The Research Rabbit Hole That Started This Comparison
Here’s a scenario that plays out in newsrooms, grad-school libraries, and Slack threads every week: someone asks an AI assistant to pull together background on a complicated topic — say, gene-editing regulation — and the answer comes back polished, confident, and footnoted. Then they go to verify a citation and discover the journal is real but the paper isn’t. The whole draft is already submitted. You can imagine how that conversation with an editor goes.
That’s not a freak accident. Anyone who’s leaned on AI for serious research has run into one of three recurring problems: the hallucination problem (made-up sources), the stale-data problem (confidently outdated facts), or the “this sounds authoritative but where did it come from?” problem. The interesting question isn’t whether AI can help with research — it obviously can — but which tool is actually engineered for it, and which one is mostly improvising.
This breakdown compares Perplexity AI and ChatGPT ↗ specifically for deep research work, compiled from official documentation, the two companies’ pricing pages, and public reviews on G2, Capterra, Reddit, and named third-party comparisons (Zapier, nexos.ai, and 2026 tech-insider roundups). It’s an evidence review, not a personal lab report — but the verdict at the end is direct, because “it depends” without specifics helps nobody.
Quick Background: What Each Tool Is Actually Built For
Before any side-by-side, it helps to be clear-eyed about what each product fundamentally is, because the architecture explains almost every difference that follows.
Perplexity AI was designed from day one as an answer engine. Its whole pitch is retrieve-then-generate: it searches a live web index (the company describes it as covering tens of billions of pages), reads the relevant sources, and synthesizes an answer with inline citations attached to nearly every claim. Think of it as a smarter, chattier layer on top of search that actually reads the pages before reporting back. According to Perplexity’s own documentation, a single Pro subscription routes your queries across multiple frontier models — OpenAI’s GPT-5, Anthropic’s Claude 4.5 Sonnet and Opus, Google’s Gemini 3 Pro, and Meta-based Sonar models — plus experimental options through Perplexity Labs.
ChatGPT started life as a general-purpose conversational model and grew outward. OpenAI has layered on web browsing, file uploads, memory, code execution, and image generation over time, but the core remains a language model that can search the web rather than one that does by default. As of June 2026, OpenAI’s lineup runs GPT-5.5 as the flagship, with GPT-5.3 as the default for Plus and free users, GPT-5.4 available on Plus, and GPT-5 mini / nano for cheap, fast tasks. If you’ve read older comparisons citing GPT-4o, that’s outdated — the GPT-5 family is current. The practical upshot: ChatGPT still feels like a language model doing research, whereas Perplexity feels like a research tool using a language model. That distinction matters more than the spec sheet suggests.
The Side-by-Side: Perplexity Pro vs ChatGPT Plus
Both flagships sit at the same price — $20/month — so this isn’t a budget decision. It’s a fit decision. Here’s how the two stack up across the dimensions that matter for research work, compiled from official docs and reviewer consensus.

Two things jump out from the table. First, Perplexity quietly gives you model flexibility ChatGPT Plus doesn’t — one $20 subscription that lets you bounce between GPT-5, Claude 4.5 Opus, and Gemini 3 Pro depending on the task. For power users who like matching the model to the job, that’s a genuine perk. Second, ChatGPT’s $20 Plus tier sits inside a much wider ladder: Free, Go ($8), Plus ($20), and two separate tiers both officially named “Pro” at $100 (added April 2026) and $200. Yes, two tiers share the “Pro” name — OpenAI’s, not mine — so when you shop, check the price, not the label.
Source Citation Accuracy: Who Actually Links to Real Things?
This is the single biggest deciding factor for anyone doing research professionally, and reviewer consensus is unusually consistent here. Public comparisons across G2, Zapier, and 2026 tech-insider roundups repeatedly land in the same place: Perplexity edges out ChatGPT on real-time factual sourcing, and the reason is structural rather than incidental.
Because Perplexity retrieves first and generates second, its answers are anchored to live sources it actually pulled, with the URL shown inline as you read. You can spot-check a claim without breaking your flow — click the little citation marker, land on the source, confirm. Reviewers note it tends to cite fewer fabricated or nonexistent sources precisely because the architecture doesn’t let the model freewheel from training data when the search comes up short. (I’m deliberately not quoting an accuracy percentage here — the specific figures floating around online trace back to non-authoritative blogs and can’t be verified. The reliable signal is the direction, not a number.)
ChatGPT with browsing enabled has improved markedly over the base model — that’s well documented — but reviewers describe it as more variable. The model can still blend retrieved content with training-data recall, which occasionally produces a real source that doesn’t quite support the specific claim, a vague attribution (“according to Reuters”) with no article link, or, less often, a plausible-but-nonexistent reference. The fabrication risk drops sharply with browsing on, but for work where every citation has to survive a fact-check, that residual variability is the problem.
The takeaway that shows up again and again in reviews: if verifiable sourcing is your non-negotiable, Perplexity’s retrieve-then-generate design is more transparent by construction — every claim traces back to a source you can open. ChatGPT browses as an add-on; Perplexity searches as its reason for existing.
Real-Time Information: Freshness Under Pressure
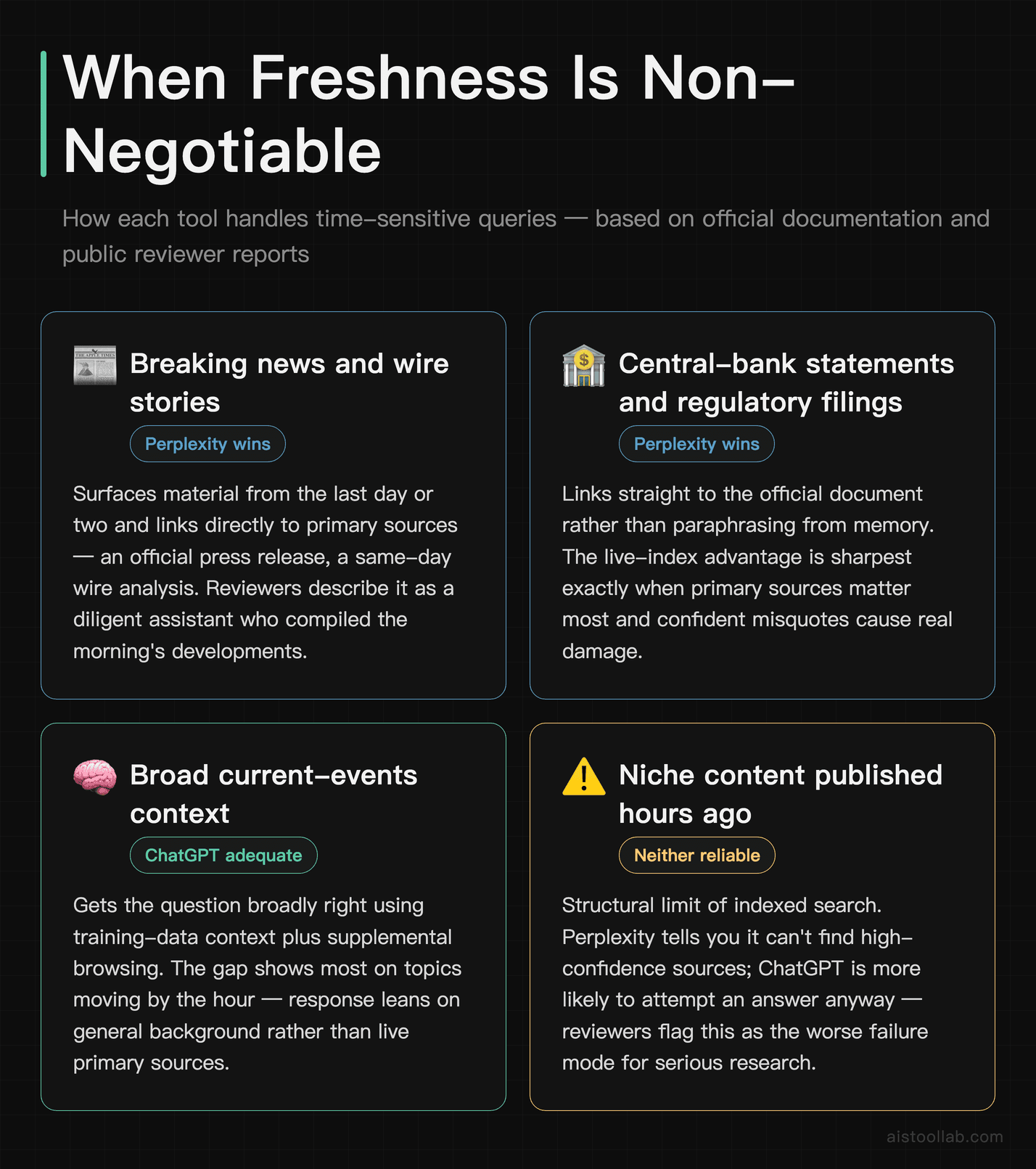
For time-sensitive queries — central-bank statements, regulatory announcements, fast-moving market or geopolitical developments — the live-index advantage is where Perplexity earns its reputation. Its documentation describes continuous indexing, and reviewers consistently report that it surfaces material from the last day or two and links straight to primary sources (an official press release, a same-day wire analysis). The experience reads like a diligent assistant who actually went and compiled the morning’s developments.
ChatGPT with browsing can get the same questions broadly right, but reviewers note the response often leans on general context (presumably training data) with the live search supplementing rather than leading. On a topic that’s moving by the hour, that lag is exactly when freshness matters most.
There’s a genuine edge case worth flagging for both tools: content that’s too recent for any good indexed source — a niche filing published the same morning. Neither handles that well. The meaningful behavioral difference reviewers highlight is how each fails. Perplexity is more likely to tell you it can’t find high-confidence sources; ChatGPT is more likely to attempt an answer anyway, which is arguably the worse failure mode for research. If you’re a news researcher, financial analyst, or policy tracker, the freshness gap is hard to overstate — Perplexity is genuinely built for the live cycle.
Long-Form Synthesis: The Academic Deep-Dive Test
Here’s where the dynamic flips. For a meaty synthesis prompt — say, “Provide a detailed literature review on the cognitive effects of social media use in adolescents, covering major theoretical frameworks, conflicting findings, and current methodological debates” — reviewer consensus tilts the other way.
Public reviews describe Perplexity’s output on these tasks as useful, well-cited, and grounded in real sources, but somewhat fragmented. Because it’s retrieval-first, it tends to stitch together summaries of individual sources rather than building a cohesive intellectual narrative — competent in pieces, but light on the through-line reasoning that makes a literature review genuinely valuable.
ChatGPT, running the GPT-5 family, is the reviewer favorite for this kind of work. The synthesis tends to be richer: it identifies real tensions between studies, draws connections across frameworks that aren’t spelled out in any single source, and structures the response like someone who actually understands the field. The trade-off is the one you’d expect — better thinking, less reliable sourcing. So the rule of thumb that emerges from the evidence is clean: Perplexity gives you better sourcing, ChatGPT gives you better thinking. For a first-pass survey you’ll verify anyway, Perplexity is safer. For building intuition about a complex field, ChatGPT’s reasoning still leads. The same reasoning-versus-retrieval pattern shows up across model comparisons — I dig into the deep-reasoning side of it in the Claude 4 Opus review, where synthesis ability matters as much as factual recall.
Ambiguous and Niche Queries: Where Each One Breaks
This is closer to a genuine split, for opposite reasons. On deliberately ambiguous queries (“What is the current state of longevity research?” — broad enough to go a dozen directions), reviewers note ChatGPT handles the disambiguation more naturally. It tends to clarify its interpretation in the opening line and offer to approach the question differently. That conversational flexibility is a real advantage for exploratory research where you’re not yet sure what you’re looking for. Perplexity is more likely to pick the most probable reading and run, occasionally tacking on a “did you mean X or Y?” at the end.
On genuinely niche queries — obscure procedural law, specialized regulatory filings, narrow academic subfields — the dynamic reverses. Perplexity’s search-first approach can surface real documents (court opinions, filings, hard-to-find papers) that a language model simply won’t reproduce accurately from training data. Reviewers consistently point to this as a Perplexity strength: it links you to the actual primary source rather than a confident paraphrase.
Both tools struggle most when a query is simultaneously niche and dependent on very recent developments — think specialized legal or medical questions from the last few weeks. Perplexity stumbles because good indexed content may not exist yet; ChatGPT stumbles because the recency isn’t in training data. At that point the realistic answer is a human expert, or at minimum Perplexity paired with your own uploaded documents.
Who Should Use Which Tool
Skipping the “it depends” non-answer — here’s exactly what it depends on, mapped to real people doing real work.
The investigative journalist or fact-checker
If you’re a reporter or fact-checker where a fabricated source could end a story (or a career), Perplexity Pro is the clearer pick. The inline, clickable citations let you verify as you read, and the retrieve-then-generate design means fewer phantom references in the first place. For someone burned once by AI hallucinations in print, that structural reliability is worth more than slick prose.
The financial or policy analyst tracking live developments
Market researchers, compliance professionals, and policy trackers live and die by freshness and primary sources. Perplexity’s live index and its habit of linking straight to the official document (a Fed release, an EU filing) fit this workflow far better than browsing-as-an-afterthought. The model flexibility helps too — route a sourcing query through Sonar, then a reasoning pass through Claude 4.5, all in one subscription.
The grad student or content strategist building understanding
If your goal is to understand a field rather than just verify facts — drafting a literature review, building a mental model, synthesizing competing theories into long-form work — ChatGPT Plus’s GPT-5 reasoning is the reviewer-preferred engine. Just treat its citations as leads to verify, not gospel. This is also the better all-rounder if your research is tangled up with coding, drafting, and data work in the same session. The ChatGPT Plus vs Claude Pro comparison digs deeper into where each subscription’s reasoning strengths land.
The power-user move: use both
The pattern that shows up repeatedly in Reddit and reviewer workflows is sequencing the two tools. Start in Perplexity to gather sourced, current, verifiable material — your factual foundation. Then move that material into ChatGPT for synthesis, reframing, and analytical heavy lifting. It’s a research librarian and a subject-matter expert in one pipeline, each used where it’s strongest. At $20 each, running both is still less than a single mid-tier seat of most enterprise software.
Frequently Asked Questions
Does Perplexity AI actually access the live web, or use cached data?
According to Perplexity’s official documentation, it indexes the web continuously and retrieves content in near real-time when you submit a query — it isn’t pulling from a frozen training snapshot the way a standalone language model does. That’s the core of its retrieve-then-generate architecture: search live sources first, then synthesize. The practical caveat is that how recently any given page was crawled varies, and content that’s only a few hours old may not be indexed yet. For most research purposes, reviewers describe “within the last day or two” as a reasonable freshness expectation for current events. If you need something published in the past hour, neither tool is fully reliable — that’s a structural limit of indexed search, not a Perplexity-specific flaw. The advantage over ChatGPT here is consistency: because retrieval is the default rather than an optional browsing step, you get live grounding on essentially every query rather than only when the model decides to search.
Can ChatGPT replace Perplexity for research with browsing enabled?
Partially, but reviewer consensus says not fully. ChatGPT with browsing turned on is dramatically better than the base model for current information, and the GPT-5 family handles browsed content more capably than GPT-4o did. The catch is architectural: even with browsing active, ChatGPT can blend retrieved material with training-data recall, which occasionally yields a confident-sounding citation that doesn’t hold up. Public comparisons consistently report it citing fewer reliable inline sources than Perplexity, and the citations it does provide are more variable in quality. If source accuracy is your primary concern — anything you’ll publish, submit, or stake a decision on — Perplexity’s retrieve-then-generate design is more trustworthy by construction. Where ChatGPT pulls ahead is reasoning depth and versatility: if your research is one input among coding, drafting, and analysis, ChatGPT’s broader toolkit may matter more than its citation gap. The candid answer is that they’re optimized for different halves of the research job.
Is Perplexity Pro worth $20/month for a student?
For many students, the free tier of Perplexity already covers the core value — it includes real-time search with inline citations, which is the main reason to use the tool at all. Pro becomes worth the $20 if you’re doing intensive daily research and need higher usage limits, access to the multiple underlying models (GPT-5, Claude 4.5, Gemini 3 Pro), the Academic search mode, and document upload for analyzing your own PDFs. A reasonable approach is to run the free tier first and only upgrade when you hit limits or specifically need the academic database mode. Worth remembering, though: AI is best used to accelerate research you actually engage with, not to replace the thinking. There’s a good argument — explored in 學生用 AI 提升學習效率 — that over-relying on AI for sourcing can quietly erode the verification skills that make a good researcher. Use it to find and triage sources faster, then read the originals yourself.
Which tool handles scientific and medical research better?
For finding real, peer-reviewed papers, Perplexity has a structural edge. Its Academic search mode (available on Pro) specifically indexes scholarly databases including PubMed and arXiv, and reviewers report it outperforms ChatGPT’s browsing for surfacing genuine, citable literature rather than plausible-sounding paraphrases. If your task is “find me the actual studies on X,” that mode is the better starting point. ChatGPT’s advantage in this domain is the flip side: explaining and synthesizing scientific concepts. Once you’ve found a paper, the GPT-5 family is excellent at unpacking the methodology, clarifying statistical approaches, and connecting findings to the broader field. The most reliable workflow that emerges from reviews is to source in Perplexity’s academic mode, then bring the actual papers into ChatGPT for interpretation — never trust either tool’s unverified summary of a study’s findings for anything clinical or high-stakes. Always open the original before citing it.
Do these tools support research in languages other than English?
Both do, with caveats. ChatGPT’s multilingual performance is strong across most major languages for reasoning and synthesis, and the GPT-5 models handle non-English drafting and analysis well. Perplexity’s real-time search also works across languages, but the quality of results depends heavily on how well-covered a topic is in non-English web content — the index can only retrieve what exists and has been crawled. For East Asian language research in particular, reviewers note results can be more variable, since indexed coverage of Chinese, Japanese, and Korean sources is thinner than English for many specialized topics. A practical tactic: for synthesis and explanation in another language, ChatGPT tends to be the smoother experience; for sourcing local-language primary documents, Perplexity can surface them but you may need to verify coverage manually. If your research is deeply tied to non-English regional media, expect to do more cross-checking with both tools than you would for English-language topics.
What about using Claude for research instead?
Anthropic’s Claude — particularly the Claude 4.5 Sonnet and Opus models — is widely praised by reviewers for long-form synthesis and reasoning, often rated competitive with or ahead of GPT-5 on certain analytical tasks. The limitation for research is real-time access: Claude doesn’t have the built-in live web search that Perplexity treats as its core function or that ChatGPT offers through browsing. That makes Claude a strong choice for document-based research — where you upload the source materials yourself and ask it to reason over them — but weaker for current-events work or anything requiring fresh, cited web sources. Interestingly, you don’t have to choose: Perplexity Pro routes queries through Claude 4.5 among its model options, so you can get Claude’s reasoning with Perplexity’s live retrieval in one place. For deeper coverage of Claude’s standalone strengths, the Claude 4 Opus review goes into its reasoning and writing capabilities in detail.
Are the free tiers good enough to skip paying entirely?
For casual research — a handful of queries a day with no professional stakes — the free tiers are surprisingly capable, and reviewers generally agree you should test them before paying. Perplexity’s free tier includes real-time search with citations, which is already its main value proposition; you mainly lose higher limits, the multi-model selector, Academic mode, and heavier document analysis. ChatGPT’s free tier provides GPT-5.3 with usage caps and more limited tool access. The candid line from reviewer consensus: if you research occasionally, the free versions may genuinely be enough, and there’s no shame in running both free tiers side by side as a built-in cross-check. You’d upgrade when you start hitting limits mid-task, need consistent access to the strongest models, or require document upload and academic search. At $20 each, the paid tiers earn their keep for daily researchers — but proving that to yourself with the free versions first costs nothing and takes about twenty minutes.
How do I avoid getting burned by fabricated citations from either tool?
Treat every citation as a lead, not a fact — that’s the consistent advice across reviewer write-ups and the lesson behind countless cautionary Reddit threads. Concretely: before you cite anything, independently verify the journal name, author, and publication date, and open the original source rather than trusting the AI’s summary of it. For high-stakes work, this verification step is non-negotiable regardless of which tool produced the answer. A useful built-in fact-check is running the same query through both Perplexity and ChatGPT — if they contradict each other on a specific claim, that’s your signal to dig deeper before relying on either. It also helps to keep a lightweight audit trail: save your exact prompt, the date, and which tool answered, so you can retrace where a finding came from later. Perplexity’s inline URLs make spot-checking faster, but “faster to verify” is not the same as “safe to skip verifying.” The fabrication risk is lower with retrieval-grounded tools, never zero.
The Bottom Line


Compiling official documentation, both companies’ pricing pages, and a stack of public reviews and third-party comparisons, the verdict lands cleanly: Perplexity is the better research tool; ChatGPT is the better thinking tool. For research specifically, those are different jobs, and the architecture is why.
If you’re producing anything where a fabricated source would be a genuine problem — reports, published stories, compliance work, anything with your name on the line — Perplexity Pro is the right call at $20/month. Its retrieve-then-generate design is structurally more transparent than a language model that browses as an afterthought, and reviewers consistently rate it stronger on real-time factual sourcing for exactly that reason.
If you’re using AI to help you think — building mental models, synthesizing dense literature, drafting analytical work where you’ll do the verifying yourself — ChatGPT Plus’s GPT-5 reasoning still has an edge Perplexity’s search-first design doesn’t fully match. And since both flagships cost the same $20, the smartest move for serious researchers isn’t picking a side at all — it’s sourcing in Perplexity, synthesizing in ChatGPT, and verifying everything regardless. But forced to choose one, with verifiable sources as the priority? Perplexity wins, and not by a little.
Last updated: 2026