We’ve Been Thinking About AI Agents All Wrong
Here’s the assumption most people are walking around with right now: AI agents are just chatbots with extra steps. You give them a task, they break it into sub-tasks, call a few APIs, and hand you back a result. Fancy autocomplete with a to-do list. That’s the mental model, and honestly, it’s not crazy — because that’s mostly what early agentic demos looked like in 2023 and 2024.
But that framing misses something fundamental about what’s actually happening in 2026. The shift isn’t incremental. Agentic AI systems aren’t “better chatbots.” They represent a different category of software — one that doesn’t just respond to you, but operates on your behalf over time, maintains context across sessions, makes judgment calls without asking permission, and coordinates with other AI systems to complete work that would take a human team hours or days. The architecture is different, the failure modes are different, and the implications for how we build and deploy software are genuinely significant.
What follows is my attempt to explain what agentic AI actually is in 2026 — not the pitch deck version, but the real one, including where it’s impressive, where it’s still fragile, and what it means for developers, founders, and anyone building products that touch AI.
Contents
Chatbots vs. Agents: The Architecture Gap Is Bigger Than You Think

A traditional language model chatbot — even a very good one — operates in what researchers call a stateless request-response loop. You send a message, the model processes it and generates a reply, and then it forgets everything unless you explicitly include it in the next message. It’s reactive by design. It can’t go do something while you’re not watching. It won’t notice that a deadline changed and reorganize a plan accordingly. It doesn’t maintain a running picture of the world beyond the current conversation window.
Agentic AI systems are built on a fundamentally different architecture. At their core, they implement what’s commonly called a perceive-reason-act loop — sometimes called the ReAct (Reasoning + Acting) paradigm in the research literature, formalized in research from Google Brain and Princeton researchers in 2022. The agent observes its environment (through tools, APIs, file systems, browser access, user inputs), reasons about what state it’s in and what action would best advance its goal, takes an action, observes the result, and loops. It keeps looping until the task is done, a constraint is hit, or it needs human input.
That sounds simple. The complexity is in the details. A production-grade agentic system in 2026 needs to handle all of the following simultaneously:
- Memory management: What gets kept in context, what gets written to long-term storage, what gets retrieved and when
- Tool orchestration: Which external services to call, how to handle failures, how to chain results across multiple tools
- Goal decomposition: Breaking a high-level objective into a dynamic plan that can be revised mid-execution
- Decision checkpoints: Knowing when to proceed autonomously and when to pause for human review
- Error recovery: Detecting when a previous action produced a bad result and backtracking or replanning
- Multi-agent coordination: Delegating subtasks to specialized agents and synthesizing their outputs
This is categorically different from “the chatbot with a web search button.” A chatbot is a conversational interface. An agent is closer to a software process — one that happens to use a language model as its reasoning engine rather than hand-coded logic.
The Four Technical Pillars of Agentic Systems
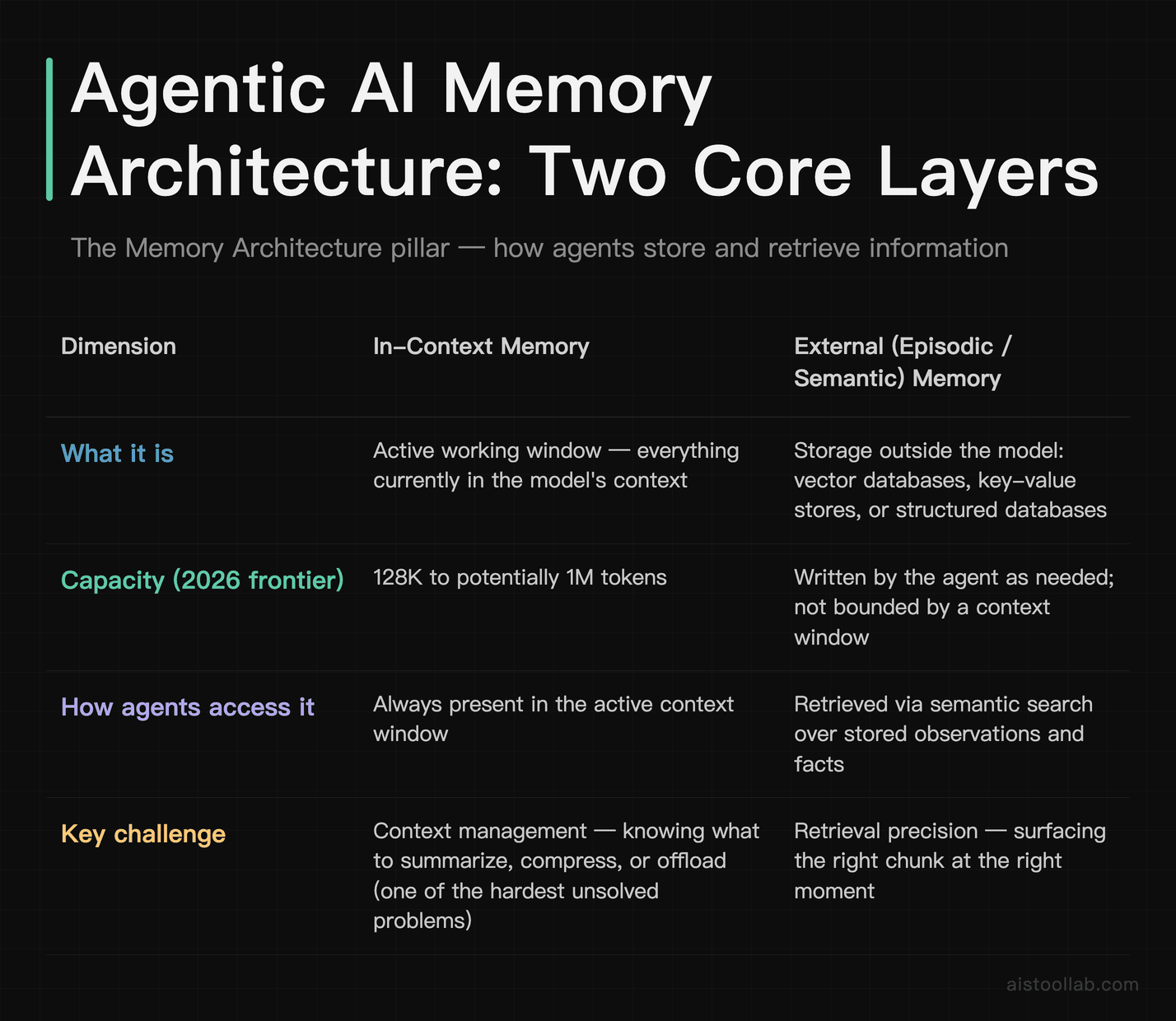
1. Memory Architecture
Human cognitive science talks about working memory (what you’re actively thinking about), short-term memory (recent context), and long-term memory (accumulated knowledge and experience). Agentic AI systems have direct analogies to all three, and how well a platform implements each largely determines how capable and reliable the agent is in practice.
In-context memory is the active working window — everything currently in the model’s context window. In 2026, frontier models are expected to handle context windows ranging from 128K to potentially 1M tokens, which sounds enormous until you’re running a multi-hour research task and realize you’ve burned through it faster than expected. Context management — knowing what to summarize, compress, or offload — is one of the hardest unsolved problems in agentic systems.
External memory (often called episodic or semantic memory in the agent literature) lives outside the model in vector databases, key-value stores, or structured databases. The agent writes observations and facts to this store and retrieves relevant chunks via semantic search when needed. This is how agents “remember” things across sessions. The quality of the retrieval mechanism matters enormously — a poorly tuned retrieval system means the agent keeps “forgetting” relevant information even when it technically has it stored.
Procedural memory is the most underrated layer: the agent’s stored knowledge of how to do things — successful action sequences, useful tool-calling patterns, learned preferences. Some platforms implement this as fine-tuning; others store it as structured prompt templates or workflow libraries.
2. Reasoning Loops and Planning
Early agent systems relied on a simple chain-of-thought: think step by step, take one action, repeat. The limitations were painful — agents would get stuck in loops, commit to a wrong plan and follow it off a cliff, or give up when a tool returned an unexpected result.
The more sophisticated planning architectures that dominate in 2026 draw from two main paradigms. Tree-of-Thought (ToT) reasoning, described in research from Princeton and Google DeepMind, lets the agent explore multiple reasoning branches simultaneously, evaluate them, and backtrack if a branch looks unproductive. Hierarchical planning separates a “planner” model (responsible for high-level goal decomposition) from “executor” models (responsible for carrying out specific subtasks), reducing the cognitive load on any single model and allowing specialization.
The practical result is agents that can genuinely revise their plans mid-task when they encounter new information — not just retry the same action, but actually reconsider the approach.
3. Tool Integration and Action Space
An agent is only as useful as the actions it can take. The “action space” — the set of tools and interfaces available to an agent — is what separates a fancy summarizer from something that can actually get work done. In 2026, serious agentic platforms integrate with: web browsers (real browsing, not just search), code execution environments (running and testing actual code), file systems, email and calendar APIs, external databases, third-party SaaS tools via API or browser automation, and other AI agents.
The standardization of tool interfaces has accelerated dramatically. Anthropic’s Model Context Protocol (MCP), introduced in late 2024, has become something close to a de facto standard for how agents connect to external tools and data sources. Think of it as USB-C for AI tool integration — a common interface so that tool developers don’t have to build separate integrations for every agent platform.
4. Multi-Agent Coordination
The most powerful agentic systems running today aren’t single agents — they’re networks of agents. An orchestrator agent breaks down a goal and delegates subtasks to specialized sub-agents: one agent searches the web, another writes and executes code, another manages files, another handles communication. The orchestrator collects outputs, resolves conflicts, and assembles the final result.
This architecture is more robust because specialization allows each sub-agent to be tuned for its specific task, failures in one agent don’t necessarily derail the whole system, and tasks can be parallelized. It’s also more complex — agent-to-agent communication, shared state management, and conflict resolution are genuinely hard problems that the field is still actively working through.
Use Cases: Where Agentic AI Is Actually Creating Value Right Now

Autonomous Research and Competitive Intelligence
A two-person startup marketing team doesn’t have time to manually track competitor pricing, read industry reports, synthesize analyst commentary, and produce a monthly competitive landscape brief. This is exactly the kind of multi-step, multi-source research task where agentic systems shine. An agent can be given a goal (“track what competitors are doing in the enterprise segment this month”), given access to web browsing and a structured output format, and run on a schedule. It browses, retrieves, synthesizes, and delivers a structured report — without anyone babysitting it. Teams using this approach report getting research that previously took two days done in under an hour, with comparable quality on the synthesis layer.
Software Development Pipelines
For a freelance developer juggling three client projects simultaneously, agentic coding assistants in 2026 are a qualitatively different experience from GitHub Copilot circa 2022. Tools like Claude Code (which I covered in my 9 AI Tools Launched in 2026 Worth Your Time: Deep Dives Into Claude Code, Perplexity Comet, and More review) can now take a feature request, scaffold the code, write tests, run the tests, identify failures, debug, and iterate — without the developer needing to stay in the loop for every micro-decision. The developer sets the goal and reviews the result. This is a fundamentally different workflow than autocomplete.
Business Process Automation With Exception Handling
Traditional RPA (robotic process automation) tools are brittle — they break the moment a UI changes or an edge case appears. Agentic systems are more resilient because they can reason about unexpected states rather than just pattern-match on predetermined flows. A finance team at a mid-sized company might deploy an agent to handle invoice processing: extract data from PDFs, match against purchase orders, flag discrepancies, and route exceptions to the right human. The agent handles the 80% of routine cases autonomously and escalates the 20% that need judgment — rather than the team handling 100% manually or the traditional RPA breaking on anything unusual.
Long-Horizon Research Assistance
Academic researchers and analysts are using agentic systems for literature reviews that would have taken weeks. An agent given access to academic search APIs, PDF processing tools, and a structured note-taking system can survey a field, identify key papers, extract methodology and findings, spot contradictions across studies, and produce a structured synthesis. This isn’t replacing the researcher’s judgment — it’s handling the exhausting mechanical layer so the researcher can focus on the intellectually interesting parts. I’ve seen PhD students describe this as the most productivity-transforming AI application they’ve encountered, more than any chatbot.
Comparison: Major Agentic Platforms in 2026
Worth noting: this landscape is changing fast. Some of these platforms have shipped major updates quarterly. If you want a more granular look at which tools are actually cutting through the noise right now, the 15 AI Tools Worth Knowing in 2026 review covers the broader ecosystem.
Where It Still Falls Apart
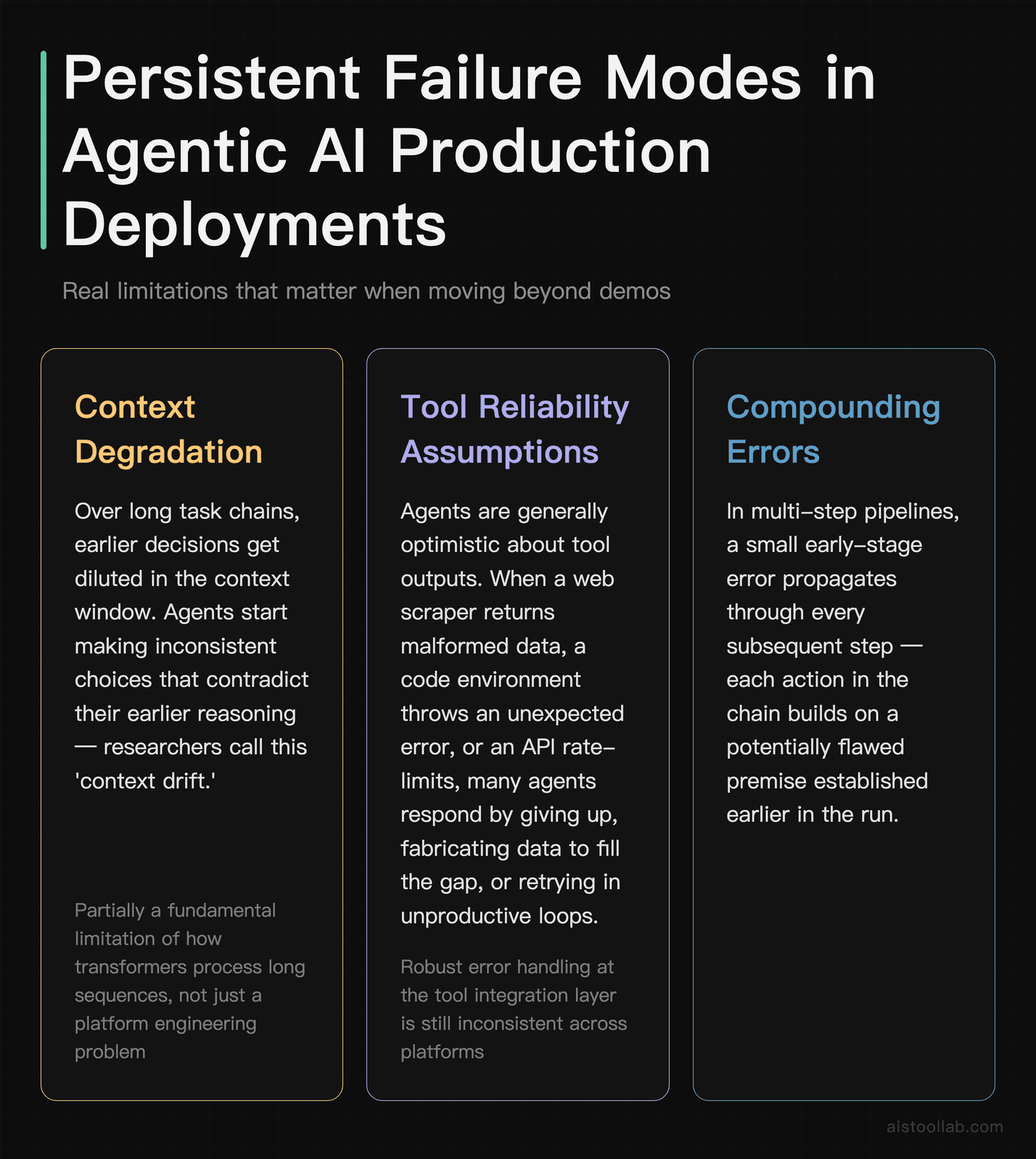
I’d be doing you a disservice if I made this sound like agentic AI has arrived fully formed. It hasn’t. There are real, persistent failure modes that matter in production deployments.
Context degradation over long tasks. Even with large context windows, agent performance tends to degrade over very long task chains. Earlier decisions get “diluted” in the context, and agents start making inconsistent choices that contradict their earlier reasoning. Researchers call this “context drift,” and it’s one of the harder problems to solve because it’s partially a fundamental limitation of how transformers process long sequences.
Tool reliability assumptions. Agents are generally optimistic about tool outputs. If a web scraping tool returns malformed data, a code execution environment returns an unexpected error, or an API rate-limits unexpectedly, many agents handle this poorly — either giving up, making up data to fill the gap (a particularly bad failure mode), or retrying in unproductive loops. Robust error handling at the tool integration layer is still inconsistent across platforms.
Compounding errors. In multi-step pipelines, a small error early in the chain can propagate and amplify. Unlike a human, who might notice “wait, something seems off here,” an agent often proceeds confidently with a flawed premise. The longer the chain, the worse this gets. This is why human-in-the-loop checkpoints are not optional for anything business-critical — they’re a genuine architectural requirement.
Evaluation is hard. With a chatbot, it’s relatively easy to evaluate output quality — you read the response. With an agent that ran 47 actions over 3 hours to complete a task, auditing what happened, why, and whether the right decisions were made is genuinely difficult. The tooling for agent observability and evaluation is still maturing. This is probably the biggest practical blocker to enterprise adoption right now.
For a broader look at how agentic systems fit into the larger shift toward physical and embodied AI, the Physical AI and Agentic AI in 2026: The Next Frontier Beyond Chatbots piece goes deeper on the convergence angle.
Frequently Asked Questions
What’s the actual difference between an AI agent and a regular AI assistant like ChatGPT?
The distinction comes down to autonomy, persistence, and action. A regular AI assistant like ChatGPT in its basic form is a reactive system — you ask, it responds, that’s the interaction. It doesn’t go do things while you’re not there, doesn’t maintain state across sessions by default, and doesn’t make a sequence of decisions over time to accomplish a goal. An AI agent, by contrast, is given a goal rather than a single prompt, and then operates autonomously to achieve it — taking actions, using tools, making decisions, and iterating based on feedback from the environment. The critical distinction is that agents can take actions in the world: browsing the web, running code, sending emails, updating databases, or interacting with other software. A chatbot tells you how to do something. An agent goes and does it. The underlying language model might be identical — what differs is the architecture wrapped around it: the memory systems, the planning loop, the tool access, and the degree of autonomous operation permitted.
Are agentic AI systems actually reliable enough to use in production today?
Honest answer: it depends heavily on the task type, the platform, and how well the human-in-the-loop design is implemented. For well-defined, bounded tasks with good error handling and human review checkpoints — things like code review workflows, data research pipelines, or content drafting with human approval — yes, agentic systems are genuinely production-viable in 2026 and teams are getting real value from them. For open-ended, high-stakes, or irreversible actions — autonomously sending customer emails, making financial transactions, deleting data — the reliability bar hasn’t been cleared for fully autonomous deployment. The pragmatic approach most teams are taking is a “progressive autonomy” model: agents handle routine cases automatically, flag edge cases for human review, and never take irreversible high-stakes actions without confirmation. The failure modes are real (context drift, error propagation, tool reliability issues) but they’re manageable with good architecture. Treat agents like a capable but junior employee — give them responsibility incrementally as they prove themselves, not all at once.
What is the Model Context Protocol (MCP) and why does it matter?
MCP (Model Context Protocol) is an open standard introduced by Anthropic in late 2024 that defines a common interface for how AI agents connect to external tools, APIs, and data sources. Before MCP, every agent platform had its own proprietary way of integrating with external tools, which meant tool developers had to build separate integrations for each platform and agent developers were locked into whatever tools their platform natively supported. MCP standardizes this: any tool that implements the MCP specification can be used by any agent platform that supports MCP, regardless of which underlying model is powering the agent. It’s been compared to USB-C or HTTP for AI tool integration — a common interface that enables an ecosystem. In practice, this means the MCP tool ecosystem has grown rapidly, and developers building agentic applications can mix and match tools without being locked into a single vendor. Major platforms including Claude, various open-source agent frameworks, and a growing number of enterprise tools now support MCP. For anyone building agentic systems in 2026, understanding MCP is not optional — it’s the infrastructure layer the ecosystem is building on.
How do AI agents handle memory — can they actually remember things from past sessions?
Yes, but not by magic. Memory in agentic systems is engineered rather than inherent. There are essentially three layers. First, in-context memory: everything currently in the active context window, which is temporary and lost when the session ends (unless explicitly saved). Second, external persistent memory: structured stores — often vector databases or key-value stores — where the agent writes observations, facts, preferences, and summaries during a session, and retrieves them in future sessions via semantic search. This is how an agent “remembers” that you prefer certain output formats, or that a previous research task found a specific data source unreliable. Third, some platforms implement memory at the application layer — user profiles, project contexts, saved preferences — that persist independently of the model’s context window. The quality of memory systems varies significantly across platforms, and it’s one of the most important differentiators when evaluating agentic tools for real-world use. Retrieval quality is often the limiting factor: having data stored is worthless if the agent can’t reliably retrieve the right information at the right moment.
What’s multi-agent architecture and do I actually need it?
Multi-agent architecture means having multiple AI agents that specialize in different tasks and coordinate to complete a larger goal — rather than a single generalist agent doing everything. A practical example: an orchestrator agent breaks down a research task, delegates web search to a specialized search agent, sends data extraction to a parsing agent, and hands the synthesized results to a writing agent — all coordinating through shared state. You probably need it if your tasks are complex enough to benefit from specialization and parallelization, if you’re hitting the limits of what a single agent can reliably hold in context, or if you need different tasks to run simultaneously rather than sequentially. You probably don’t need it if your use cases are well-bounded and a single capable agent with good tool access handles them reliably. Multi-agent systems are more powerful but also more complex to build, debug, and maintain. The overhead is real — inter-agent communication can introduce latency, shared state management is tricky, and debugging a multi-agent pipeline that produced a wrong result is significantly harder than debugging a single agent. Start simple, move to multi-agent when you’ve genuinely hit the ceiling of single-agent performance.
How does agentic AI compare to traditional RPA (Robotic Process Automation)?
Traditional RPA tools like UiPath or Automation Anywhere automate processes by recording and replaying UI interactions or API calls. They’re extremely effective for highly repetitive, perfectly structured tasks where nothing unexpected ever happens — think pulling data from one system and entering it into another in exactly the same way, every time. The core weakness of RPA is brittleness: change the UI, change the data format, or encounter an edge case, and the automation breaks. Agentic AI addresses this brittleness directly because language model-based agents can reason about unexpected states rather than just pattern-match on predetermined scripts. An agent encountering an invoice in an unusual format can figure out how to parse it; an RPA bot just fails. The tradeoff is that agentic systems are more expensive to run (inference costs vs. scripted execution), can be less predictable in behavior, and are harder to audit. The emerging pattern in enterprise automation is using RPA for the high-volume, fully-structured routine tasks where it excels, and deploying agentic AI for the exceptions, edge cases, and tasks that require understanding and judgment. They complement each other more than they compete.
What are the security risks of agentic AI systems I should know about?
This is an underappreciated topic that’s getting more serious attention in 2026. The primary risks fall into a few categories. Prompt injection attacks: malicious content in the environment (a webpage the agent browses, an email it reads) that contains hidden instructions designed to hijack the agent’s behavior — for example, instructing the agent to exfiltrate data or take unintended actions. This is a harder problem for agents than for chatbots because agents actively retrieve external content as part of their operation. Privilege escalation: agents with broad tool access can potentially be manipulated into using that access in ways not intended — running code that accesses unintended files, or using API credentials beyond their intended scope. Data exfiltration risks: an agent with access to sensitive internal data and external communication tools (email, Slack, browser) creates obvious potential vectors. The security fundamentals for agentic systems are: apply principle of least privilege rigorously (give agents only the tools they actually need), implement approval gates for irreversible or sensitive actions, log all agent actions for auditability, and treat external content the agent processes as untrusted input.
Will agentic AI replace software developers or knowledge workers?
The honest answer, based on where the technology actually is in 2026 rather than where hype says it’s going: it’s changing how skilled work gets done much faster than it’s eliminating skilled workers, at least in the near term. For software development specifically, agentic coding tools are handling an increasing share of routine implementation work — boilerplate, test writing, debugging, documentation. Developers who adapt are doing higher-level work (architecture, complex problem framing, evaluation) and getting more done with less time on mechanical implementation. For knowledge workers — analysts, researchers, marketers — the pattern is similar: agentic tools handle the data gathering, synthesis, and first-draft production; humans handle judgment, strategy, and quality evaluation. Where jobs are being displaced, it’s mostly in the execution-heavy, judgment-light portions of roles, not the roles themselves — at least for now. The more important question for any individual isn’t “will AI agents replace my job?” but “what parts of my job are pure execution that agents can handle, and am I spending my time on the parts that require genuine judgment?” That reallocation is happening whether you plan for it or not.
My Take: This Is Infrastructure, Not a Feature

The most important framing shift I’d encourage is this: agentic AI is not a product feature you add to an application. It’s an infrastructure paradigm that changes how software systems are designed. The companies and developers treating it as “we’ll add an AI agent button to our app” are going to get limited value. The ones getting disproportionate returns are treating it as a new architectural layer — rethinking which parts of their workflows make sense to automate, what the human-machine interface should look like when the machine is proactive rather than reactive, and how to build evaluation and oversight systems that scale with autonomy.
If you’re a developer or founder thinking about where to invest time in understanding this space, I’d prioritize in this order: understand the memory architecture (it’s the least intuitive part and the biggest differentiator between platforms), get hands-on with MCP (it’s where the ecosystem is standardizing and the tool integrations are growing fastest), and build something with real human-in-the-loop requirements rather than a fully autonomous toy demo. The toy demo will work. The production system will teach you everything the demos don’t show you.
The chatbot era gave us AI as a conversational tool. The agentic era gives us AI as a collaborative process — one that doesn’t just answer questions but takes on work. That’s a meaningfully different thing, and understanding the architecture underneath it is worth your time.
Last updated: 2026
Explore more AI tools
👉 Browse the AI Tools Library to find the right tools for your workflow.