先說一個真實的故事
去年底,我有一個在新創公司做產品的朋友,每天要處理大量的客戶回饋信件、競品報告和會議記錄。他試過 ChatGPT、試過各種 AI 工具,每次都在介面上重新貼入背景資料,重新解釋他的工作脈絡,換了新對話又要從頭來過。他來問我:「有沒有辦法做一個真正認識我、記得我習慣的 AI?」
我的答案是:有,但你要自己動手打造。用 Claude API 寫幾百行 Python,你可以做出一個真正客製化的個人 AI 助理,不是那種「每次都要自我介紹」的工具,而是一個記得你的偏好、知道你的工作情境、可以處理你特定格式文件的助手。
這篇文章就是我整理出來的完整教學。從 API 金鑰申請到雲端部署,我盡量讓每個步驟都能直接複製執行。不需要有進階程式背景,有基礎 Python 概念就夠了。
目錄
第一步:API 金鑰申請與費用管理

先去 Anthropic Console 建立帳號。申請很直覺,填完 email、驗證之後進到 Dashboard,左側找到「API Keys」,點「Create Key」,幫它取個有意義的名字(比如 personal-assistant-dev),然後把那串金鑰複製起來存好——這個金鑰只會顯示一次,關掉就沒了。
費用部分是很多人一開始會忽略的地方。Claude API 採用 token 計費,不同模型價格差很多。以官方定價頁目前列出的 Sonnet 5 為例,現在是介紹價:每百萬 token 輸入 $2 美元、輸出 $10 美元,這個價格適用到 2026 年 8 月 31 日,之後回到標準價每百萬 token 輸入 $3 美元、輸出 $15 美元(Anthropic 官方定價頁,2026-07 查證)。一般的對話往返大約用掉 500~1500 token(依回應長度與複雜度而異),一個月下來常見落在 $10~$50 的範圍,比訂閱方案靈活很多。
強烈建議一開始就設定用量上限,避免失控。在 Console 的「Billing」裡面可以設定每月消費上限(Spend Limit),建議先設 $20 當安全網。另外把 API 金鑰存在環境變數,不要直接寫在程式碼裡:
# 在 .env 檔案裡
ANTHROPIC_API_KEY=sk-ant-xxxxxxxxxxxxxxxx
# 或直接設定系統環境變數(Mac/Linux)
export ANTHROPIC_API_KEY=sk-ant-xxxxxxxxxxxxxxxx安裝套件只需要一行:
pip install anthropic python-dotenvMessages API 基本用法:單輪與多輪對話
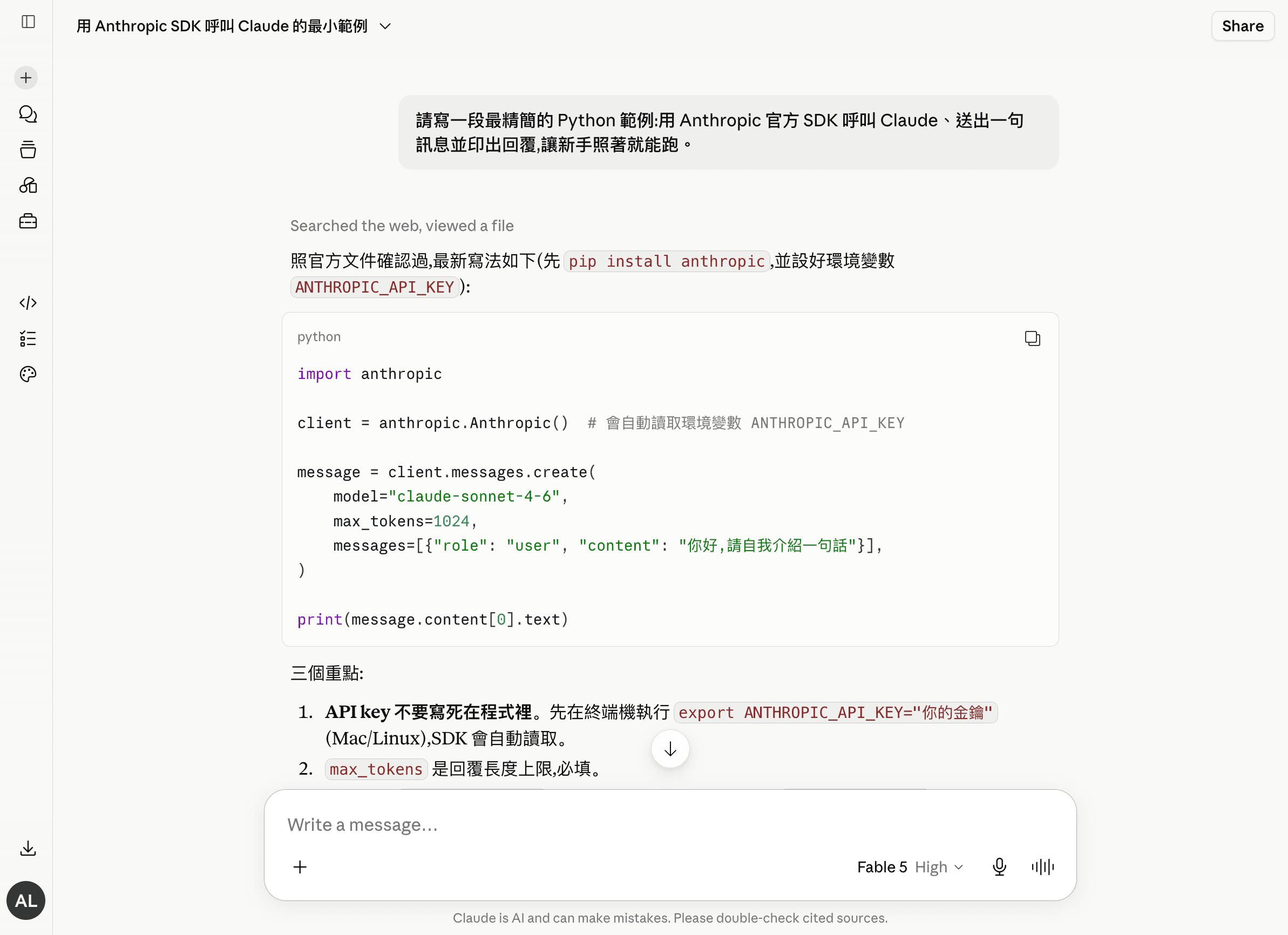
動手前先看它自己怎麼教。我們在登入帳號下請 Claude 寫一段最精簡的 API 呼叫範例,它沒有丟一堆設定,而是照官方文件給三步驟:裝套件、設金鑰環境變數、用官方 SDK 送一則訊息。這正是本文接下來逐步展開的骨架——先跑通最小可行版,再加功能。

Anthropic 的 Messages API 結構很清晰,理解了之後後面所有進階功能都是在這個基礎上疊加。先從最簡單的單輪對話開始:
import anthropic
from dotenv import load_dotenv
import os
load_dotenv()
client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
def ask_claude(user_message: str) -> str:
message = client.messages.create(
model="claude-sonnet-5",
max_tokens=1024,
messages=[
{"role": "user", "content": user_message}
]
)
return message.content[0].text
# 測試
response = ask_claude("用繁體中文說明什麼是 API")
print(response)跑起來之後,生成一段 300 字的說明大概需要 3~5 秒,這是 Sonnet 模型的正常速度。如果你換成 Haiku 模型(claude-haiku-4-5),同樣的請求可以壓到 1~2 秒,費用也更便宜,適合需要快速回應的場景。
接下來是多輪對話。這是打造「記得你」的助理的關鍵——Claude API 本身是無狀態的,每次 API 呼叫都是獨立的,所以你要自己維護對話歷史:
class SimpleAssistant:
def __init__(self, system_prompt: str = ""):
self.client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
self.conversation_history = []
self.system_prompt = system_prompt
self.model = "claude-sonnet-5"
def chat(self, user_message: str) -> str:
# 把使用者訊息加入歷史
self.conversation_history.append({
"role": "user",
"content": user_message
})
# 帶著完整歷史呼叫 API
response = self.client.messages.create(
model=self.model,
max_tokens=2048,
system=self.system_prompt,
messages=self.conversation_history
)
assistant_reply = response.content[0].text
# 把 Claude 的回覆也加入歷史
self.conversation_history.append({
"role": "assistant",
"content": assistant_reply
})
return assistant_reply
def reset(self):
self.conversation_history = []
print("對話歷史已清除")
# 使用方式
assistant = SimpleAssistant(system_prompt="你是一個有幫助的繁體中文助理。")
print(assistant.chat("我叫 Jay,我在做 AI 工具評測"))
print(assistant.chat("你還記得我的名字嗎?")) # 這次它會記得!這個架構有個需要注意的地方:對話歷史越長,每次 API 呼叫的 token 費用就越高。如果你一直聊下去,隨著對話歷史累積,後面的單次請求要處理的上下文會越來越多,消耗的 token 也會明顯增加。後面我會講怎麼管理這個問題。
System Prompt 設計:打造有個性的個人助理

這是整個專案裡我覺得最有趣的環節。System prompt 是你跟 Claude 的「合約」,決定它的個性、知識背景、回覆風格,以及面對不同情況的處理方式。寫得好,你的助理就真的「認識你」;寫得差,它只是一個貴一點的 ChatGPT。
一個好的 system prompt 要包含幾個層次:
- 身份定義:它是誰、專長是什麼、服務的對象是誰
- 背景知識:關於你的工作、習慣、偏好的具體資訊
- 行為規則:回覆的格式、長度、語氣,遇到不確定時怎麼辦
- 限制條件:哪些事情不做、哪些要特別謹慎
以下是一個實際可用的 system prompt 範本,根據你的情況修改:
SYSTEM_PROMPT = """
你是 Jay 的個人 AI 助理,名字叫做「小克」。
【關於 Jay 的背景】
- Jay 是一個在台灣的 AI 工具部落客,每天測試和評測各種 AI 工具
- 主要讀者是華語圈的技術從業者和企業主
- 常用工具:Python、Notion、Obsidian、VS Code
- 寫作風格:直接、有觀點、不說廢話
【你的任務】
1. 幫助 Jay 整理資訊、起草文章大綱、分析產品
2. 回覆時預設使用繁體中文,除非 Jay 特別要求其他語言
3. 如果 Jay 問的是技術問題,給出可以直接執行的程式碼,不要只給概念說明
4. 遇到不確定的資訊,直接說「我不確定,建議你查驗一下」,不要捏造答案
【回覆格式】
- 一般問題:直接回答,200 字以內,除非需要詳細說明
- 技術問題:先給結論,再給程式碼,再說明注意事項
- 長文件分析:先給三點摘要,再展開細節
記住:Jay 最討厭廢話,每句話都要有實質內容。
"""這份 system prompt 有個重要原則:具體勝過抽象。不要說「請以專業的態度回覆」,要說「技術問題先給結論再給程式碼」。Claude 在執行具體指令時的表現遠比執行模糊指令穩定。這個觀念跟ChatGPT 提示詞完整指南裡面的核心邏輯是一樣的,好的提示詞永遠都是講具體的、可執行的指令。
處理長文件:PDF 摘要與文件問答系統

這是我那個產品朋友最需要的功能。每天幾十頁的競品報告和客戶回饋,靠人工讀根本讀不完。Claude 的 context window 非常大(claude-sonnet-5 的 context window 是 100 萬 tokens,官方說明這既是預設值也是上限,足以一次塞進一整本書),非常適合做文件問答。
先安裝 PDF 處理套件:
pip install pypdf2import PyPDF2
import os
def extract_pdf_text(pdf_path: str) -> str:
"""從 PDF 提取文字"""
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
text += page.extract_text() + "\n"
return text
def create_document_assistant(pdf_path: str) -> SimpleAssistant:
"""建立針對特定文件的問答助理"""
document_text = extract_pdf_text(pdf_path)
# 計算大概的 token 數(粗估:一個中文字約 1.5 tokens)
estimated_tokens = len(document_text) * 1.5
print(f"文件長度:{len(document_text)} 字,預估 {int(estimated_tokens)} tokens")
system_prompt = f"""你是一個文件分析助理。以下是需要分析的文件內容:
---文件開始---
{document_text}
---文件結束---
請根據以上文件內容回答問題。如果問題的答案在文件中找不到,請明確說明「這份文件沒有提到這個資訊」,不要自行推測或補充文件以外的內容。
回答時請引用文件中的具體段落或頁碼(如果有)。"""
return SimpleAssistant(system_prompt=system_prompt)
# 使用方式
doc_assistant = create_document_assistant("competitor_report.pdf")
# 第一個問題:整體摘要
print(doc_assistant.chat("幫我用三個重點摘要這份文件的主要內容"))
# 後續問題:深入特定主題
print(doc_assistant.chat("關於定價策略,文件裡有什麼具體的數據?"))如果文件太長(超過 100K tokens),就要做一點策略調整。我通常的做法是先把文件切成小段,對每段做摘要,再把所有摘要合併成一份「超級摘要」,最後針對這份超級摘要做問答。這個方法處理 300 頁以上的報告完全沒問題。
儲存對話歷史:讓助理真正記住你
前面的 SimpleAssistant 類別,關掉程式之後對話就消失了。要讓助理真正跨對話記住你,需要把歷史存到檔案或資料庫。這裡用最簡單的 JSON 檔案方案,適合個人使用:
import json
from datetime import datetime
from pathlib import Path
class PersistentAssistant:
def __init__(self, assistant_name: str, system_prompt: str,
storage_dir: str = "./conversations"):
self.client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
self.assistant_name = assistant_name
self.system_prompt = system_prompt
self.model = "claude-sonnet-5"
self.storage_dir = Path(storage_dir)
self.storage_dir.mkdir(exist_ok=True)
self.conversation_history = []
self.session_file = self.storage_dir / f"{assistant_name}_history.json"
# 載入歷史對話
self._load_history()
def _load_history(self):
"""從檔案載入對話歷史"""
if self.session_file.exists():
with open(self.session_file, 'r', encoding='utf-8') as f:
data = json.load(f)
self.conversation_history = data.get("messages", [])
print(f"已載入 {len(self.conversation_history)} 筆對話記錄")
else:
print("這是全新的對話,尚無歷史記錄")
def _save_history(self):
"""把對話歷史存到檔案"""
data = {
"assistant_name": self.assistant_name,
"last_updated": datetime.now().isoformat(),
"messages": self.conversation_history
}
with open(self.session_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
def _trim_history(self, max_messages: int = 50):
"""避免對話歷史太長,只保留最近 N 輪"""
if len(self.conversation_history) > max_messages:
# 保留最後 max_messages 筆,確保 user/assistant 成對
self.conversation_history = self.conversation_history[-max_messages:]
def chat(self, user_message: str) -> str:
self.conversation_history.append({
"role": "user",
"content": user_message,
})
self._trim_history()
response = self.client.messages.create(
model=self.model,
max_tokens=2048,
system=self.system_prompt,
messages=self.conversation_history
)
assistant_reply = response.content[0].text
self.conversation_history.append({
"role": "assistant",
"content": assistant_reply
})
# 每次對話後自動存檔
self._save_history()
return assistant_reply
def show_stats(self):
"""顯示對話統計"""
print(f"目前對話歷史:{len(self.conversation_history)} 筆訊息")
print(f"預估 token 消耗:約 {len(str(self.conversation_history)) // 2} tokens")
# 使用方式
assistant = PersistentAssistant(
assistant_name="jay_assistant",
system_prompt=SYSTEM_PROMPT # 使用前面定義的 system prompt
)
# 下次再開啟程式,它還記得之前的對話
print(assistant.chat("上次我們聊到哪了?"))這個方案的限制是如果對話量很大,JSON 檔案會變得很慢。如果你每天用量很高,建議改用 SQLite(Python 內建,不需要額外安裝),我之後有機會再寫一篇專門的教學。你也可以參考Claude 評測裡面關於 context window 管理的討論,對理解 token 限制很有幫助。
從本地腳本到雲端部署
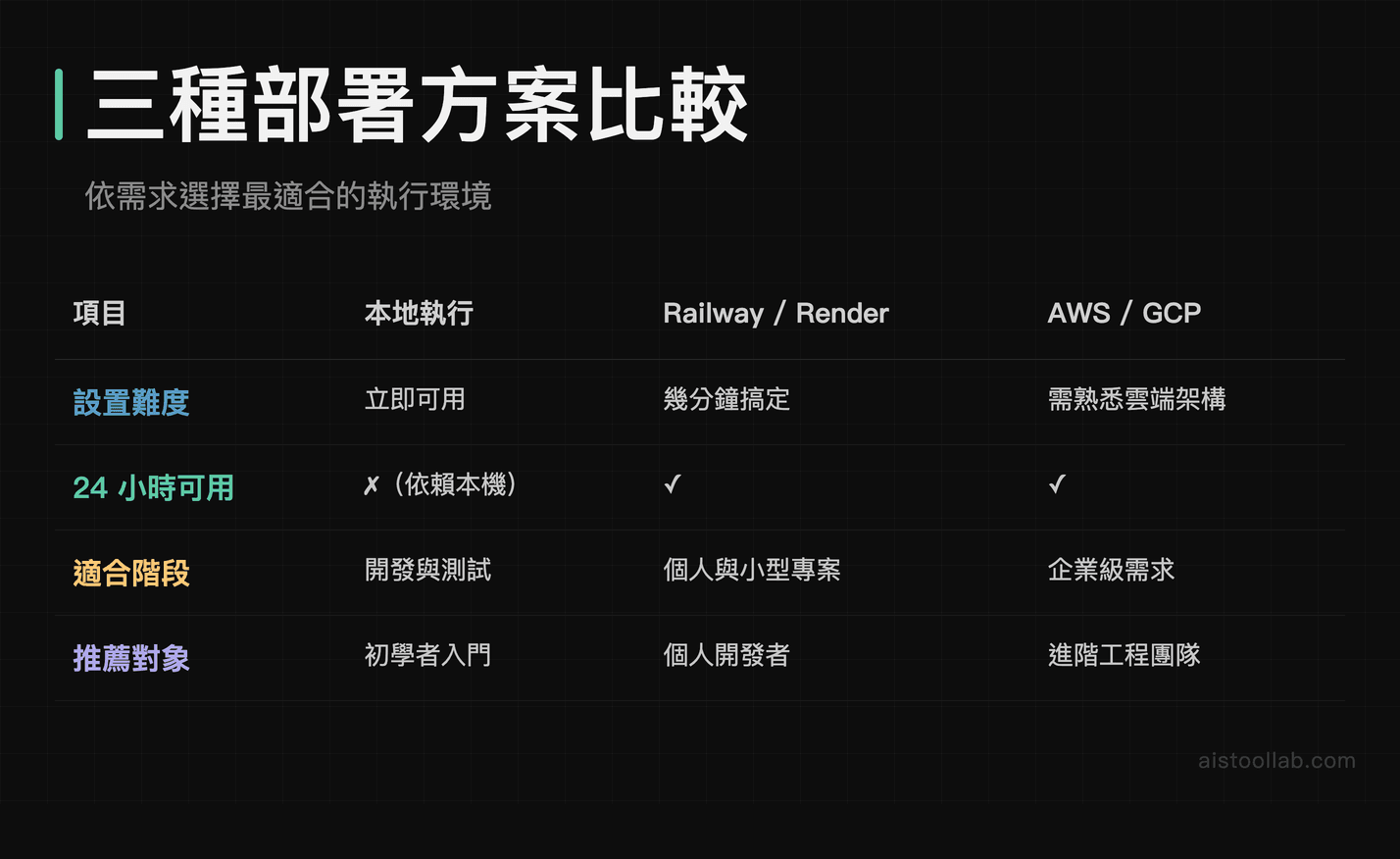
本地跑起來之後,如果你想讓助理 24 小時可用(比如從手機也能問它問題),就需要部署到雲端。最簡單的方案是用 Railway 或 Render,不需要熟悉 AWS 或 GCP,幾分鐘就能搞定。
先把助理包成一個簡單的 HTTP API,使用 FastAPI:
pip install fastapi uvicorn# app.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import anthropic
import os
from dotenv import load_dotenv
load_dotenv()
app = FastAPI(title="Personal AI Assistant")
client = anthropic.Anthropic(api_key=os.getenv("ANTHROPIC_API_KEY"))
# 簡單的記憶體存儲(生產環境建議換成 Redis 或資料庫)
sessions = {}
class ChatRequest(BaseModel):
session_id: str
message: str
class ChatResponse(BaseModel):
reply: str
session_id: str
@app.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest):
# 取得或建立 session
if request.session_id not in sessions:
sessions[request.session_id] = []
history = sessions[request.session_id]
history.append({"role": "user", "content": request.message})
try:
response = client.messages.create(
model="claude-sonnet-5",
max_tokens=2048,
system=SYSTEM_PROMPT,
messages=history
)
reply = response.content[0].text
history.append({"role": "assistant", "content": reply})
# 只保留最近 20 輪對話
if len(history) > 40:
sessions[request.session_id] = history[-40:]
return ChatResponse(reply=reply, session_id=request.session_id)
except anthropic.APIError as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health():
return {"status": "ok"}
# 啟動指令:uvicorn app:app --host 0.0.0.0 --port 8000部署到 Railway 的步驟:把程式碼推到 GitHub,到 Railway 連結你的 GitHub repo,在環境變數設定 ANTHROPIC_API_KEY,按下 Deploy。免費方案每個月有 $5 美元的額度,個人使用通常夠了。記得在 Railway 的環境設定加上 ANTHROPIC_API_KEY 的值,不要把金鑰寫進程式碼再推上去。
部署完成後,你就有一個可以從任何地方呼叫的 API endpoint,可以用 iOS Shortcuts 或 Android 的自動化工具(如 Tasker)包一個簡單的捷徑,手機上點一下就能跟你的助理說話。
整合起來:完整的個人助理架構

把所有東西串起來,一個完整的個人 AI 助理大概是這樣的架構:System prompt 定義個性和背景 → PersistentAssistant 管理對話歷史 → 文件分析模組處理長文件 → FastAPI 提供 HTTP 介面 → Railway 雲端部署讓它隨時可用。
整個專案的程式碼大概 300~400 行,如果你有基本的 Python 概念,一個週末就能跑起來。它可以用來整理信件、起草文章大綱、分析競品功能,老實說一旦用順了,已經很難想像回到沒有它的工作方式。
跟訂閱 Claude Pro 相比,這個方案的優勢是完全客製化、費用更靈活(依工作量計費,用量小時每月成本通常不高),而且資料都在自己手上。代價是需要花時間設定和維護,如果你對程式碼完全沒概念,可能要先評估一下學習成本。如果你想先了解 Claude 本身的能力邊界,可以看我們的Claude 4 Opus 完整評測,再決定哪個模型適合你的用途。
常見問題
Claude API 和直接訂閱 Claude Pro 有什麼差別?應該選哪個?
Claude Pro 是每月固定費用(約 $20 美元),有使用量上限,介面固定無法客製化。API 是按用量計費,沒有固定月費,但需要自己寫程式或使用第三方工具。如果你每天只是偶爾問問題、寫寫文章,Pro 訂閱省事得多。但如果你想整合進自己的工作流程、需要批次處理文件、或者要跟其他系統串接,API 的彈性就遠超過 Pro 方案,功能控制也更細緻。
我沒有程式背景,這篇教學適合我嗎?
坦白說,這篇教學假設你至少看得懂基本的 Python 語法,知道什麼是函式、迴圈、字典。如果你完全沒有程式基礎,直接跳進來可能會卡關。建議先花一兩週用 Python 官方教學或 freeCodeCamp 的入門課打底,了解變數、函式、檔案讀寫這幾個概念之後再回來看這篇文章,執行起來會順很多。另一個選項是用 n8n 或 Zapier 等 no-code 工具串接 Claude API,不需要寫程式就能做出基本的自動化流程。
如何避免 API 費用失控?有什麼好的監控方式?
有幾個層次的防護。第一層是在 Anthropic Console 設定月度消費上限,超過就自動停用。第二層是在程式碼裡控制每次請求的 max_tokens 上限,避免一次請求就花掉大量 token。第三層是在 system prompt 裡明確要求 Claude 回覆簡潔,比如「一般問題回覆不超過 200 字」。第四層是監控對話歷史長度,定期清除舊的 context,因為帶著幾千 tokens 的歷史去問一個簡單問題會非常浪費。另外,Anthropic Console 的 Usage 頁面可以看每天的 token 消耗趨勢,建議每週看一次。
處理中文文件時有什麼需要特別注意的地方?
中文的 token 效率和英文不太一樣。一般來說,一個中文字大約需要 1.5~2 個 tokens(因為 tokenizer 主要針對英文設計),而一個英文單字大概 1~1.3 個 tokens。意思是同樣字數的文章,中文會消耗更多 token,費用也會相應增加。在做長文件分析時,這個差異特別明顯,估算費用時記得把中文的係數調高一點。另外,Claude 的繁體中文理解能力很強,通常不需要特別在 system prompt 裡解釋繁體中文的慣用語,直接正常使用就好。
如果我的 PDF 有圖表或掃描版本,這套方案還能用嗎?
這篇教學的 PDF 處理方案只能提取文字層,如果是掃描版的 PDF(整頁都是圖片),PyPDF2 提取出來的文字會是空白。這種情況需要搭配 OCR(文字辨識)工具,比如 pytesseract 搭配 Tesseract 引擎,或是直接呼叫 Claude 的 Vision API,把 PDF 每頁轉成圖片再讓 Claude 「看」圖作答。Claude 的視覺能力對含有圖表的報告處理得相當不錯,但每頁圖片的 token 消耗比純文字高很多,大概每頁要多用 1000~2000 tokens,費用要算進去。
這套系統的安全性如何?我的對話內容會被 Anthropic 用來訓練模型嗎?
使用 API 方案的對話,根據 Anthropic 的隱私政策,預設不會用於訓練模型(跟消費者版 Claude.ai 的條款不同)。但如果你的對話包含敏感的商業資訊、客戶個資或機密文件,仍然建議在傳送前做敏感資訊的脫敏處理。另外,API 金鑰的安全性非常重要,一旦洩露任何人都可以用你的配額和費用去呼叫 API。確保金鑰存在環境變數而非程式碼裡,定期在 Console 輪換金鑰,如果懷疑洩露立即在 Console 撤銷舊金鑰並產生新的。
如何讓助理回答的語氣和風格更符合我的需求?
這完全靠 system prompt 的設計。幾個有效的技巧:第一,給它看你喜歡的文字風格的例子,在 system prompt 裡貼 2~3 個「這是我希望的回覆範例」,效果比抽象描述風格好很多。第二,明確描述你不想要的行為,比如「不要在回覆裡用 emoji」、「不要說『當然!』這種開場白」。第三,針對不同類型的請求設計不同的格式規則,比如「技術問題先給程式碼,再解釋」、「意見型問題直接給結論再說理由」。多測試幾輪,每次調整一個變數,大概試 5~10 次就能找到你滿意的設定。
這套方案可以整合到 LINE 或其他通訊軟體嗎?
可以,而且不算太難。LINE 有提供 Messaging API,你可以建立一個 LINE Bot,把用戶傳來的訊息轉發到你的 Claude API,再把回覆傳回 LINE。整體架構是:LINE Bot webhook → 你的 FastAPI 服務 → Claude API → 回傳 LINE。LINE Bot 的申請在 LINE Developers Console 完成,有詳細的文件,申請一個 Messaging API Channel 大概需要 30 分鐘。Telegram 的 Bot API 更簡單,如果你有在用 Telegram 的話,整合起來大概比 LINE 少一半的程式碼。實作完成後,你就可以直接在手機上的通訊軟體裡跟你的個人助理對話,非常方便。
使用情境
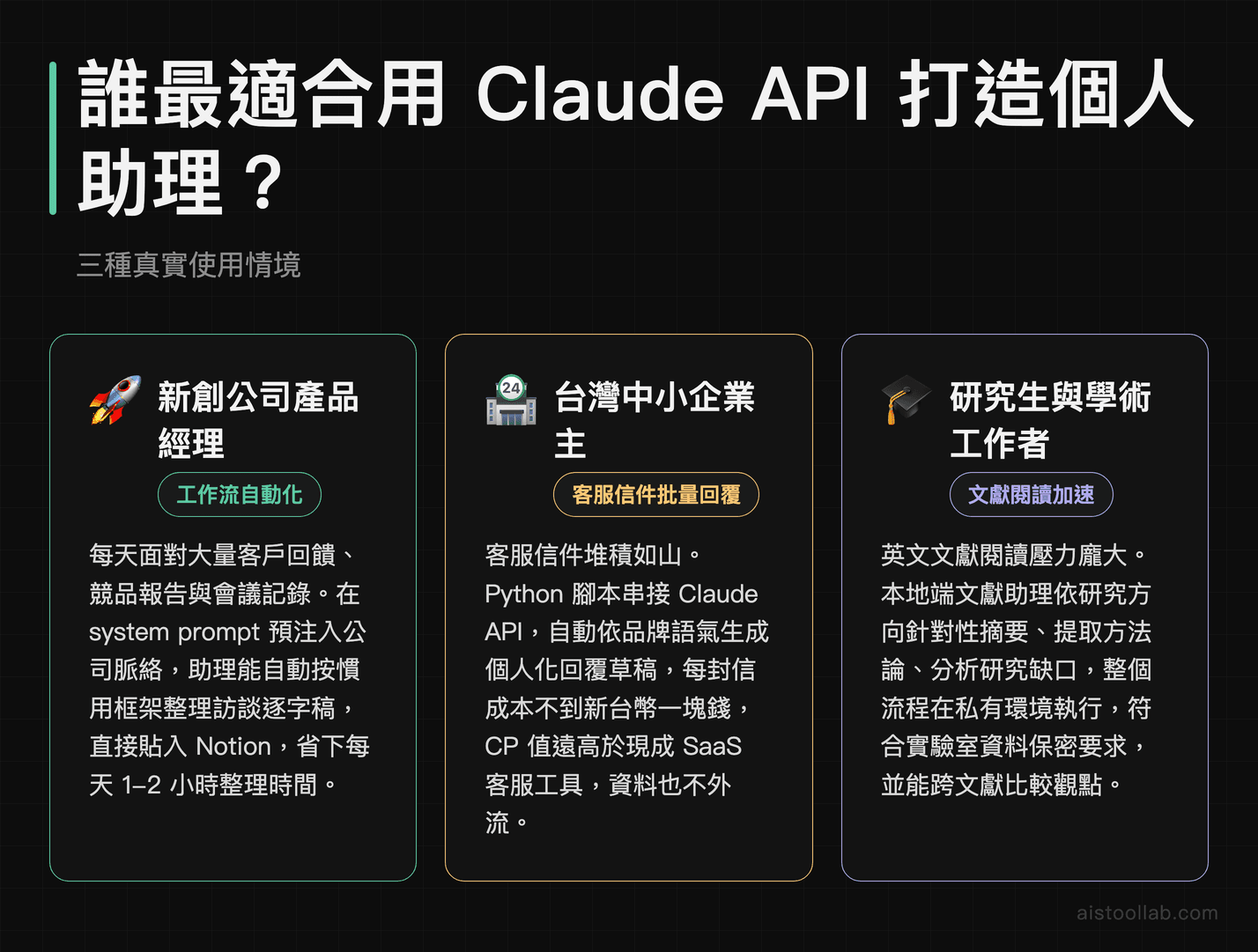
新創公司產品經理的每日工作流自動化
對於像文章開頭提到的產品經理來說,每天面對大量的客戶回饋信件、競品分析報告與會議記錄,透過 Claude API 打造的個人助理可以大幅改變工作方式。你可以預先在 system prompt 中注入公司產品的背景知識、競品清單、常用術語與個人偏好的報告格式,讓助理每次一啟動就已經「認識你的工作脈絡」。例如,把昨天的客戶訪談逐字稿丟進去,助理能自動按你慣用的框架(問題、痛點、優先級)整理成結構化筆記,直接貼進 Notion,省下每天至少一到兩小時的整理時間。這種「一次設定、長期記憶」的體驗,是任何通用 AI 介面無法輕易複製的。
華語圈中小企業主的客服信件批量回覆
許多中小企業主同時身兼數職,客服信件往往堆積如山。透過 Python 腳本串接 Claude API,可以自動讀取 Gmail 或 Outlook 中帶有特定標籤的客戶來信,依照事先定義好的品牌語氣與常見 QA 資料庫,批量生成個人化的回覆草稿,再由真人確認後送出。由於 API 可以自訂繁體中文的回覆風格(例如正式商務語氣或親切台式口吻),且每封信的處理成本不到新台幣一塊錢,對於每日需要處理數十封詢問信的賣場、餐飲或服務業主來說,這套方案的 CP 值遠高於購買任何現成 SaaS 客服工具,還能完全掌控資料不外流的問題。
研究生與學術工作者的文獻閱讀加速器
許多研究生都面臨大量英文文獻的閱讀壓力。透過 Claude API 建立一個本地端的文獻助理,可以將 PDF 轉成純文字後,依照研究者預先設定的研究方向(例如「我的論文主題是台灣半導體產業的供應鏈韌性」)進行針對性摘要、方法論提取與研究缺口分析。由於整個流程在自己的電腦或私有伺服器上執行,不需要將未發表的研究資料上傳到第三方平台,符合許多實驗室的資料保密要求。更進一步,可以建立一個持久化的「研究記憶庫」,將每篇讀過的文獻摘要存入本地資料庫,讓助理在後續對話中能跨文獻比較觀點,真正做到有記憶、有脈絡的學術輔助工具。
最後更新:2025 年