and MATH are the strongest signals in 2026, with competition-level math and graduate-level science questions that resist memorization and still have meaningful headroom. These reward genuine multi-step problem-solving rather than retrieval, which is exactly what you want when assessing reasoning. They’ve also tracked closely with the rise of explicit chain-of-thought and reasoning-model architectures, so improvements on them tend to reflect real capability gains. That said, no single benchmark captures “reasoning” fully — math and science reasoning don’t perfectly predict, say, strategic or commonsense reasoning in ambiguous real-world situations. I’d recommend looking at a cluster of hard, unsaturated benchmarks together and watching for consistency. A model that’s strong across GPQA, MATH, and challenging coding tasks is demonstrating broad reasoning competence; one that spikes on a single benchmark might just be tuned for it. Combine these with long-context evaluations, since reasoning that holds up over short prompts sometimes collapses over long documents, and that gap matters enormously in practice.
Should I trust public leaderboards or run my own tests?
Both, in that order. Public leaderboards are excellent for the first pass — they let you quickly eliminate clearly weak models and see roughly where the field stands, and they’re far cheaper than running everything yourself. But they can’t account for your specific use case, your prompts, your data, or your integration constraints, and they’re vulnerable to the contamination and framing issues we’ve discussed. The gold standard is to use leaderboards to build a shortlist of two or three candidates, then run those against a small private evaluation set drawn from your actual work. Even ten well-chosen real examples will tell you more about practical fit than any public ranking. I do this for every serious model decision, and it routinely changes my mind — the leaderboard leader isn’t always the best fit for the specific task. If you want a structured walkthrough of building that kind of evaluation, my Open LLM Leaderboard Review 2026 piece covers the methodology in more detail. Trust public numbers to narrow, trust your own tests to decide.
My Take: Stop Worshipping the Headline Number

If it were my money and my product on the line, here’s how I’d actually use this ranking. I’d treat GPQA, SWE-bench, and MATH as my “is this model genuinely capable” tier — the benchmarks that still have signal and resist gaming. I’d use MMLU-Pro as a quick generalist screen. And I’d politely ignore anyone trying to sell me on a model’s HellaSwag or original-MMLU dominance, because those numbers stopped meaning anything a while ago.
The deeper lesson from a decade of watching this space: benchmarks are a map, not the territory. The single most valuable evaluation you can run is your own — ten real tasks from your actual workflow, scored by you. Public benchmarks tell you which models deserve a spot on the shortlist. Your own tests tell you which one to actually pay for. Do both, in that order, and you’ll dodge the marketing theater that trips up everyone who just reads the launch-day headline.
Next step: pick the two benchmarks that match your real use case from the table above, find a leaderboard that reports them honestly, and then spend twenty minutes testing your top two candidates on a task you actually do. You’ll learn more in that twenty minutes than in any number of press releases.
Last updated: 2026
Found this review helpful?
👉 Browse the AI Tools Library to find the right tools for your workflow.