The Dirty Secret About “Intelligent” AI Systems
Here’s something that should bother you more than it probably does: most AI systems — including the ones your company might be paying serious money for — are answering questions based on training data that could be anywhere from six months to two years old. Ask an AI assistant about last quarter’s earnings report, a recent court ruling, or a drug trial published last month, and you’re essentially asking someone who’s been in a coma since 2024 to give you current medical advice.
The standard fix people reach for is “just search the web.” But that’s a band-aid, not a solution. Dumping raw search results into a prompt is noisy, slow, and burns through context windows on irrelevant content. What enterprises actually need — and what the more sophisticated AI deployments in 2026 have quietly figured out — is Retrieval-Augmented Generation. RAG doesn’t just bolt a search engine onto an LLM. It creates a fundamentally different architecture where the retrieval system and the generative model work together in a way that’s more like a researcher with a well-indexed library than a student cramming from Wikipedia tabs.
I want to go deep on this today. Not the “RAG explained in 5 bullet points” version you’ve already read. The real picture — how the architecture actually works, where it genuinely outperforms alternatives, and why enterprise adoption has accelerated so dramatically in the last 18 months. If you’ve been using AI tools and wondering why some feel grounded and factual while others hallucinate confidently, RAG is usually a big part of that answer. You can also check out my earlier Retrieval-Augmented Generation (RAG) Explained: How AI Tools Actually Use Your Data Without Hallucinating piece for the fundamentals — this article goes significantly further.
Contents
What RAG Actually Is (And What It Isn’t)
The simplest honest description: RAG is an architecture pattern where an AI system retrieves relevant documents or data snippets before generating a response, then uses those retrieved chunks as grounding context. The LLM doesn’t need to “remember” everything from training — it reads the relevant material fresh for each query, like a consultant who pulls the right files before answering your question rather than winging it from memory.
What RAG is not: it’s not the same as giving an AI a web search tool. Web search returns ranked URLs and snippets optimized for human browsing. RAG retrieval is designed specifically for machine consumption — semantically dense, precisely chunked, ranked by relevance to the actual reasoning task, not by SEO signals. The difference in output quality is significant enough that organizations running both approaches tend to stick with proper RAG pipelines fairly quickly.
It’s also not fine-tuning. Fine-tuning bakes knowledge into model weights — expensive, slow to update, and prone to catastrophic forgetting when you try to update it. RAG keeps the knowledge external and updatable. You can add new documents to your vector store tonight and your AI system knows about them tomorrow morning. That’s an enormous operational advantage for any use case where the information landscape changes regularly, which is basically all of them.
The Technical Architecture: What’s Actually Happening Under the Hood

A production RAG system has several moving parts that work in sequence. Understanding each one helps you understand both the power and the failure modes.
Embedding Models: Turning Text Into Coordinates
Before you can retrieve anything, you need a way to find it. Traditional keyword search (BM25, TF-IDF) works on literal word matching — fine for exact queries, terrible for semantic meaning. If your document says “myocardial infarction” and your user asks about “heart attacks,” keyword search misses it. Embedding models solve this by converting text into high-dimensional vectors — numerical representations where semantically similar content ends up geometrically close in vector space.
The embedding model is trained to place “heart attack” and “myocardial infarction” near each other in this space, because they appear in similar contexts across training data. In practice, this means your retrieval system can find relevant content even when users phrase queries in unexpected ways — which, if you’ve ever watched real users interact with enterprise AI, is essentially all the time.
In 2026, dedicated embedding models from providers like Cohere, OpenAI, and various open-source alternatives (including models available through HuggingFace) have become more specialized. There are now domain-specific embedding models for legal text, biomedical literature, and financial documents that outperform general-purpose embeddings on those specific corpora — sometimes significantly. Picking the right embedding model for your domain is one of the most impactful architectural decisions you can make.
Vector Databases: The Index That Makes It Fast
Once your documents are embedded, you need somewhere to store millions (or billions) of vectors and query them quickly. That’s the job of a vector database. Solutions like Pinecone, Weaviate, Qdrant, Milvus, and pgvector (a PostgreSQL extension) have all matured substantially. The core operation is Approximate Nearest Neighbor (ANN) search — finding the vectors most similar to your query vector without exhaustively comparing every entry in the database.
The “approximate” part matters in practice. ANN algorithms trade a small amount of recall accuracy for enormous speed gains. Exact nearest-neighbor search at scale is computationally prohibitive; approximate search with well-tuned parameters gives you results fast enough for real-time applications with acceptable accuracy loss. The specific algorithms — HNSW (Hierarchical Navigable Small World graphs) and IVF (Inverted File Index) are common — have different trade-offs around indexing time, memory footprint, and query latency that become important when you’re operating at enterprise scale.
One underappreciated design choice: metadata filtering. Modern vector databases let you filter by metadata before or during vector search — for example, “only search documents from the last 90 days” or “only search contracts from this specific client.” This dramatically reduces the search space and improves both speed and precision, but requires thoughtful metadata schema design upfront.
Chunking Strategy: The Hidden Variable Nobody Talks About
Here’s something that doesn’t get enough attention in most RAG explainers: how you split your source documents into retrievable chunks has an enormous impact on system quality. Chunk too large, and you’re pulling in irrelevant context alongside the relevant bit, burning context window and confusing the model. Chunk too small, and you lose the surrounding context that gives individual sentences meaning.
Fixed-size character chunking (the naive approach) is almost never optimal in production. More sophisticated approaches include sentence-boundary chunking, paragraph chunking, semantic chunking (splitting when the topic meaningfully shifts), and hierarchical chunking (storing both summary and detail levels). In 2026, several frameworks have added semi-automated chunking optimization tools that test different strategies against your specific corpus — something that used to require substantial manual experimentation.
The Retrieval Pipeline: From Query to Context
The actual retrieval step is more complex than a single vector search. Production pipelines typically involve: query reformulation (expanding or rewriting the user’s query to improve recall), hybrid search (combining vector similarity with keyword search for better precision), re-ranking (using a more expensive cross-encoder model to re-score retrieved chunks), and context compression (trimming retrieved chunks to remove irrelevant sentences before they hit the LLM).
Query reformulation matters a lot. Raw user queries are often ambiguous, short, or phrased in ways that don’t match how the source documents are written. Techniques like HyDE (Hypothetical Document Embeddings — generating a hypothetical answer to your query and using that as the search query) can substantially improve retrieval relevance. Multi-query retrieval generates several differently-phrased versions of the same question and merges the results. These aren’t theoretical improvements — teams running ablation studies on their RAG pipelines consistently find that retrieval quality is the primary bottleneck in output quality.
RAG vs. Fine-Tuning vs. Prompting: A Side-by-Side Comparison

This is where a lot of the blog discourse gets sloppy, so let me be direct about what the evidence actually shows.
The honest summary: RAG wins decisively when information freshness, source traceability, and proprietary data access matter. Fine-tuning wins when you need the model to adopt a specific communication style, handle domain-specific reasoning patterns, or process documents in a specialized format efficiently. The two aren’t mutually exclusive — many mature enterprise deployments use fine-tuned models as the generation component of a RAG pipeline, getting advantages from both approaches.
Where RAG clearly underperforms: tasks where the relevant knowledge is genuinely static and well-represented in the base model’s training data, pure reasoning tasks that don’t require external facts, and latency-critical applications where the retrieval step adds unacceptable overhead. For something like code completion or creative writing, RAG adds complexity without proportionate benefit.
Real Performance: What the Evidence Actually Shows
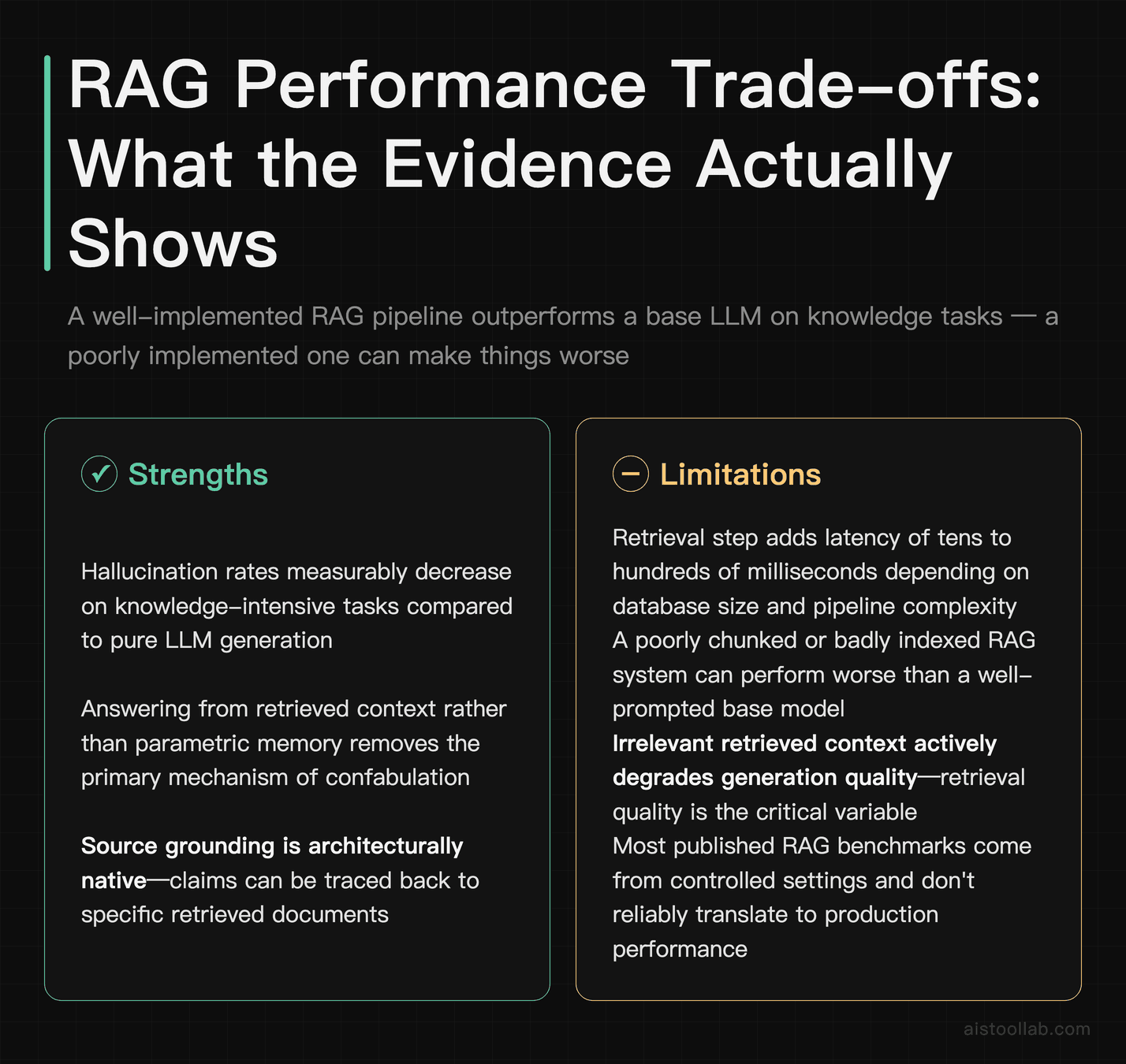
I want to be careful here about fabricating specific numbers, because a lot of RAG performance claims you’ll find online are either from controlled benchmarks that don’t translate to production, or are marketing-adjacent. What I can tell you from the literature and from what practitioners consistently report:
Hallucination rates measurably decrease with well-implemented RAG compared to pure LLM generation on knowledge-intensive tasks. The mechanism is straightforward — when the model is instructed to answer from provided context rather than from parametric memory, it has less opportunity to confabulate. The degree of improvement varies enormously by implementation quality; a poorly chunked, badly indexed RAG system can actually perform worse than a well-prompted base model, because irrelevant retrieved context actively degrades generation quality.
Latency is the real trade-off that most benchmarks underemphasize. A standard RAG retrieval step adds somewhere in the range of tens to hundreds of milliseconds depending on database size, infrastructure, and pipeline complexity. For a chatbot responding in a Slack thread, this is imperceptible. For a high-frequency financial data system, it might be disqualifying. For most enterprise knowledge assistant use cases, it’s entirely acceptable.
The research community — including work published through venues like ACL, EMNLP, and NeurIPS over the past few years — has consistently found that retrieval quality (the ability to pull the truly relevant chunks) is a stronger predictor of end-to-end system performance than generation model quality. You can get surprisingly good results with a smaller, cheaper LLM if your retrieval pipeline is excellent. This has real cost implications for enterprise deployments.
Who’s Actually Using RAG in 2026: Enterprise Use Cases

This is where the rubber meets the road. Here are four domains where RAG has moved from pilot project to core infrastructure.
Financial Analysis: Real-Time Research at Scale
Equity research teams at major banks and asset managers are using RAG-powered systems to synthesize information across earnings transcripts, SEC filings, news feeds, analyst reports, and proprietary research notes — in real time. The key value isn’t that the AI is smarter than an analyst; it’s that it can surface relevant historical context instantly. Ask a question about how a company’s current supply chain issues compare to what they disclosed in 2022 filings, and a properly indexed RAG system answers it in seconds rather than hours of manual search.
The source traceability aspect is critical in financial settings. Every claim in a generated summary needs to be traceable to a specific document and page — both for compliance reasons and because analysts need to verify before acting on information. RAG’s native citation capability makes this architecturally natural in a way that pure LLM generation fundamentally isn’t.
Medical Research: Keeping Pace With the Literature
PubMed adds a very large number of new papers daily. No human researcher can track more than a small slice of their relevant literature. Medical AI systems using RAG over indexed biomedical literature are now being used to assist with literature reviews, drug interaction checking, and treatment protocol synthesis. The embedding models here need to handle dense medical terminology, which is why domain-specific biomedical embeddings (like those trained on PubMed corpora) have become a distinct and important product category.
Importantly, medical RAG deployments in serious use cases aren’t replacing clinical judgment — they’re augmenting research workflows where the primary risk is missing a relevant paper, not generating a hallucinated drug interaction. The appropriate use case calibration matters here. This connects to broader discussions about Agentic AI in 2026: How AI Systems Are Moving Beyond Chatbots to Autonomous Agents — agentic medical research tools increasingly use RAG as their factual grounding layer.
Legal Document Review: Navigating Document Mountains
Legal teams doing due diligence on a large acquisition might review tens of thousands of documents. RAG enables AI assistants that can answer specific questions across that entire corpus — “show me all clauses relating to change of control across these 847 contracts” — in ways that simple keyword search misses and that human review would take weeks to accomplish.
The precision requirements are extremely high. A missed indemnification clause is a real-world problem. This has driven significant investment in legal-specific chunking strategies (contracts have very specific structure that generic chunking destroys), legal embedding models, and re-ranking systems trained on legal relevance judgments rather than general web content. Several enterprise legal AI companies now offer their own fine-tuned embedding models as a core competitive differentiator.
Internal Knowledge Base Automation
This is probably the most common enterprise RAG deployment in 2026: the internal knowledge assistant. Index your company’s Confluence, Notion, Google Drive, past Slack conversations, HR policies, technical documentation, and engineering runbooks. Now any employee can ask “what’s our policy on contractor data access?” or “how do I set up the staging environment?” and get an accurate, sourced answer rather than pinging a colleague or digging through stale wikis.
The ROI math here is fairly simple and tends to be compelling to enterprise buyers — reduced time spent on information retrieval, reduced load on senior engineers and HR teams for routine questions, faster onboarding. The challenge is keeping the index current and handling access permissions correctly (you don’t want an intern’s query returning executive compensation documents). Modern RAG platforms have built-in document-level access control that propagates through the retrieval layer, which has been a significant maturity milestone for enterprise adoption.
Open-Source Frameworks vs. Proprietary Solutions

If you’re building RAG, you have a meaningful choice between rolling your own pipeline with open-source frameworks and buying a managed proprietary solution. The answer genuinely depends on your team and requirements.
LangChain
LangChain is probably the most widely known RAG orchestration framework. It provides a high level of abstraction for building chains that combine retrieval steps, prompt templates, LLM calls, and output parsing. The breadth of integrations is impressive — connecting to dozens of vector databases, LLM providers, document loaders, and tool integrations. The downside that practitioners frequently cite is the abstraction overhead: debugging a complex LangChain pipeline when something goes wrong requires understanding multiple layers of abstraction, and the framework has gone through significant API changes that have frustrated teams maintaining long-running projects.
LlamaIndex
LlamaIndex has carved out a reputation as the more data-focused option, with stronger native support for complex document parsing, hierarchical indexing, and query decomposition. If your RAG application involves complex document structures — PDFs with tables, mixed media, nested document hierarchies — LlamaIndex’s data ingestion tooling tends to be more mature. It’s less of a general-purpose agent framework and more specifically optimized for the retrieval and indexing side of RAG, which can be a feature rather than a limitation depending on what you’re building.
Haystack
Haystack (by deepset) takes a more component-oriented, production-focused approach. The pipeline abstraction is designed to be serializable and deployable, with a focus on making RAG systems observable and maintainable in production. Teams building systems that need to run reliably in enterprise environments often find Haystack’s design philosophy aligns better with MLOps practices than LangChain’s more experimental-friendly approach.
Proprietary / Managed Solutions
On the proprietary side, offerings from vendors like Cohere (their RAG API product), Microsoft’s Azure AI Search with integrated RAG capabilities, and purpose-built enterprise RAG platforms offer significantly reduced infrastructure complexity at the cost of less flexibility and vendor lock-in. For organizations without dedicated ML infrastructure teams, the operational simplicity argument is compelling — managing vector database scaling, embedding model updates, and pipeline monitoring is genuinely non-trivial work.
Where RAG Is Headed: Advanced Patterns in 2026

RAG architecture has evolved well beyond the basic “embed → retrieve → generate” pipeline of two years ago. Several patterns are worth understanding if you’re working in this space.
Graph RAG combines vector retrieval with knowledge graph traversal. Rather than treating your document corpus as a flat bag of chunks, you build explicit relationships between entities and concepts, then retrieve by navigating both semantic similarity and structured relationships. Microsoft Research published work on this approach that attracted significant attention, and several enterprise implementations have reported substantially better performance on multi-hop reasoning questions — queries that require connecting information across multiple documents.
Agentic RAG gives the retrieval system agency to decide when and what to retrieve, rather than always performing a single retrieval step at query time. An agentic RAG system might decide to retrieve once, check if the retrieved context is sufficient, decide it isn’t, reformulate the query, retrieve again, and then generate. This is more expensive but handles complex queries dramatically better. See my piece on Physical AI and Agentic AI in 2026: The Next Frontier Beyond Chatbots for context on how agentic patterns are being applied across AI systems more broadly.
Multimodal RAG extends retrieval to include images, charts, tables, and other non-text content. With multimodal foundation models now widespread, organizations are building RAG systems that can retrieve and reason over diagrams in technical manuals, charts in financial reports, or images in medical records. This connects to the broader capabilities discussed in my Multi-Modal AI and Foundation Models in 2026: How the Next Generation of AI Actually Works explainer.
Streaming RAG begins generating a response before retrieval is fully complete, reducing perceived latency. Combined with progressive disclosure UI patterns, this makes RAG-powered applications feel significantly more responsive to end users, which has been an important adoption driver for consumer-facing RAG products.
Frequently Asked Questions
What’s the difference between RAG and just giving an AI access to a search engine?
This is one of the most common points of confusion, and it’s worth being precise. Web search integration typically means an AI tool can call a search API (like Bing or Google Search) and retrieve the top few results — usually as snippets and URLs. This is better than nothing, but it has significant limitations for serious applications. Web search results are optimized for human browsing, not machine consumption. They’re often noisy, contain irrelevant promotional content, and the snippets lack the surrounding context needed for nuanced reasoning. There’s no semantic ranking for your specific task — results are ranked by general relevance and SEO signals, not by how useful they are for your particular question.
RAG over a purpose-built index is architecturally different. Your source documents are pre-processed, chunked thoughtfully, embedded with a model that understands your domain, and stored in a vector database optimized for semantic retrieval. When a query comes in, the system finds the chunks that are most semantically relevant to that specific query, applies additional re-ranking if configured, and provides precisely scoped context to the generation model. The result is higher precision, lower noise, and the ability to maintain citations to specific internal documents — something web search integration fundamentally cannot provide for proprietary enterprise content. For use cases like querying your own contracts, internal documentation, or proprietary research, web search isn’t even a competing option. RAG is the only architecture that makes sense.
Does RAG actually prevent AI hallucinations, or does it just reduce them?
Reduces, not eliminates — and the distinction matters a lot in high-stakes applications. RAG provides grounding by giving the model accurate, up-to-date context to draw from, and when implemented well, it substantially lowers the rate at which models fabricate information. However, several failure modes persist. The model can still misread or misinterpret the retrieved context. If the retrieval step returns irrelevant or incorrect documents, the model may still generate incorrect answers based on that bad context (a problem sometimes called “context poisoning”). The model may also blend retrieved information with parametric memory in ways that introduce errors — particularly when the user’s question touches on both retrieved content and general knowledge simultaneously.
Additionally, if the correct answer genuinely isn’t in the indexed document corpus, a RAG system without a well-calibrated “I don’t know” response will often confabulate rather than admit the gap. This is a design and evaluation challenge that many implementations handle poorly. Best-practice RAG systems include confidence scoring on retrieved content, fallback behaviors when retrieval quality is low, and explicit training (or prompting) to acknowledge knowledge gaps rather than fill them with plausible-sounding fabrications. In high-stakes domains like medical or legal applications, treating RAG as a hallucination eliminator rather than a hallucination reducer is a genuinely dangerous assumption.
How do I know if RAG is the right solution, or if I should fine-tune instead?
The clearest signals that RAG is the right choice: your information changes frequently and you need the AI to reflect current data; you need source citations for compliance or verification; you’re working with proprietary documents that weren’t in any model’s training data; you want to update the knowledge base without retraining. The clearest signals for fine-tuning: you need the model to adopt a specific communication style or follow a particular format consistently; your task involves domain-specific reasoning patterns that the base model struggles with regardless of context provided; latency is critical and the retrieval step is prohibitive.
In practice, many production systems that started as pure RAG eventually layer in a fine-tuned generation model as well — using fine-tuning for style, tone, and domain reasoning patterns, while relying on RAG for factual currency and source grounding. This hybrid approach tends to outperform either in isolation for complex enterprise applications, though it comes with correspondingly higher engineering overhead. If you’re early in your AI deployment journey and choosing between the two, RAG is generally lower risk and lower cost to iterate on, since you can update your knowledge base without model training cycles. Fine-tune once your core retrieval pipeline is stable and you’ve identified specific generation quality issues that retrieval improvements alone can’t fix.
What vector database should I use for a new RAG project in 2026?
Honest answer: for most teams starting out, the database choice matters less than your chunking strategy and embedding model selection. That said, here are practical considerations. If you’re already in the PostgreSQL ecosystem, pgvector is the lowest-friction entry point and handles millions of vectors perfectly well. If you need managed infrastructure with minimal ops overhead and are comfortable with cloud costs, Pinecone has a strong production track record and generous documentation. If you need strong hybrid search (combining vector and keyword search) out of the box, Weaviate and Qdrant both have solid implementations and are fully open-source if self-hosting is a requirement.
For very large scale (hundreds of millions to billions of vectors), Milvus has been battle-tested in production at scale and has a robust distributed architecture, though the operational complexity increases accordingly. The trend in 2026 is toward databases that natively support metadata filtering at the vector search level, hybrid dense-sparse retrieval, and built-in re-ranking — features that used to require additional pipeline components. Evaluate these capabilities against your specific requirements rather than defaulting to whatever the most recent benchmark headline featured. Benchmarks are run under conditions that may not match your actual query patterns and data characteristics.
How much does it cost to build and run a production RAG system?
This varies so widely by scale and architecture choices that a single number would be misleading, but I can give you the cost components to reason about. Embedding costs at indexing time: running your document corpus through an embedding API or self-hosted embedding model. For OpenAI’s embedding models as of their current pricing, this is typically modest for most enterprise-scale corpora — often a few dollars to index tens of thousands of documents. Vector database costs: managed solutions like Pinecone charge based on the number of stored vectors and query volume. Self-hosted options shift cost to infrastructure and engineering time. LLM generation costs: every RAG query calls an LLM for the generation step, usually with a context window that includes both the user query and the retrieved chunks. For high-volume applications, this is often the dominant cost component.
A small-to-medium internal knowledge base application (a few thousand documents, moderate query volume) can be run for meaningfully less than the cost of a few enterprise software seats per month if you make thoughtful technology choices. A large-scale financial analysis system processing thousands of queries per day over a corpus of millions of documents is a different order of magnitude. The open-source path (self-hosted embedding model + self-hosted vector database + careful LLM usage) can dramatically reduce ongoing costs if you have the engineering capacity to manage the infrastructure. Most early-stage deployments start with managed services for speed, then optimize toward self-hosted components once usage patterns and bottlenecks are well understood.
What are the biggest failure modes in production RAG systems?
From what experienced practitioners consistently identify, the most common and impactful failure modes are: poor chunking (chunks too large, too small, or splitting mid-sentence or mid-concept so retrieved chunks lack coherent meaning); embedding model mismatch (using a general-purpose embedding model on highly specialized domain content where semantic similarity judgments don’t align with domain-relevant relevance); retrieval-generation mismatch (the retrieval system is evaluated on retrieval metrics, but the final system is judged on generation quality, and optimizing one doesn’t always improve the other); stale index (documents are updated but the vector index isn’t re-indexed, leading to retrievals based on outdated content while the source document has changed); and context window mismanagement (retrieving so many chunks that the LLM’s context window is mostly filled with marginally relevant content, diluting the actually relevant material).
The most insidious failure mode is retrieval that looks roughly right but is subtly wrong — returning a document that’s topically related but actually describes a different scenario, time period, or entity than the one the user is asking about. This produces confident-sounding but incorrect generation that passes casual review. Building evaluation pipelines that specifically test for this kind of near-miss retrieval error is more difficult than testing for obvious failures, but it’s where production system quality is often most sensitive.
Is RAG suitable for real-time applications like live customer support chat?
Yes, with appropriate architecture choices. The key latency contributors in a RAG pipeline are: query embedding (fast — typically under 50ms for most embedding APIs), vector search (fast — ANN search in a well-optimized vector database is typically under 100ms even for large indices), re-ranking (slower — cross-encoder re-ranking can add 100-300ms or more depending on the number of candidates and model size), and LLM generation (the dominant latency component for most setups). For a live chat application, streaming the LLM generation output (displaying tokens as they’re generated rather than waiting for the complete response) makes the system feel dramatically faster to end users, even if total time-to-complete is the same.
Practical optimization strategies for latency-sensitive RAG: cache embeddings for common query patterns; limit re-ranking to situations where initial retrieval confidence is low; use a smaller, faster LLM for latency-sensitive paths with a fallback to a more capable model for complex queries; optimize chunk count (retrieving 3 highly relevant chunks is usually better than retrieving 10 mediocre ones, and processes faster). Many customer support deployments also pre-compute embeddings for common query clusters, essentially maintaining a “hot cache” of likely retrievals. The customer support use case has been one of the highest-volume RAG deployment patterns in 2026, which has driven significant infrastructure optimization work that benefits all use cases.
How does RAG interact with newer long-context LLMs that can handle massive context windows?
This is a genuinely interesting architectural question that the field is actively working through. Long-context LLMs (models that can process hundreds of thousands of tokens) raise the question of whether you could simply stuff your entire document corpus into the context window instead of building a retrieval system. For small corpora, this is actually viable and removes retrieval failure modes entirely — if everything is in context, you can’t have retrieval misses. However, there are meaningful reasons RAG remains valuable even with very long context models.
First, cost: processing very long contexts is expensive per query, while vector retrieval amortizes indexing costs across many queries. For high-query-volume applications, the economics strongly favor retrieval. Second, the “lost in the middle” problem: research has consistently found that LLMs tend to underweight information in the middle of very long contexts, paying more attention to the beginning and end. RAG that surfaces the most relevant content effectively gets it into a shorter, higher-attention context. Third, practical corpus size: even with 1M+ token context windows, enterprise corpora of millions of documents exceed what fits in any context. RAG remains the only scalable architecture for large knowledge bases. The most likely evolution is hybrid approaches where retrieval narrows the candidate set to, say, a few thousand tokens of highly relevant content, which then gets processed with full long-context attention — getting the benefits of both approaches.
My Take: RAG Is Infrastructure, Not a Feature

The mental model shift that matters most here: RAG isn’t a feature you add to an AI product. It’s the infrastructure layer that determines whether your AI application is grounded in reality or performing an expensive simulation of knowledge. In 2026, the gap between AI tools with well-implemented RAG and those without it isn’t subtle — it’s the difference between a system users trust to make decisions with and one they use for casual exploration while mentally adding “but verify everything.”
If you’re evaluating AI tools for a serious application, the questions to ask aren’t “what model does it use?” but “what’s its retrieval architecture?” and “how current is its knowledge index?” If you’re building RAG systems, invest disproportionately in retrieval quality — the evidence is fairly consistent that this is where most quality gains are available. And if you’re trying to understand why some AI assistants seem startlingly well-informed while others confidently say wrong things, now you know where most of that difference comes from.
For a broader look at how these architectures fit into the larger landscape of AI capabilities, the How AI Models Actually Compare in 2026: Benchmarks, Real Performance Data, and What the Numbers Really Mean piece covers evaluation frameworks that apply directly to RAG-augmented systems as well.
Last updated: 2026
Explore more AI tools
👉 Browse the AI Tools Library to find the right tools for your workflow.