The “It Can Already Do That” Misconception
Here’s a take you’ll hear constantly in 2026: “AI can basically act as an agent already — look at ChatGPT, it browses the web, runs code, calls tools. What more do you need?” It’s a reasonable-sounding argument. It’s also missing the point by a considerable margin.
The assumption behind it conflates tool access with agency. And that conflation matters enormously — not just philosophically, but practically, if you’re deciding whether to deploy an AI agent in a real business workflow. A model that calls a search API when asked isn’t doing the same thing as an agent that sets its own subgoals, monitors whether they’re succeeding, and re-routes when something breaks. The difference between those two things is the difference between a very capable assistant and a genuinely autonomous system — and for most real-world deployments, we’re firmly in the first category.
The hype cycle around “agentic AI” has moved faster than the underlying capability curve. Labs are shipping frameworks, startups are building platforms, and investors are writing checks — all based on a vision of AI that autonomously handles complex, multi-step tasks end-to-end. Some early use cases genuinely work well. Many don’t. This piece digs into what the research actually says, where the architecture stands today, and what the honest limitations are before you build your workflow around one of these systems.
What Actually Separates an Agent from a Chat Model
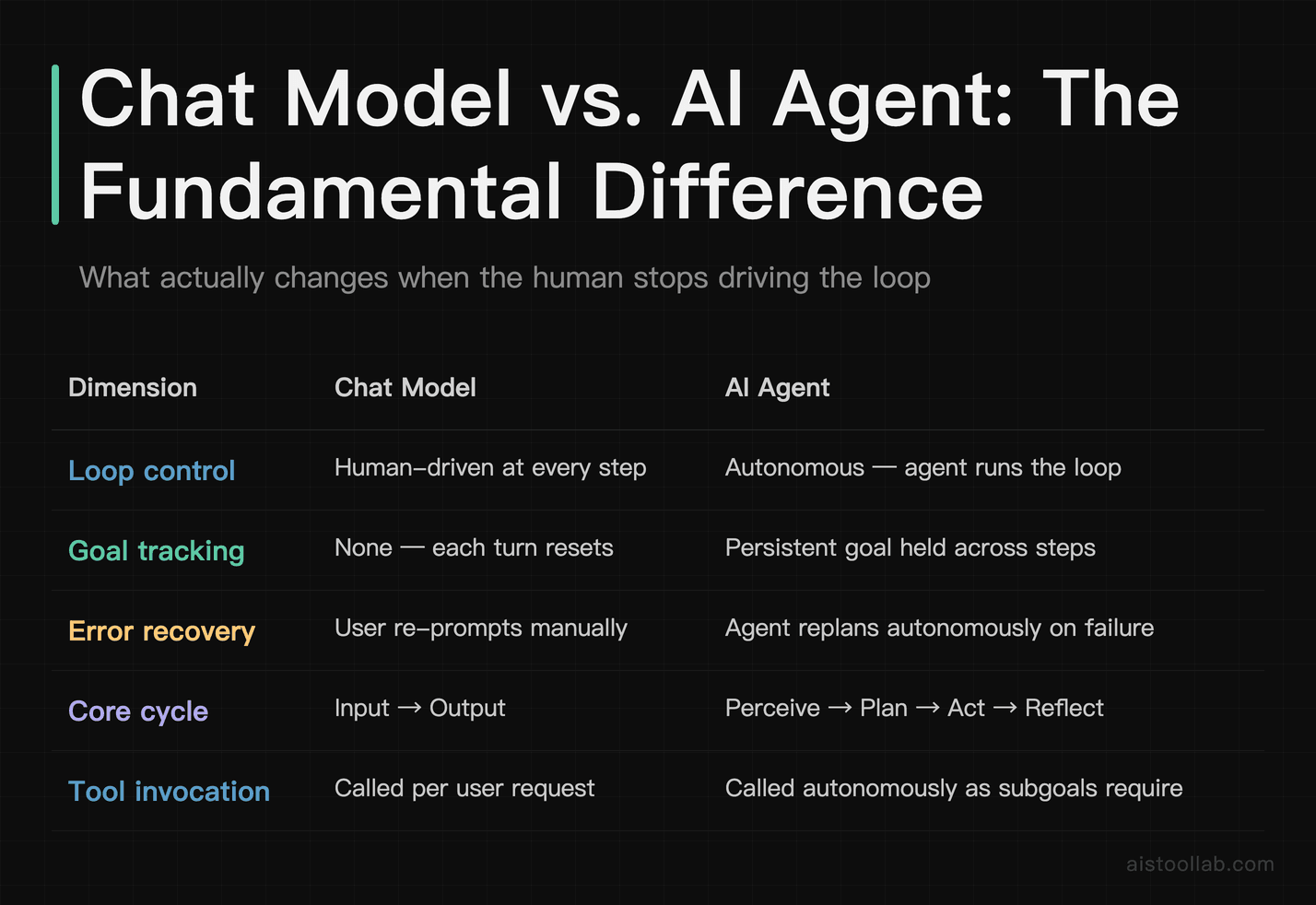
Let me make this concrete. A chat model — even a very capable one — operates primarily as a function: input goes in, output comes out. Even when you add tool calls, the basic contract is the same: the user drives the loop. The model responds, the user evaluates, the user follows up. There’s no persistent goal-tracking, no autonomous replanning if step 3 fails, no decision to go back and redo step 2 because the results from step 3 indicate the earlier output was wrong.
An AI agent changes this contract fundamentally. The agent holds a goal — given explicitly or decomposed from a higher-level objective — and runs an autonomous loop to pursue it. The core loop, often described in research as a Perceive → Plan → Act → Reflect cycle, works roughly like this:
- Perceive: Observe the current environment — read the file, check the API response, look at the state of the webpage.
- Plan: Decide what action to take next, given the goal and what’s been observed so far.
- Act: Execute the action — call the tool, write the code, send the message.
- Reflect: Evaluate whether the action produced the expected result. If not, update the plan.
The memory architecture underpinning this loop is also qualitatively different from a chat session. Agents typically operate with multiple memory layers: the immediate context window (working memory), a structured log of actions taken in the current session (episodic memory), and often an external persistent store — a vector database, a file system, a relational database — that lets the agent retrieve relevant context across sessions. Without persistent memory, an “agent” is just a chat model running in a loop, which explains a lot of the early failures people encountered with the original AutoGPT-style tools.
Multi-agent systems take this further by running multiple specialized agents in parallel or in sequence, with one orchestrator agent coordinating the others. You might have a planner agent, a research agent, a coder agent, and a reviewer agent all working on different parts of a task. This architecture is genuinely promising for complex workflows — but it multiplies the failure surfaces too. More agents means more opportunities for one bad output to corrupt the whole pipeline.
How AI Agents Stack Up: A Framework Overview
What the Research Actually Says

One of the most influential frameworks in AI agent research came from a 2022 arXiv paper by Yao and colleagues from Google and Princeton: ReAct (Reasoning and Acting). The core insight was that interleaving reasoning traces with action steps — rather than treating them as separate processes — dramatically improved an agent’s ability to stay on track in multi-step tasks and self-correct. Before ReAct, the dominant approach was either pure chain-of-thought reasoning (thinking without acting) or pure action sequences (acting without explicit reasoning). The interleaved pattern proved meaningfully better at handling conditional logic, recovering from unexpected tool outputs, and staying anchored to the original goal. Most production agent frameworks today — including LangChain’s agent executor — are built on variants of this pattern.
Building on that foundation, the Reflexion framework (Shinn et al., arXiv 2023) introduced verbal reinforcement: after each task attempt, an agent generates a textual self-reflection on what went wrong and stores it as context for future attempts. On coding and reasoning benchmarks, agents with Reflexion-style self-evaluation outperformed single-pass agents on debugging tasks — though results varied by task complexity. The point wasn’t just “more attempts equals better outcomes” but that structured self-critique, stored in memory, meaningfully shapes subsequent attempts. It’s the closest current analog to how a skilled human learns from failure during a complex task.
The Tree of Thoughts paper (Yao et al., Princeton and Google, 2023) pushed planning further by framing reasoning as a search through a tree of possible reasoning paths, rather than a linear chain. This matters for tasks where the right path forward isn’t obvious and backtracking is necessary — a basic competency for any agent handling real-world complexity. The research showed improvements on mathematical reasoning and planning puzzles, though the computational cost is substantially higher than standard chain-of-thought approaches.
Perhaps the most sobering research for those bullish on current agents comes from real-world evaluation benchmarks. WebArena (Zhou et al., Carnegie Mellon University and collaborators, 2023) built a realistic benchmark of web-based tasks — the kind of things a human assistant handles daily — and tested leading models against it. Even the best-performing models at publication time struggled to complete the majority of tasks successfully. More recent evaluations on similar benchmarks have shown progress, but the gap between demo performance and real-world reliability on open-ended tasks remains a consistent finding across independent research groups.
On the reasoning depth front, OpenAI’s o1 and o3 model families represent an architectural shift — using extended internal chain-of-thought before generating a final response. OpenAI’s official technical documentation reports meaningful improvements on math, coding, and scientific reasoning benchmarks compared to earlier models. Anthropic has published similar findings for extended reasoning modes. The implication for agents is significant: deep reasoning capability appears to be necessary, though not sufficient, for reliable agentic behavior. A fast, shallow-reasoning model fails at planning; a deep-reasoning model can plan better but costs more per agentic step — a real tradeoff for anyone running long task chains at scale.
Three Real-World Scenarios Where Agents Are Being Tested Today

The Solo Developer Managing Multiple Client Codebases
A freelance developer juggling three client projects — different tech stacks, different deployment pipelines — is a natural early fit for coding agents. Tools built on frameworks like LangChain or integrated directly into IDEs can be tasked with things like “scan the repo for deprecated dependencies, check current package versions, and generate a migration plan.” The agent calls shell tools, reads files, checks npm or PyPI, and produces an actionable output without the developer spending an afternoon doing it manually. Where it works, it works well. Where it breaks is when the repo has unusual structure, the agent misinterprets a dependency chain, and confidently generates a migration plan that would break the build. The developer who runs it without reviewing still has a half-day of debugging ahead. Agentic coding assistance is genuinely useful for well-scoped, well-defined tasks — and for a broader look at where coding tools currently stand, the Best GitHub Copilot Alternatives in 2026: 6 AI Coding Tools Compared review covers the landscape.
The Two-Person Marketing Team Running Research-Heavy Campaigns
A small SaaS startup with a lean marketing team spends hours each week on competitive research — reading blog posts, scanning pricing pages, tracking what competitors are shipping. An agent configured with web access, structured output tools, and a research template can handle a significant chunk of this: searching, reading, extracting key data points, and writing a structured brief. The time savings are real. The limitation is accuracy and freshness: agents can hallucinate details about competitor products, miss paywalled content, and struggle with sites that actively block scraping. Treating the output as a first draft to verify — rather than a finished deliverable — is the right operating model here. For research-heavy roles, the Best AI Tools for Students and Researchers in 2026 article covers the broader tooling context.
The Enterprise IT Team Piloting Automated Incident Response
This is where the stakes escalate significantly. Some enterprises are running pilots where an AI agent monitors system alerts, diagnoses probable causes based on log data and historical incidents, and either resolves the issue autonomously for known patterns or escalates with a structured diagnosis report. The appeal is obvious — nobody wants to wake up a senior engineer at 3am for what turns out to be a routine cache flush. The reality is these systems require careful guardrails: the agent needs strict limits on which actions it can take autonomously, the escalation thresholds need to be tuned conservatively, and failure modes — an agent “fixing” one problem in a way that creates a worse one — need to be explicitly tested. The pilot programs in industry coverage I’ve followed tend to operate in “suggest and confirm” mode rather than full autonomy, which is almost certainly the right call for anything touching production systems.
The Limitations Nobody Talks About Enough
The failure modes of current AI agents aren’t minor footnotes — they’re the primary reason most “agentic” products today are either narrowly scoped or require constant human supervision.
Hallucination compounds over steps. In a single chat turn, a hallucinated fact is annoying but recoverable. In a multi-step agent, a hallucination in step 2 becomes the input to step 3, which builds on it, and by step 7 you have a confidently-executed plan built on a false premise. Research on long-horizon task completion consistently finds that error rates don’t add linearly — they compound. The longer the task chain, the higher the probability of at least one critical failure corrupting the final output.
Planning is brittle under novel conditions. Agents perform reasonably on familiar task types but degrade sharply when placed in slightly unfamiliar environments — an API that returns an unexpected format, a webpage with an unusual layout, a goal with an ambiguous dependency. Tree of Thoughts and related approaches raise the ceiling, but they don’t solve the underlying problem: current models generalize planning heuristics, not genuine world models. Novel situations expose this gap quickly.
Real-world reliability remains an open problem. The gap between benchmark performance and actual production performance has been documented repeatedly across AI systems. Agents, with their longer action chains and broader tool access, face a wider version of this gap than chat models do. Until evaluation on diverse, realistic task sets shows substantially more consistent results, treating agents as production-ready for open-ended, unstructured workflows carries meaningful operational risk.
If you want to go deeper on the systems-level mechanics of how agents manage these challenges, the Agentic AI Systems Explained: How AI Agents Actually Think, Plan, and Execute Complex Tasks piece covers the internal architecture in more detail.
Frequently Asked Questions
What’s the practical difference between an AI agent and a chatbot that has tool access?
This is the most common source of confusion in the field right now, and precision matters here. A chatbot with tool access — like a GPT-4-class assistant that can run code or search the web — still operates within a fundamentally human-driven loop. The human sends a message, the model decides to call a tool, the result comes back, the model responds, and the human decides what to ask next. The model isn’t tracking a goal across that exchange; it’s responding to each prompt in isolation, effectively starting fresh each turn.
An AI agent, properly defined, runs its own loop. It receives a goal — “research and summarize the top five competitors in the B2B CRM market and produce a formatted report” — and then autonomously decides what steps to take, in what order, calling tools as needed, evaluating whether intermediate results are satisfactory, and continuing until the goal is achieved or it determines it can’t proceed without input. There is no human prompt at each step. The human checks back in at the end — or at defined checkpoints — rather than driving each turn. This distinction matters enormously for how you design guardrails, set expectations, and manage the risk profile of what you’re deploying.
Are current AI agents reliable enough to use in production without supervision?
The honest answer: it depends heavily on the task, and for most complex, open-ended tasks, the answer is not yet. Reliability degrades with task complexity and chain length. For narrow, well-scoped tasks — classify these support tickets, extract these fields from these documents, check these URLs for broken links — agents can perform quite reliably and the economics often justify it. For open-ended tasks with many branching decisions and dependencies on external systems, the failure modes multiply quickly.
The research literature on this is consistent: performance on isolated benchmarks doesn’t translate cleanly to performance in production on real user tasks. Most serious deployments today either operate in a “suggest and confirm” model where a human approves key actions, or they constrain the agent to a very narrow decision space. “Fully autonomous agents handling complex, unstructured business workflows” is currently more a roadmap item than a shipping product for most organizations. Reflexion-style self-correction and extended reasoning models have genuinely raised the capability ceiling — but the floor on reliability for complex tasks is still lower than many marketing materials suggest. Build in checkpoints and don’t skip the testing phase.
What is the ReAct framework and why do researchers keep referencing it?
ReAct stands for Reasoning and Acting, from a 2022 arXiv paper by Yao and colleagues at Google and Princeton. The insight was deceptively simple: rather than separating reasoning (generating a chain of thought) from acting (calling a tool), you should interleave them. An agent using ReAct generates a thought — “I need to check the current exchange rate before calculating this” — then takes an action (call the currency API), then observes the result, then generates another thought informed by that result, and so on through the task.
Before ReAct, the common approach was either pure chain-of-thought (reasoning without acting) or pure action sequences (doing things without intermediate reasoning traces). The interleaved approach proved significantly better at catching errors early, staying on track when tools returned unexpected results, and completing multi-step tasks requiring conditional logic. It also made agent behavior substantially more interpretable — you can read the thought-action-observation trace and see exactly where things went wrong, which is invaluable for debugging. Most modern agent frameworks, including LangChain’s agent loop and many proprietary implementations, are built on ReAct variants. Understanding it is essentially a prerequisite for understanding how production agents are designed today.
How do multi-agent systems differ from single-agent setups, and when does the added complexity actually pay off?
A single agent handles all steps of a task itself, with one language model orchestrating the full loop. A multi-agent system distributes work across multiple specialized agents coordinated by an orchestrator. A typical setup might have a planner agent that breaks down the goal, a research agent that gathers information, a writer agent that drafts the output, and a critic agent that reviews and suggests revisions — all working in sequence or in parallel.
The benefit is specialization and, where applicable, parallelism. A coding-specialized agent can be tuned and prompted for code tasks in ways a general agent isn’t, potentially producing better results on that subtask. Parallel execution can significantly reduce wall-clock time when task components are independent. The downside is coordination complexity: inter-agent communication needs to be structured, errors in one agent can corrupt downstream agents, and debugging a multi-agent failure is substantially harder than debugging a single agent. The added complexity generally pays off for genuinely large, parallelizable tasks — complex software projects with clearly separated modules, research synthesis across dozens of documents, or enterprise workflows with distinct specialist steps. For most individual users and small teams, a well-designed single agent is simpler, more debuggable, and usually adequate.
What are the biggest risk factors when deploying agents with real tool access?
The risk profile of AI agents is categorically different from chat models, and this deserves serious thought before deployment. The core issue is irreversibility: when a chat model gives a bad answer, you can ignore it. When an agent with tool access takes a bad action — sends an email, deletes a file, calls a paid API thousands of times, posts to a social media account — the consequences are immediate and sometimes hard to reverse.
The main risks in practice: hallucination-driven actions, where the agent acts on false premises it fabricated; scope creep, where the agent interprets its goal more broadly than intended and takes actions outside the intended boundary; prompt injection, where malicious content in external data — a webpage, an email — manipulates the agent into taking unintended actions; and compounding errors, where a wrong decision early in the task chain degrades everything downstream. Practical mitigations include limiting tool permissions to the minimum necessary for the task, requiring human confirmation before any irreversible action, sandboxing agents during development, and setting conservative budget limits on API call counts. The principle of least privilege applies to AI agents as much as it does to any software system — probably more so, given their unpredictability in edge cases.
Do I need to be a developer to use AI agents today?
Increasingly no — but the spectrum is wide and the tradeoffs are real. At the no-code end, tools like Zapier’s AI automation features, Microsoft Copilot Studio, and various visual agent builders let non-technical users set up multi-step automated workflows using drag-and-drop interfaces. These are genuinely accessible to marketers, operations managers, and solopreneurs. What they trade off is flexibility: you’re working within the constraints of what the platform supports, and the agentic behaviors available are relatively constrained compared to what you can build in code.
At the code-friendly end, frameworks like LangChain, LlamaIndex, CrewAI, and Microsoft’s AutoGen give developers granular control over agent behavior, tool configuration, memory management, and multi-agent orchestration. These have gotten significantly more accessible over the past couple of years — better documentation, active communities, extensive example notebooks — but they still require comfort with Python and API integrations. For most non-developers today, the best path is a managed platform that abstracts away the infrastructure while offering meaningful configurability. The tooling landscape is evolving fast enough that the no-code options are gaining capability month by month, making the barrier to entry meaningfully lower than it was even twelve months ago.
Which AI labs are leading agent research, and what are they focused on?
The main research fronts span several institutions. OpenAI has invested heavily in extended reasoning through the o-series models, with the argument that deep chain-of-thought is a prerequisite for reliable agentic behavior. Anthropic has published research on model behavior and alignment challenges in agentic contexts — their Constitutional AI work has direct implications for keeping agents within intended boundaries when operating autonomously. Google DeepMind is active on multi-step reasoning and planning, with research spanning both prompting-based and training-based improvements to agent reliability.
On the academic side, Carnegie Mellon, Princeton, Stanford, and MIT have produced significant agent-related work — including benchmark development (WebArena from CMU), novel reasoning frameworks, and evaluation methodologies for assessing agents on realistic tasks. Microsoft Research has been deeply involved in multi-agent system design and produced the AutoGen framework, which has become a reference implementation for orchestrated multi-agent workflows. The open-source community around LangChain, LlamaIndex, and CrewAI has also generated substantial practical knowledge about what works in real deployments. The overall research direction across all these groups is converging on the same hard problems: reducing hallucination in long action chains, improving planning generalization, and closing the benchmark-to-production reliability gap.
What’s the relationship between reasoning models like o1/o3 and agentic AI — aren’t they the same thing?
They’re closely related but architecturally distinct. Reasoning models like OpenAI’s o1 and o3 use an extended internal chain-of-thought process before generating a final response — the model “thinks for longer” before answering, producing better results on tasks requiring complex multi-step inference. This is a capability enhancement at the individual inference level: one call in, better answer out. Agentic behavior, by contrast, is an architectural pattern — the loop of perceive, plan, act, and reflect over time, using external tools, with goal persistence across multiple inference calls.
The connection is that deeper reasoning capability appears to be necessary but not sufficient for reliable agency. A model that reasons shallowly will make planning errors and fail to self-correct effectively; a model with extended reasoning has a meaningfully higher ceiling for planning quality. But you still need the agentic loop, the tool integrations, the memory architecture, and the error-handling logic on top of that reasoning capability to get actual agentic behavior. OpenAI, Anthropic, and others are building agentic systems on top of their strongest reasoning models precisely because planning quality correlates with reasoning quality — but swapping a better reasoning model into a poorly designed agent architecture won’t automatically fix the architectural problems. The two dimensions — model capability and agent design — both matter, and the field is working on both simultaneously.
Where This Is All Going — And Where It Actually Is Right Now

If you’re a developer or technical product manager, I’d argue you should be experimenting with agent frameworks right now. Not because the technology is fully ready for every use case, but because the learning curve is real and the capability trajectory is steep. The organizations that understand agents’ actual capabilities and actual failure modes today will be positioned to use them responsibly when the reliability bar rises.
If you’re a business owner or team lead evaluating whether to deploy an agent in a critical workflow, the advice is different: be specific about the task scope, narrow the initial deployment to well-defined and ideally reversible actions, build in human checkpoints, and assume you’ll iterate before it runs reliably without supervision. The research foundation — ReAct, Reflexion, extended reasoning, multi-agent coordination — is real and meaningful. The gap between lab results and production reliability on complex open-ended tasks is also real. The practitioners getting genuine value out of agents today are the ones who’ve taken both of those things seriously at the same time.
Last updated: 2026
Explore more AI tools
👉 Browse the AI Tools Library to find the right tools for your workflow.