The Thing Nobody Tells You About “Smarter” AI
Here’s a belief most people hold without questioning it: that making AI more capable means training a bigger model on more data. Scale the parameters, scrape more of the internet, spend another few hundred million dollars on compute — and you get a smarter system. It’s the assumption that’s driven the last five years of AI development, and honestly, it’s gotten us pretty far.
But there’s a problem with that story, and it’s been quietly sitting in the corner of AI research for a while now. The models we’ve been building — even the genuinely impressive ones — are, at their core, static. You train them, they freeze, and then they’re deployed into a world that keeps changing without them. A model trained in early 2024 doesn’t know what happened in late 2024. Ask it to adapt to your specific codebase or your medical practice’s particular patient patterns, and it can’t — not without full retraining, which is prohibitively expensive. The intelligence is real, but it’s encased in amber.
What’s actually shifting in 2026 isn’t just raw capability in the “answers more questions correctly” sense. The deeper change is architectural and behavioral — how these systems learn over time, what they remember, how they adapt without breaking. That shift is less flashy than a new benchmark score, but it matters a lot more for whether AI actually becomes useful in the real world over the long term. Let me break down what’s happening, what the research actually shows, and what’s still very much a work in progress.
Contents
The Catastrophic Forgetting Problem — And Why It’s Harder to Solve Than It Sounds
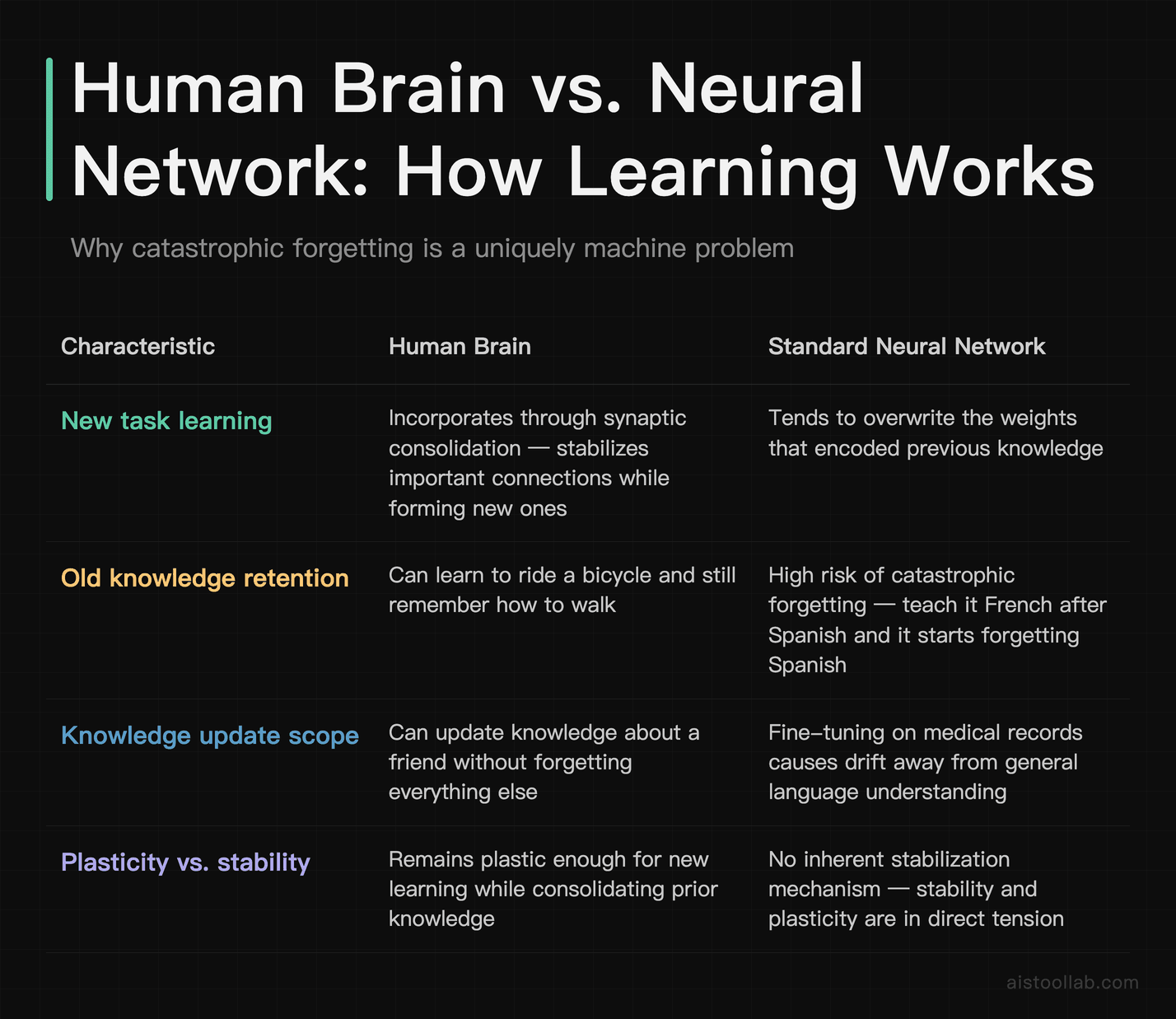
To understand why continual learning is a big deal, you need to understand the problem it’s solving. It has an appropriately dramatic name: catastrophic forgetting. When a standard neural network is trained on a new task or new data, it tends to overwrite the weights that encoded previous knowledge. Teach it French after it’s learned Spanish, and it starts forgetting Spanish. Fine-tune it on medical records after pretraining on general text, and it drifts away from its general language understanding.
Human brains don’t work this way — at least not nearly as severely. We can learn to ride a bicycle and still remember how to walk. We can update our knowledge about a friend without forgetting everything else we know. Neuroscience research generally suggests this is partly due to what’s called synaptic consolidation — a process where the brain stabilizes important connections while remaining plastic enough to form new ones. The analogy to neural networks is imperfect, but it’s been enormously influential in AI research.
The algorithmic parallel that got a lot of attention in the machine learning community was Elastic Weight Consolidation (EWC). The original EWC paper by Kirkpatrick et al., published at ICML 2017, introduced the idea of selectively protecting weights that are important for previously learned tasks — essentially mimicking synaptic consolidation mathematically. It was a meaningful step, but it had real limits: it didn’t scale elegantly to modern large models, and the “importance” estimation was approximate at best.
What’s changed since then is a combination of better theoretical grounding, new architectural designs, and — critically — more serious investment from major labs in making continual learning actually work at deployment scale rather than just in controlled academic benchmarks. The research is still maturing, but the trajectory is real.
What Continual Learning Actually Looks Like in 2026

The term “continual learning” gets used loosely, so it’s worth being specific about what it means in practice. There are roughly three paradigms researchers work with:
- Task-incremental learning: The model knows which task it’s being asked to perform and needs to maintain performance across tasks over time.
- Domain-incremental learning: The task stays the same, but the distribution of inputs shifts — think a language model adapting to new slang, technical jargon, or a changing news landscape.
- Class-incremental learning: The hardest setting — the model must classify new categories of things it’s never seen, without forgetting old ones, and without task labels at inference time.
Most real-world deployment scenarios fall into the second category. A coding assistant that can adapt to new frameworks as they emerge, without forgetting how older stacks work, is genuinely useful. A medical diagnosis support tool that can incorporate updated clinical guidelines without needing a full retrain cycle is potentially very valuable. Research in these areas has been progressing, with findings generally suggesting that a combination of replay-based methods (where the model periodically revisits stored examples of previous tasks) and architectural regularization produces more stable long-term retention than either approach alone.
What’s harder to assess from the outside is how much of this has crossed the threshold from “promising research result” to “production-ready system.” The honest answer is: it varies enormously by application, and anyone claiming they’ve fully solved catastrophic forgetting in large-scale systems is probably overstating things. What seems more accurate is that the worst failure modes are being managed better, and that some specific application domains — particularly those with well-structured, incremental data streams — are seeing real benefits from these techniques.
Breaking Out of the Transformer Box: Why Architecture Matters Now

For the better part of five years, the Transformer architecture — introduced in the 2017 “Attention Is All You Need” paper — was essentially the default answer to almost every serious deep learning problem. It’s genuinely powerful, and its dominance wasn’t accidental. But the community has been increasingly honest about its limitations, particularly as use cases push toward longer contexts, real-time adaptation, and efficient deployment on edge devices.
The core issue is computational: the self-attention mechanism in Transformers scales quadratically with sequence length. That means processing a context that’s twice as long takes roughly four times the computation. For tasks that require reasoning over very long documents, continuous streams of data, or rapid iterative updates, this becomes a serious constraint — not just in theory, but in real deployment cost and latency.
State-space models (SSMs) have emerged as the most credible architectural alternative to gain serious traction. The family of models associated with the Mamba architecture — developed by researchers including Albert Gu and Tri Dao, with work published on arXiv in late 2023 and subsequently expanded — demonstrated that it’s possible to achieve competitive performance with Transformers on many language modeling benchmarks while scaling linearly with sequence length rather than quadratically. That’s not a small difference in practice.
The intuition behind SSMs is that they maintain a compressed hidden state that gets updated as new input arrives, rather than attending back over the full context at every step. It’s more like how a person reads a document — you maintain a running understanding that updates, rather than re-reading everything from scratch every time you process a new word. Current evidence suggests SSMs are particularly strong for tasks involving very long sequences or continuous data streams, though research into their performance on tasks requiring complex multi-step reasoning is still developing, and findings are mixed depending on the specific benchmark and configuration.
By 2025-2026, hybrid architectures — combining SSM-style recurrence with selective attention mechanisms for parts of the context where precise retrieval matters — have become an active area of development at multiple major labs. According to publicly available technical documentation from various research groups, these hybrids aim to get the memory efficiency of SSMs while retaining the associative retrieval strengths of attention. Whether they’ll displace Transformers as the dominant architecture at scale is genuinely uncertain — the infrastructure investment behind Transformer-optimized hardware is enormous, and architectural transitions don’t happen overnight.
Use Cases: Where This Actually Changes Things

1. Software Development and Coding Assistants
A freelance developer working solo across three or four client projects in different tech stacks is probably the clearest beneficiary of continual learning improvements in the near term. The current frustration with coding assistants is well documented in developer communities: the model is great at common patterns but falls apart when you’re working with a niche framework, a company-specific internal library, or code that’s evolved significantly since the model’s training cutoff. You end up spending time correcting the assistant or providing context it should be able to infer.
Adaptive coding assistants that can update their internal representations as they work within a specific codebase — without forgetting general programming knowledge — address this directly. The assistant starts to understand your naming conventions, your architecture patterns, your preferred error-handling approach. Early versions of this kind of project-aware adaptation have appeared in several coding tools, though the depth of the adaptation varies considerably. For a developer billing hourly, even a modest improvement in context-awareness translates to real time savings. Check out the 9 AI Tools Launched in 2026 Worth Your Time roundup for a look at which recent coding tools are pushing in this direction.
2. Healthcare and Clinical Decision Support
This is where the stakes for getting continual learning right are highest, and also where the current state of deployment is most conservative — appropriately so. Clinical guidelines change. Drug interaction databases get updated. New evidence emerges about treatment efficacy. A static model trained on data from 18 months ago may be confidently citing guidance that’s since been revised.
Research generally suggests that domain-incremental learning — updating a model’s knowledge of a specific field as new evidence arrives, without retraining from scratch — is particularly relevant here. The challenge is validation: in a clinical context, you need to be confident that updating the model’s knowledge in one area hasn’t degraded its performance elsewhere. The regulatory and liability environment adds another layer of complexity that pure research benchmarks don’t capture. Current work in this space tends to focus on narrow, well-scoped applications — specific disease areas, specific types of clinical notes — rather than general-purpose medical AI that continuously updates across all domains.
3. Content Creation and Real-Time Personalization
A SaaS startup with a two-person marketing team using AI for content creation runs into a familiar problem: the output sounds generic because the model doesn’t know their brand voice, their specific audience, or the particular arguments that resonate in their niche. The current workaround is extensive prompting and manual editing. Continual learning applied here means the model accumulates understanding of what works for a specific brand over time — not just from explicit instructions, but from feedback patterns.
The privacy and data governance implications of this are non-trivial, and any serious deployment needs to think carefully about what data is being retained and how. But the potential value for content teams is significant: an assistant that genuinely learns your voice rather than requiring you to re-explain it every session. For more context on how multimodal capabilities are evolving alongside these personalization improvements, the Multi-Modal AI and Foundation Models in 2026 article covers the broader landscape well.
Comparing 2025 vs 2026: What’s Concretely Different
The Real State of Play: What the Research Actually Shows
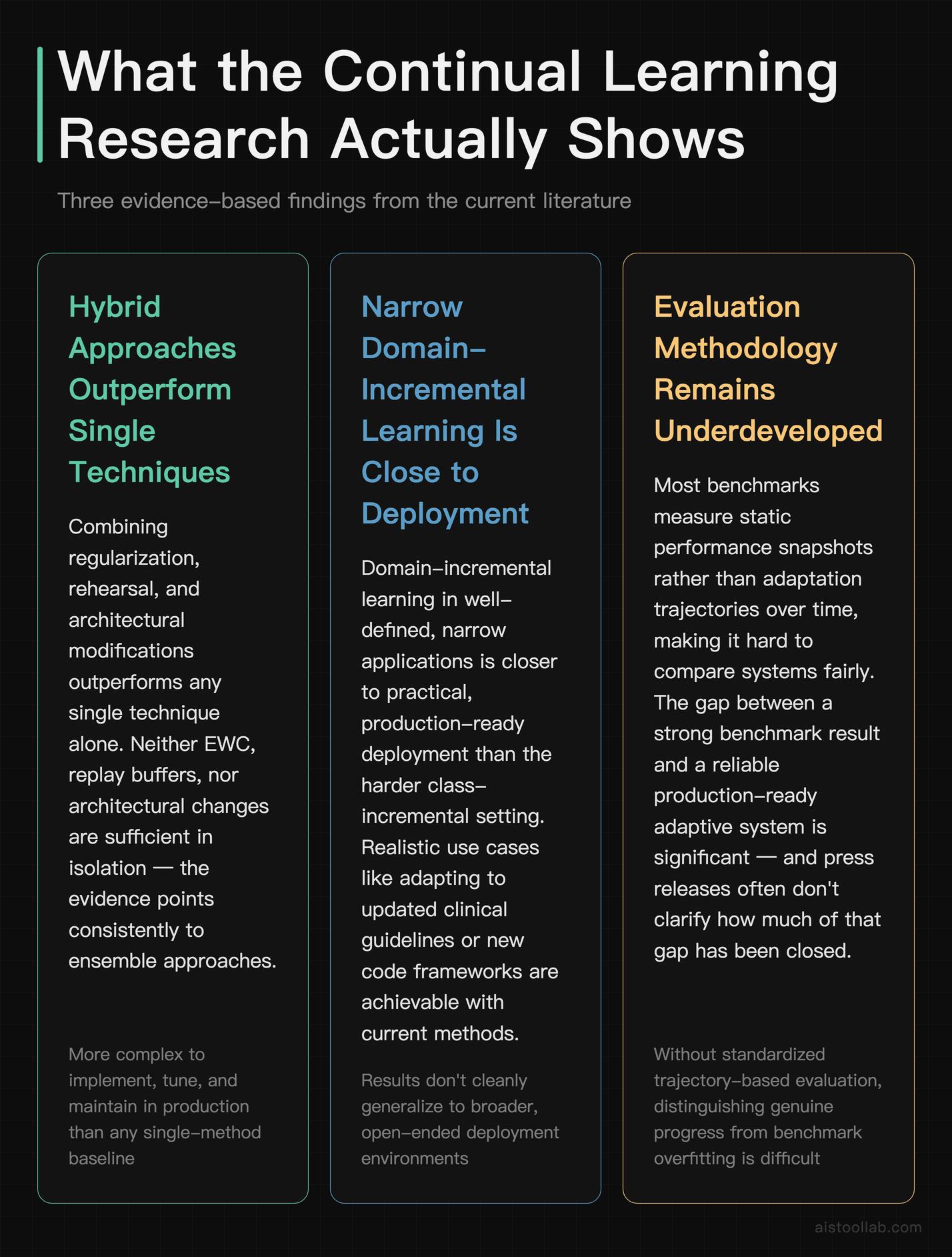
It’s worth being direct about what we know versus what we’re projecting. The research literature on continual learning is genuinely rich and moving fast — but a lot of it is evaluated on benchmark datasets that are cleaner and more structured than real-world deployment scenarios. The gap between a strong result on a standard continual learning benchmark and a reliable, production-ready adaptive system is significant, and it’s not always clear from press releases or product announcements how much of that gap has actually been closed.
Current evidence generally suggests three things: first, that hybrid approaches combining regularization, rehearsal, and architectural modifications outperform any single technique alone. Second, that domain-incremental learning in narrow, well-defined applications is closer to practical deployment than the harder class-incremental setting. Third, that the evaluation methodology for adaptive AI systems is still underdeveloped — most benchmarks measure static performance snapshots rather than adaptation trajectories over time, which makes it hard to compare systems fairly.
The state-space model story is in some ways cleaner: the theoretical advantages are well-established, the early empirical results were genuine, and production deployments are happening. What’s less clear is how the landscape settles at the frontier scale, where Transformer infrastructure and optimization are deeply entrenched. The most likely outcome, based on how architectural transitions have gone historically in deep learning, is a period of coexistence and hybridization rather than a clean replacement.
For a grounded look at how these architectural differences translate into real benchmark performance differences today, the How AI Models Actually Compare in 2026 article gets into the numbers in useful detail.
Frequently Asked Questions
What exactly is continual learning, and how is it different from just retraining a model?
Retraining a model means starting a new training run — usually from scratch or from a checkpoint — on updated data. It’s expensive, time-consuming, and the model has no connection to how it was used in deployment. Continual learning, by contrast, refers to a model that updates its parameters incrementally as new data arrives, while attempting to preserve knowledge it already has. The key challenge it addresses is catastrophic forgetting — the tendency of neural networks to overwrite existing knowledge when learning something new. The distinction matters practically because retraining cycles for large models can take weeks and cost significant compute resources, making them impractical for fast-moving domains like news, medicine, or software development. Continual learning approaches aim to make knowledge updates more like how a person learns — incorporating new information without erasing what came before. Current techniques achieve this to varying degrees depending on the type of task, the rate of new data arrival, and the size of the model. It’s not a fully solved problem, but meaningful progress has been made in specific deployment scenarios, particularly domain-incremental settings where the core task remains stable and new data represents updates to existing knowledge rather than entirely new categories of understanding.
Are state-space models actually better than Transformers, or is this just hype?
The honest answer is: better at some things, not clearly better overall, and the full picture is still emerging. State-space models like those in the Mamba family demonstrate well-documented advantages in computational efficiency for long sequences — scaling linearly rather than quadratically with sequence length, which is a real and meaningful difference for applications involving long documents, continuous data streams, or edge deployment. In language modeling benchmarks at moderate scales, SSMs have shown competitive results with Transformers. Where the evidence is more mixed is in tasks requiring complex multi-step reasoning, precise retrieval from earlier in a long context, and performance at the very largest model scales — areas where Transformer architectures have had years of optimization and hardware co-design. The most intellectually honest framing is that SSMs have expanded the Pareto frontier: they offer a genuinely attractive trade-off for a specific set of use cases, rather than being universally superior. Hybrid architectures that combine SSM recurrence with selective attention are currently the most actively developed direction, and they may end up being more practically significant than pure SSMs. This is an active research area, and conclusions drawn today may look different in 18 months.
What is catastrophic forgetting and why has it been so hard to solve?
Catastrophic forgetting is the phenomenon where a neural network, when trained on new data or a new task, degrades significantly on tasks it previously performed well. The underlying cause is that neural networks store knowledge diffusely across their weight matrices — there’s no clean separation between “Spanish knowledge” and “French knowledge,” for instance. When gradient descent optimizes the network for new inputs, it moves weights in directions that improve performance on the new data while potentially disrupting the configurations that encoded older knowledge. Solving this is hard for several reasons. The interactions between weights are complex and non-linear, making it difficult to identify which weights are truly “important” for a given task. Importance estimates tend to be approximate. Replay methods — storing and periodically revisiting examples from previous tasks — work reasonably well but raise questions about storage cost and, in sensitive domains, data retention. Architectural approaches that partition capacity between old and new tasks work but can hit capacity limits over long learning sequences. The difficulty is compounded at large model scales, where the sheer number of parameters makes precise importance estimation computationally demanding. Current research generally suggests that combining multiple approaches — some regularization, some replay, some architectural scaffolding — is more effective than relying on any single technique.
Is neuroplasticity in AI actually like neuroplasticity in the brain, or is that just a metaphor?
It’s very much a metaphor, and it’s worth being careful about how far you extend it. The term “neuroplasticity” in neuroscience refers to the brain’s ability to reorganize its synaptic connections in response to experience — strengthening frequently used pathways, pruning unused ones, and forming new connections. Some of the mathematical intuitions from neuroscience have genuinely influenced AI research: the Elastic Weight Consolidation approach was explicitly inspired by the concept of synaptic consolidation, for example. But the mechanisms are quite different. Biological neurons are analog, operate with complex electrochemical dynamics, and exist within a physical structure that constrains their connectivity in specific ways. Artificial neural networks are mathematical abstractions — differentiable functions optimized through gradient descent. The analogy is useful as a source of research intuitions and as a way of framing problems, but it breaks down quickly if you push on the details. AI researchers who invoke “neuroplasticity” are usually gesturing at the general property of being able to update knowledge without erasing old knowledge — not claiming a deep mechanistic equivalence with how biological brains work.
How do adaptive AI systems affect reliability and trust in production deployments?
This is one of the most important and underappreciated questions in the space. A static model, whatever its flaws, is at least predictable in a specific sense — it behaves the same way today as it did when you validated it. An adaptive model that updates over time introduces a new class of risk: the system you’re deploying may not be the system you tested. This is a genuine concern in high-stakes domains like healthcare, financial services, and legal applications. The regulatory environment hasn’t fully caught up — frameworks for validating and auditing continuously learning systems are still being developed, and the absence of clear standards creates uncertainty for both deployers and users. That said, the alternative — static models that become increasingly outdated in fast-moving domains — has its own reliability problems. The research community is increasingly focused on monitoring and evaluation frameworks specifically designed for adaptive systems: approaches that track distribution shift, flag anomalous adaptation patterns, and provide interpretability into what a model has recently “learned.” This is likely to be a significant area of practical development over the next few years, and it’s a precondition for adaptive systems gaining serious adoption in regulated industries.
What does this mean for everyday AI tools like writing assistants or coding tools?
For most everyday users, the near-term practical impact is likely to show up in the form of better personalization and less need to re-explain context. The frustration of having an AI writing assistant that doesn’t remember your preferred tone, or a coding assistant that doesn’t recognize your project’s conventions, is something that continual learning approaches directly address. You’re already seeing early versions of this in tools that offer persistent memory or project-aware context — the question is how deep and reliable that adaptation becomes over time. The shift from static models to adaptive systems also means that the “version” of an AI tool you’re using in three months may genuinely be different from what you’re using today, in ways that go beyond a patch update. That has implications for how you think about workflows built around these tools — the behavior you’re counting on may shift. This isn’t necessarily bad, but it does mean paying closer attention to how specific tools handle model updates and whether they communicate changes to users clearly. The Physical AI and Agentic Systems piece touches on related themes around how AI behavior evolves in deployment contexts.
How does retrieval-augmented generation (RAG) relate to continual learning — are they solving the same problem?
They’re solving related but distinct problems, and in practice they’re often complementary rather than competing. RAG — retrieval-augmented generation — addresses the knowledge currency problem by giving a model access to an external knowledge base that can be updated independently of the model’s weights. You don’t change the model; you change what it can look up. This is powerful and has seen wide adoption because it’s relatively straightforward to implement and doesn’t carry the risks of modifying model weights in production. Continual learning, by contrast, actually updates the model’s internal parameters — the aim is for the model to genuinely internalize new knowledge, not just retrieve it from an external store. The practical difference matters for tasks that require deep integration of new knowledge with existing reasoning capabilities, rather than just fact retrieval. RAG is better at providing access to specific, structured, retrievable information. Continual learning is more relevant when you want the model to develop new skills or adapt its behavior patterns based on accumulated experience. In production systems, you’re increasingly likely to see both: RAG for fast, accurate knowledge retrieval, and continual fine-tuning for slower, deeper behavioral adaptation.
Is 2026 actually a turning point, or is this incremental progress being oversold?
A fair challenge, and worth taking seriously. The history of AI is littered with “turning point” declarations that turned out to be premature. The honest assessment is that 2026 represents genuine, meaningful progress on problems — catastrophic forgetting, long-context efficiency, real-time adaptation — that have been recognized as fundamental limitations for years. The research has moved from mostly theoretical to increasingly applied, and some production systems are incorporating these advances in ways that deliver real value. But “turning point” suggests a cleaner break than the evidence supports. Catastrophic forgetting isn’t solved; it’s being managed better in specific settings. SSMs are a real architectural advance, but they haven’t displaced Transformers and may not at scale. Adaptive systems in high-stakes domains are still navigating regulatory and validation challenges that don’t have clear resolutions yet. The more accurate framing is probably: 2025-2026 is the period when the research results from 2021-2024 started materializing into practical deployment advances, and that matters — but it’s the beginning of a transition, not the completion of one. Anyone telling you the fundamental problems are solved is getting ahead of the evidence.
The Bigger Picture: From Static Snapshots to Living Systems

The thread running through all of this — continual learning, state-space models, adaptive personalization — is a shift in what we expect AI systems to be. The dominant mental model of the last several years has been: you train a model, you deploy a model, and then you maintain a model by periodically retraining it on newer data. The model is fundamentally a static artifact, updated in discrete jumps.
What’s emerging is a different paradigm: AI as a system that develops over time through use, rather than a product that’s finished at deployment. That’s both more powerful and more complicated. More powerful because systems that learn from deployment experience can genuinely improve in ways that pre-training can’t fully anticipate. More complicated because the evaluation, governance, and trust frameworks built around static models don’t straightforwardly apply to adaptive ones.
The research community is ahead of the tooling and regulatory community on this. The technical progress on continual learning and efficient architectures is real. The frameworks for deploying, auditing, and trusting systems that change over time are less mature. That gap is probably the most important thing to watch over the next few years — not the benchmark scores, but whether the infrastructure for responsibly deploying adaptive AI catches up with the capability to build it.
If I were betting, I’d say the next wave of genuinely impactful AI development isn’t going to be the model that scores highest on a static evaluation suite. It’s going to be the system that’s still reliably useful a year after deployment because it’s been learning the whole time — and that we can actually verify is learning the right things. We’re not there yet. But the distance to there is measurably shorter than it was two years ago, and that’s worth paying attention to.
Last updated: 2026
Explore more AI tools
👉 Browse the AI Tools Library to find the right tools for your workflow.
Related reading: Emoji Finder Tools Explained: How AI Sentiment Analysis and Context Understanding Recommend the Right Emoji