「AI 真的在推理,還是只是很會猜?」
這個問題我被問過很多次,在讀者信箱裡、在社群討論串裡、甚至是在喝咖啡的時候朋友突然問起。每次我都沒辦法給一個乾淨的答案——不是因為我不懂,而是因為這個問題本身就在快速變化中。
但 2026 年有點不一樣了。這一年,幾件事同時發生:模型的推理能力出現了可量化的質變、長文件處理從「能用」變成「好用」、「知道自己不知道」這件事開始被認真當作工程問題來解。如果你還停留在「AI 就是個比較聰明的自動完成」的印象,這篇文章可能會讓你重新評估一下。
我會從研究數據切入,把這一年最值得關注的幾個技術方向梳理清楚,不賣弄術語,但也不刻意簡化。畢竟讀這篇文章的你,應該想要的是真正搞懂,而不是看完一堆「AI 好厲害」的廢話。
編碼能力的量化對決:數字背後在說什麼
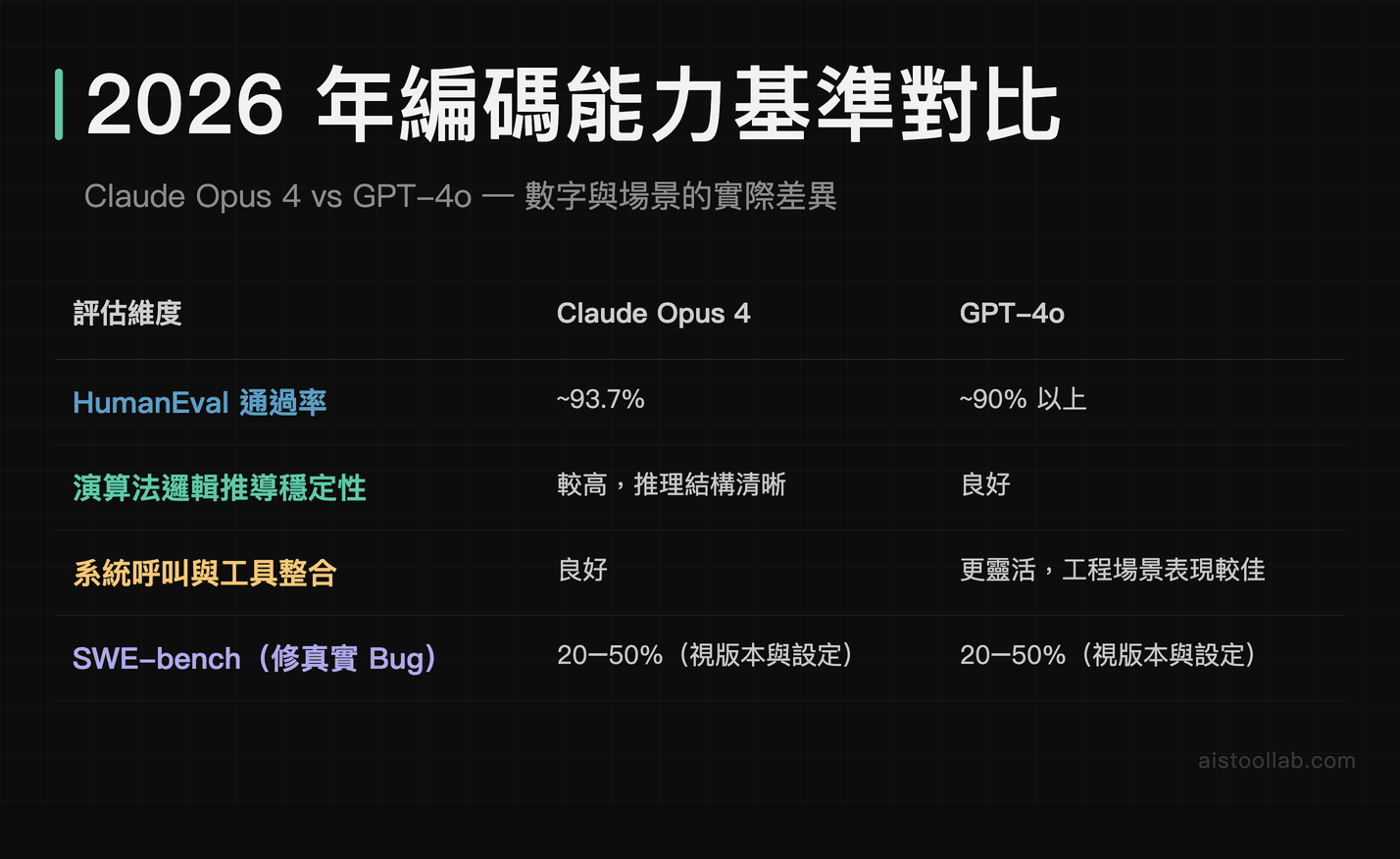
先說編碼能力,因為這個領域有最多可以量化的基準測試,也是 2026 年模型能力分化最明顯的戰場。
HumanEval 是目前最廣泛引用的程式碼生成評估基準,由 OpenAI 設計,包含 164 個 Python 程式題,測試模型能不能根據函數說明直接生成正確的程式碼。根據 Anthropic 官方公開資料,Claude Opus 4 系列在 HumanEval 上的表現達到 93.7% 左右的通過率,這個數字放在 2023 年是不可想像的——當時 GPT-3.5 在同一個基準上大約只有 48% 左右。
GPT-4o 的表現在 OpenAI 官方技術報告與第三方測試中,通常落在同一個級距(90% 以上),差距並不是「一方碾壓另一方」,而是在不同類型的題目上各有所長。目前研究社群的普遍觀察是:Claude 在需要清晰邏輯推導的演算法題上稍微更穩定;GPT-4o 在涉及系統呼叫、工具整合的實際工程場景下更靈活。但我要誠實說一句:這個差距在日常使用中其實不容易感受到,HumanEval 畢竟是一個相對乾淨的測試環境,真實的程式任務複雜得多。
更值得關注的是 SWE-bench 這個基準——它測的是模型能不能真的修 GitHub 上的 Bug,而不是解一道設計好的程式題。這個基準的難度高很多,各家模型的通過率普遍在 20-50% 之間(視版本和設定方式而異),這個落差才反映了「會解題」和「能真正寫程式」之間的真實距離。
對台灣的工程師讀者來說,這個數字的實際意義是:用 AI 輔助寫基本的函數、自動生成測試案例、重構小段程式碼,現在的準確率已經高到值得信任;但要讓 AI 獨立完成一個有複雜依賴關係的功能模組,還是要有人在旁邊把關。
使用情境:誰真正會從這些技術進展中獲益
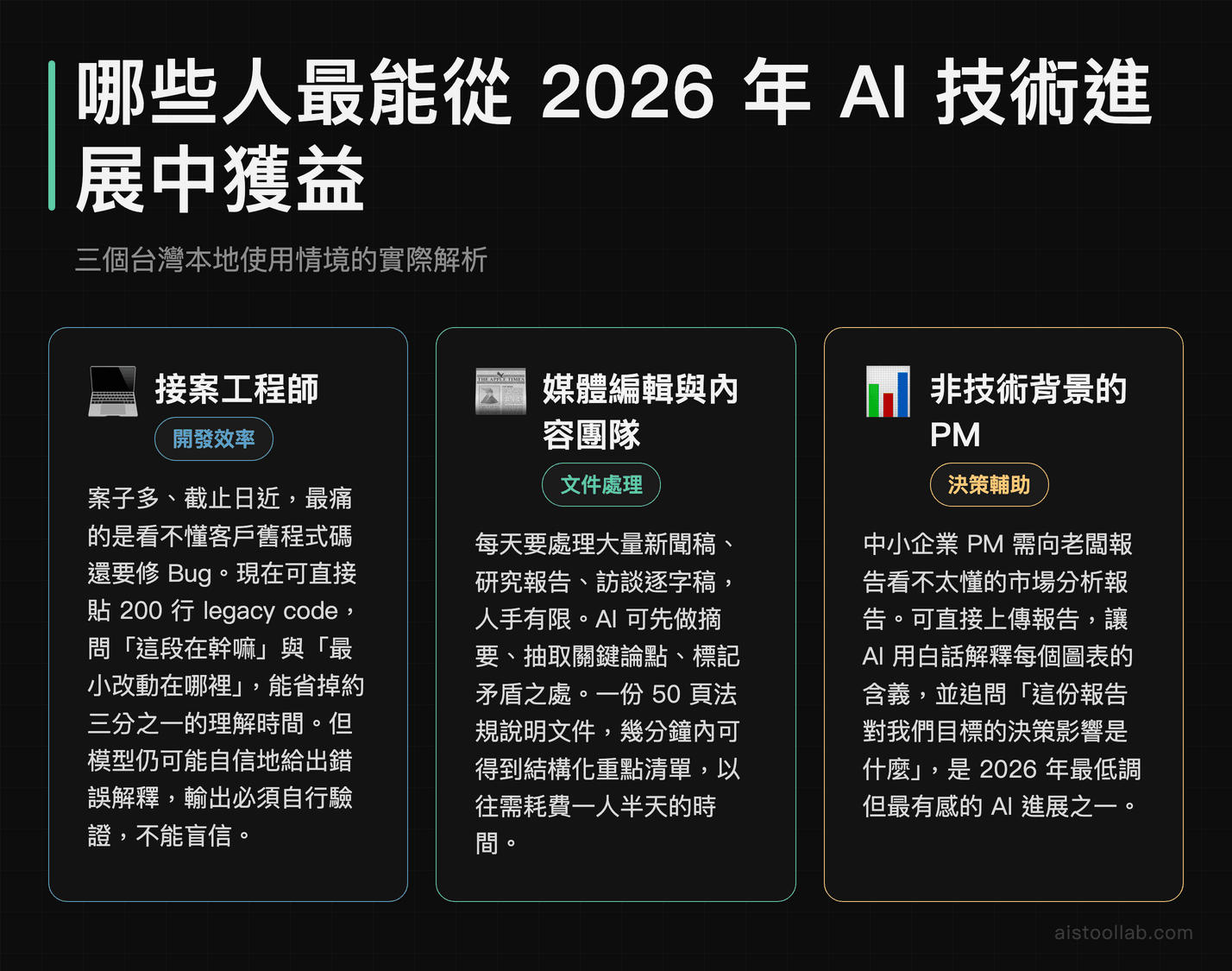
情境一:接案工程師,用 AI 壓縮除錯時間
台灣有不少接案工程師,案子多、截止日近,最痛的不是寫新功能,而是看不懂客戶交過來的舊程式碼然後要修 Bug。2026 年的模型在「解釋一段陌生程式碼的邏輯」這件事上已經非常實用——你可以直接貼上 200 行的 legacy code,問它「這段在幹嘛」以及「如果我要改這個行為,最小改動是哪裡」。根據我自己的使用經驗,這個工作流能省掉大概三分之一的理解時間。但要注意:模型偶爾會自信地給出錯誤的解釋,所以輸出結果一定要自己驗證,不能盲信。
情境二:媒體編輯與內容團隊,處理大量長文件
台灣的數位媒體團隊現在面臨的真實挑戰是:資訊量爆炸、人手有限、每天要處理大量的新聞稿、研究報告、訪談逐字稿。2026 年模型的長文件處理能力讓這個流程發生了實質改變——不是讓 AI 寫文章(品質仍然需要人類編輯),而是讓 AI 先做摘要、抽取關鍵論點、標記矛盾之處。一個 50 頁的法規說明文件,現在可以在幾分鐘內得到一個結構化的重點清單,這在以前要花一個人半天的時間。
情境三:沒有數據科學背景的 PM,需要解讀分析報告
這是一個很台灣的場景:中小企業的 PM,需要向老闆報告一份自己看不太懂的市場分析報告。過去他們要嘛請教工程師、嘛就硬著頭皮猜。現在可以直接上傳報告,讓 AI 用白話文解釋每個圖表的含義,並且問「如果我們的目標是 OO,這份報告對我們的決策影響是什麼」。這類「讓不同背景的人讀懂專業文件」的應用,是 2026 年 AI 工具最低調但最有感的進展之一。
長文件處理:從「塞進去不崩潰」到「真的讀懂」

2024 年之前,「長文件支援」基本上是個噱頭。理論上模型可以接受很長的輸入,但實際測試會發現:把一份 80 頁的合約塞進去問問題,模型很容易忽略文件中間的部分、把不同段落的內容混在一起、或者對矛盾的條款視而不見。
這個問題有個技術名稱叫做「lost in the middle」,史丹佛大學的研究者在 2023 年發表的論文中記錄了這個現象:語言模型在處理長文件時,對文件開頭和結尾的內容注意力顯著高於中間部分,這在實際應用中會造成很嚴重的遺漏問題。
到了 2026 年,這個問題有了實質改善,但並沒有完全消失。主要的進展來自幾個方向:
- 注意力機制的改進:新一代模型在架構層面優化了對長序列的注意力分配,讓「中間段落遺漏」的比例下降
- 檢索增強生成(RAG)的成熟:不是把整份文件塞給模型,而是先用向量搜尋找出最相關的段落,再讓模型針對這些段落回答問題
- 結構化輸入的運用:訓練模型理解文件的層級結構(章節、標題、段落),而不是把所有文字當成同質的序列
但我要說一個大家不太想聽的現實:即使是 2026 年最好的模型,在處理超過 100 頁、邏輯高度複雜的文件時(例如法律合約或技術規格書),仍然存在細節遺漏的風險。用 AI 來加速摘要和導覽是合理的,但用 AI 來做最終的合規審查,在目前的技術水準下仍然不夠可靠。
2026 年的比較表格:主流模型的能力分化全貌
表格的數字我盡量只放有公開依據的,推理能力和中文品質這類主觀維度,用的是描述而不是分數,因為我不想給你一個假精確的數字。如果你想深入了解各模型在企業場景的選型建議,可以參考2026年AI工具企業應用決策指南:從選型到落地的完整評估框架,那篇從商業角度切入,和本文的技術角度互補。
安全對齊的真正突破:「知道自己不知道」

這是 2026 年我認為最被低估的技術進展,沒有之一。
過去幾年,AI 模型最危險的問題不是會說壞話,而是說錯話的時候太有自信。模型會把幻覺包裝成確定的事實、把猜測說成知識、把過時的資訊當作最新狀況——而且說的時候語氣肯定得像在背課本。這個問題叫做「過度自信的幻覺」(hallucination with overconfidence),是目前 AI 應用在高風險場景(醫療、法律、財務)最大的障礙。
2026 年的模型在這個維度上有了真實的改進,核心機制有幾個方向:
校準訓練(Calibration Training):訓練模型在回答問題時,讓表達的確定程度和實際的正確率一致。簡單說,如果模型只有 60% 把握,就應該說「我認為」而不是「確實是」。DeepMind 和 Anthropic 都在這個方向發表過相關研究,方向是真實的,但「完全解決」還差得遠。
Constitutional AI 與 RLHF 的持續優化:Anthropic 的 Constitutional AI 方法讓模型在生成回應之前,先對自己的輸出做自我評估,這在一定程度上能抓到「這個回答是否超出了我的知識範圍」的情況。
知識截止日的明確標示:這聽起來很簡單,但做得好不容易。新一代模型在涉及時效性資訊時,更頻繁地主動提示「我的資料只到 XX 年,最新情況請查閱外部來源」,而不是直接給一個可能過時的答案。
老實說,這個問題沒有被完全解決。我在測試中仍然能找到各家模型自信說錯的案例。但方向是對的,而且工程投入明顯加大了——這和 2023 年「幻覺是語言模型的本質,沒辦法」的悲觀論調比起來,已經是很大的轉變。
多模態:成為標配之後,真正的邊界在哪裡

2024 年底,多模態能力(同時理解文字和圖像)還算是一個賣點。到了 2026 年,你要找一個主流 AI 助理不支援圖像輸入,反而比較難。這個能力從「差異化功能」變成了「基本門票」。
但成為標配之後,真正重要的問題才浮現:這個能力的實際邊界在哪裡?
幾個我認為值得誠實討論的限制:
- 精細空間理解仍然不穩定:叫模型描述一張圖片的大致內容,現在表現很好。但如果是「這個圖表第三個柱子和第五個柱子差多少百分比」,精確性就開始下滑。對於資料視覺化的精確解讀,目前還是需要謹慎。
- 圖文推理的深度有限:可以看懂圖、看懂文字,但要做「根據這張工程圖找出設計問題」這類需要深度領域知識的圖像推理,目前仍然遠不如一個有經驗的人類專家。
- 影片理解仍是瓶頸:靜態圖像已經很能用了,但影片的逐幀理解、時間序列推理,目前大部分模型做得都還不夠好。這是多模態的下一個主戰場。
- 生成圖像的版權與來源問題:在台灣的商業使用場景,這個問題仍然沒有清晰的法律答案,企業使用要特別小心。
對台灣的設計師和內容創作者來說,多模態最實用的場景目前還是集中在「描述和分析既有圖像」,而不是「根據圖像做複雜決策」。如果你想知道各工具在不同場景的具體分工建議,這篇2026年AI工具實戰分工指南:為什麼用ChatGPT處理所有事情,效率只有50%有更細緻的比較。
能力分化的真實樣貌:哪個工具在哪個領域更好

有個觀察我覺得很重要,但很少人直接說:2026 年的主流 AI 模型,通用能力已經非常接近,真正的差異在特定領域的深度和穩定性。
根據目前可查閱的第三方評估(包括 LMSYS Chatbot Arena 的使用者偏好排行、Scale AI 等機構的評測報告方向,以及開發者社群的實際回饋),幾個相對有共識的觀察如下:
寫作與繁體中文:Claude 系列在長篇寫作的段落連貫性上表現較好,句子不容易突然變風格。GPT-4o 的繁體中文輸出穩定,但有時候在台灣習慣用語上會稍微偏書面化。兩者的繁體中文品質都比幾年前好很多,對大多數使用情境來說已經沒有明顯痛點。
程式碼:如前所述,頂級模型的差距在縮小。但在「搭配特定框架(例如 Next.js 或 FastAPI)的實際工程任務」上,GPT-4o 因為訓練資料和工具整合的關係,在開發者社群中的口碑稍微更好一些。Claude 在需要解釋推理過程的演算法討論上,回答的結構通常更清晰。
長程任務規劃(Agentic 能力):這是 2026 年最熱門也最混亂的戰場。各家都在推 Agent 功能,但實際的穩定性差異很大。目前的共識大致是:簡單的工作流自動化(查資料→整理→發報告)已經很能用;複雜的多步驟決策任務(需要根據中途結果改變策略)仍然需要人在迴路中。這個方向的技術進展很快,但我建議不要現在就把關鍵業務流程完全交給 AI Agent。
關於 Agent 工具的演進全貌,2026年AI工具代理時代全解析:從對話生成到自動執行的歷史性轉折這篇有很詳細的梳理。
常見問題
HumanEval 93.7% 是什麼意思?這代表 AI 能幫我寫程式嗎?
HumanEval 是一個包含 164 道 Python 程式題的標準化測試,93.7% 的通過率意思是:模型能正確解出其中大約 154 道題。但這個數字有幾個重要的脈絡需要了解。首先,HumanEval 的題目是設計過的、相對乾淨的演算法題,和實際工作中的程式任務有明顯差距——真實的程式碼有模糊的需求、複雜的依賴關係、不完整的文件。其次,「生成出來的程式碼通過測試」不等於「程式碼沒有潛在問題」,安全性漏洞或邊界條件的錯誤可能測試抓不到。對台灣工程師的實際建議:把 AI 當成一個「很快的實習生」——可以幫你起草、可以幫你解釋、可以幫你找常見錯誤,但輸出結果你還是要 review,不能直接推上 production。
繁體中文的支援現在到底夠不夠用?有沒有什麼場景還是會出問題?
整體來說,2026 年主流模型的繁體中文支援已經到了「日常使用不太會有明顯問題」的水準。GPT-4o 和 Claude 的繁體中文輸出穩定,不太會無故夾雜簡體字。但幾個場景仍然值得注意:一是台灣特有的用語或俚語,模型有時候會用大陸用語(例如「軟件」而不是「軟體」、「電子郵件」而不是「電郵」);二是需要理解台灣特定法規、地名、機構名稱的任務,模型可能沒有足夠的訓練資料而出現錯誤;三是涉及台灣本地新聞或近期事件的問題,知識截止日的限制會更明顯。總體建議:用繁體中文輸入和輸出沒問題,但涉及台灣特定情境時,輸出結果要多一層確認。
「知道自己不知道」這件事,現在的模型真的做到了嗎?如何判斷?
部分做到了,但遠未完成。目前最好的模型在被問到明顯超出知識範圍的問題時(例如詢問知識截止日之後發生的事),會比較頻繁地提示不確定性。但在「介於確定和不確定之間」的灰色地帶,模型仍然容易過度自信。判斷的實用方法:如果你問一個問題,模型給了一個非常具體的答案(特別是涉及數字、日期、人名),不妨追問「你對這個答案有多大把握?有什麼地方可能是錯的?」通常這個追問會讓模型更誠實地表達不確定性。另外,涉及醫療、法律、財務的問題,無論模型說得多有把握,都應該請專業人士複核——這不是技術問題,是判斷問題。
多模態能力在台灣的商業場景,有哪些真正實用的應用?
幾個我觀察到實際在用的場景:電商的商品圖片描述自動化(節省大量人工撰寫時間)、設計稿的文字標注和說明生成、報表截圖轉文字摘要(避免重新輸入數字)、招募時的履歷掃描(配合文字摘要)。比較不建議的場景:需要精確解讀的工程圖或技術圖表、醫療影像分析(完全不建議在沒有專業監督下使用)、法律文件中圖表的精確解讀。整體而言,多模態目前最實用的是「把視覺內容轉成文字描述」,而不是「對視覺內容做高精度的分析決策」。
這些模型的定價對台灣用戶來說划算嗎?免費版夠用嗎?
三大主流模型(ChatGPT Plus、Claude Pro、Gemini Advanced)的月費都在 NT$620-680 之間,年繳通常有 20% 左右的折扣。免費版能不能用?看你的使用量和深度。如果你每天只是偶爾問幾個問題,免費版的額度在大部分情況下夠用。但如果你想把 AI 工具真正整合進工作流程——例如每天處理多份長文件、跑多次程式碼生成、或使用進階功能如 Projects 和記憶功能——付費方案的額度和功能差距是真實存在的。我的建議:先用免費版玩一個月,確認你的使用習慣和需求,再決定要不要升級哪一家。不需要三家全訂,選一個主要工具深入用,效果遠好於三家都訂但都用得很淺。
AI 模型在「長程任務規劃」上的能力,現在真的可以信任嗎?
這是我被問最多次的問題之一,我的答案是:可以信任它完成有清晰結構的長程任務,但不能信任它獨立完成需要動態判斷的複雜任務。舉個具體的例子:讓 AI Agent 每天早上自動彙整三個指定新聞來源的摘要並寄 Email,這種流程結構清楚、步驟固定,現在的工具能穩定運作。但如果你要讓 Agent「每天監控市場動態,如果出現重大變化就自動調整我的工作計劃」,這種需要根據情境做判斷的任務,目前的穩定性仍然不夠高,中途失敗或做出錯誤判斷的機率不低。在把重要業務流程交給 AI Agent 之前,一定要有人工審核的節點,特別是在牽涉到對外溝通或資料異動的環節。
不同 AI 模型的「推理能力」,到底差在哪?外行人怎麼看懂?
推理能力這個詞被用得很氾濫,我試著用比較具體的方式說明。「推理能力強」在實際使用上的表現是:能夠追蹤多步驟的邏輯鏈而不中途出錯(例如「如果 A 成立,且 B 成立,那麼 C 會怎樣?那 D 呢?」);能夠發現問題本身的矛盾之處並指出來;在解決問題時能夠考慮「我目前遺漏了什麼條件」。外行人最容易感受到差距的方式:給模型一個有一點點陷阱的問題(例如一道故意有歧義的數學題,或者一個條件矛盾的假設情境),看它有沒有辦法發現問題本身的缺陷,還是直接給你一個自信的錯誤答案。推理能力弱的模型會直接回答;推理能力強的模型會先指出問題的矛盾或歧義。
對台灣的創業者或小公司,現在是採用 AI 工具的好時機嗎?還是技術還不夠成熟?
我的判斷是:現在是開始小規模採用特定工作流的好時機,但不是「All-in AI 全面自動化」的好時機。最值得先做的投資是找出你公司裡重複性高、規則清晰的任務(例如客服 FAQ 回覆草稿、內部文件整理、週報彙整),用 AI 工具試跑,測量實際省下的時間和錯誤率。這種小規模試點能讓你在技術繼續進化的同時,先建立使用習慣和判斷能力。最不建議的做法是:因為競業都在說用 AI 就直接全面導入,沒有配套的審核機制和人員培訓,這種方式出問題的機率很高,踩雷之後反而會對 AI 工具的整體採用產生負面影響。
我的最終判斷

2026 年的 AI 模型技術,整體呈現的樣貌是:通用能力的天花板快速拉高,但應用的邊界和限制也更清晰了。
這是個好的跡象。幾年前,AI 的問題是「大家都在吹,沒人說限制在哪」;現在,Anthropic、OpenAI、Google 的研究者越來越願意在論文裡討論模型的失敗案例,校準和安全對齊的工程投入也明顯增加。這不代表問題解決了,而是代表這個行業開始以更成熟的態度面對這些問題。
對台灣的讀者,我想留下一個具體的行動建議:選一個你最常遇到的工作痛點,花兩週認真測試一個 AI 工具,記錄它在哪裡有效、在哪裡失敗。這比讀一百篇評測文章更有價值,因為你的工作情境才是真正的基準測試。
這個領域還在快速變化,我還在觀察幾件事:推理模型(o 系列、Thinking 模式)在實際應用場景的穩定性如何進化、繁體中文的特化訓練有沒有實質推進、Agent 工具的失敗率什麼時候能降到企業可接受的水準。有新的值得報告的進展,我會更新。
AI 不是魔法,但也不是噱頭——它是一個你需要花時間學習怎麼用的工具,就像學 Excel 一樣,學懂的人和沒學的人,效率差距很真實。
最後更新:2026 年
探索更多 AI 工具
👉 查看 AI 工具評測,找到最適合你工作流程的 AI 工具。